- The paper introduces a modular Mixture-of-Transformer architecture that integrates language understanding, visual foresight generation, and action planning.
- The model achieves significant performance gains with up to 92.6% grasp rates and over 91% success in long-horizon tasks on both simulation and real-world benchmarks.
- The framework demonstrates robust generalization and interpretable planning through a three-stage training paradigm and a progressive attention mechanism.
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
Introduction and Motivation
The F1 framework addresses a central challenge in embodied AI: executing language-conditioned tasks in dynamic visual environments. Existing Vision-Language-Action (VLA) models predominantly rely on reactive state-to-action mappings, which are inherently short-sighted and lack robustness in dynamic or long-horizon scenarios. F1 introduces a paradigm shift by integrating visual foresight generation into the decision-making pipeline, enabling explicit planning and robust control.
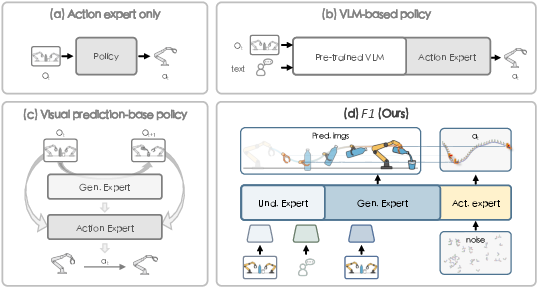
Figure 1: The comparison of varied paradigms for manipulation policies. F1 integrates understanding, generation, and execution, surpassing purely reactive and VLM-augmented policies.
Architectural Overview
F1 employs a Mixture-of-Transformer (MoT) architecture, comprising three specialized experts: understanding, generation, and action. The understanding expert encodes semantic and visual information from language instructions and current observations. The generation expert synthesizes goal-conditioned visual foresight, predicting plausible future states based on historical context. The action expert formulates a predictive inverse dynamics problem, generating action sequences that drive the agent toward the anticipated visual target.
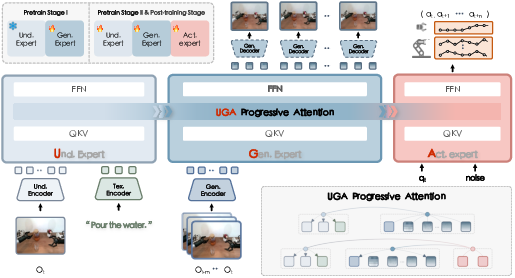
Figure 2: Overview of the F1 framework. The MoT architecture enables modular reasoning and explicit coupling of perception, foresight, and control.
The progressive attention scheme regulates information flow: intra-expert attention captures rich token interactions, while inter-expert attention enforces a causal hierarchy from understanding to foresight to action. This design ensures interpretability and stability, preventing information leakage and shortcut correlations.
Training Paradigm
F1's training recipe is a three-stage process:
- Pretrain Stage I: Aligns the generation expert with the pretrained understanding expert, injecting foresight capability.
- Pretrain Stage II: Jointly optimizes all experts on large-scale public robot datasets, acquiring foundational visuomotor knowledge.
- Post-train Stage: Adapts the model to new embodiments and fine-grained manipulation skills using task-specific demonstrations.
A next-scale prediction mechanism enables efficient foresight generation, while flow matching in continuous action space ensures principled action prediction. The overall objective is a weighted sum of generative and action losses, enforcing representational consistency and facilitating generalization.
Experimental Results
Real-World and Simulation Benchmarks
F1 is evaluated on both real-world robotic platforms and simulation benchmarks (LIBERO, SimplerEnv Bridge). It consistently outperforms mainstream VLA models (e.g., π0, gr00t-N1, SpatialVLA) in grasp and task success rates, especially in dynamic and long-horizon tasks.
Key numerical results:
- On Genie robot tasks, F1 achieves an average grasp rate of 92.6% and success rate of 82.2%, compared to π0's 78.5% and 65.2%.
- On LIBERO-Long, F1 maintains a pronounced advantage, with success rates exceeding 91% in long-horizon suites.
- In dynamic environments (e.g., ARX LIFT II), F1 achieves up to 80% success in dual-arm dynamic grasping, while baselines fall below 50%.
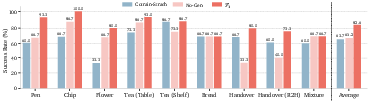
Figure 3: Ablation Studies on Real-world Tasks. Removing Pretrain Stage II or the generation expert leads to substantial performance drops, confirming their necessity.

Figure 4: Visualization of dynamic manipulation task. F1 robustly grasps specified items on a moving belt, demonstrating foresight-driven adaptation.
Ablation Studies
Systematic ablations confirm the critical role of the generation expert and pretraining. Removing the generation expert (No-Gen) or skipping Pretrain Stage II (Cotrain-Scratch) results in significant performance degradation (up to 17% drop in average success rate). Varying the planning horizon (number of foresight scales) reveals that four scales strike the optimal balance between abstraction and computational efficiency.
Robustness, Generalization, and Long-Horizon Planning
F1 demonstrates strong generalization to novel embodiments and rapid adaptation with limited demonstrations. In sequential manipulation tasks spanning ten steps and two minutes, F1 maintains high success rates across all stages, while reactive baselines fail beyond initial steps.

Figure 5: Basic Pick-and-Place Manipulation. F1 generalizes across diverse object types and containers.

Figure 6: Fine-Grained Precision Manipulation. F1 executes delicate tasks requiring precise control.

Figure 7: Dual-Arm Coordination and Handover. F1 enables bimanual and human-robot interaction tasks.

Figure 8: Dynamic Environment Adaptation. F1 tracks and manipulates moving objects in real time.

Figure 9: Long-Horizon Sequential Manipulation. F1 sustains coherent planning and execution over extended task chains.
Visual Foresight and Action Reliability
The generation expert acts as a visual planner, and its foresight quality is directly correlated with action reliability. Quantitative analysis using a multimodal evaluator (Qwen2.5-VL-32B-Instruct) shows hierarchical improvement in scene consistency, object consistency, and task progress following. Even with modest image token accuracy (~40–45%), F1 achieves high action accuracy, indicating that pixel-level fidelity is not strictly necessary for effective planning.
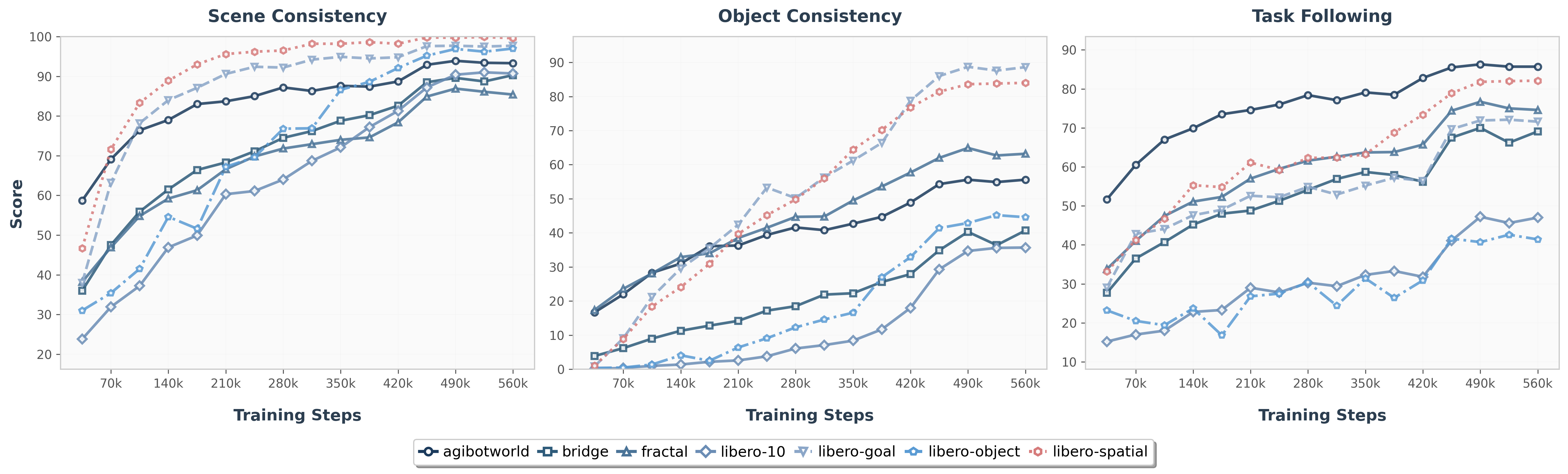
Figure 10: Generation Quality across Training Steps. Scene and task progress consistency improve steadily, supporting robust action planning.

Figure 11: Visualization of Generated Future Images. F1 predicts plausible next-step frames across diverse manipulation scenarios.
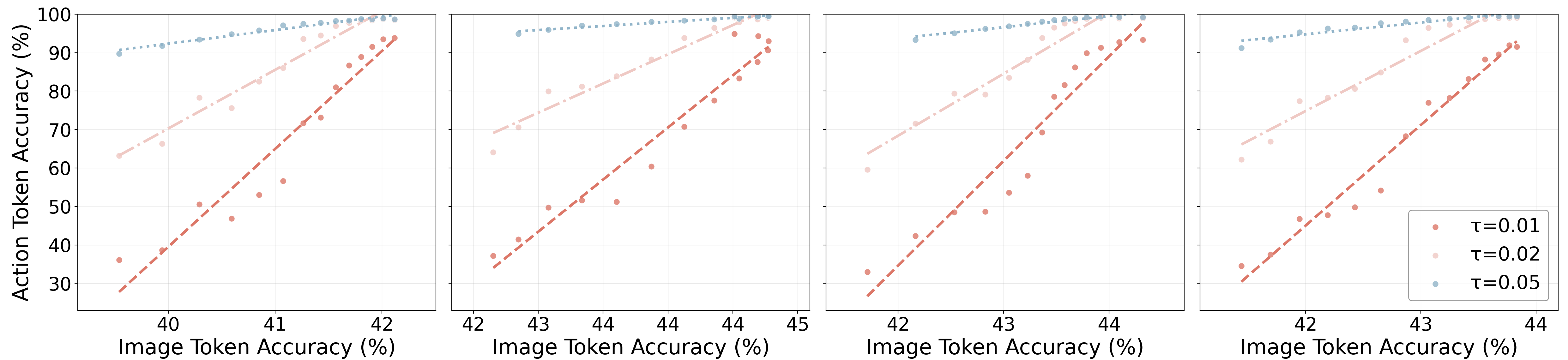
Figure 12: Correlation between Image and Action Token Accuracy. Higher foresight quality aligns with improved action prediction reliability.
Implementation and Deployment Considerations
F1 comprises 4.2B parameters and is implemented with a unified decoder-only transformer backbone. The understanding expert is initialized from a pretrained VLM (PaliGemma), while the generation and action experts use the Gemma backbone. Residual VQ-VAE enables efficient image quantization for foresight generation. Training leverages a corpus of 330k trajectories across 136 tasks, spanning multiple embodiments and viewpoints.
Deployment on an Intel i9 CPU + RTX 4090 GPU yields a total inference latency of ~235ms, suitable for real-time robotic control. Wired Ethernet connections minimize transmission delays, and foresight prediction is restricted to four scales for efficiency.
Theoretical and Practical Implications
F1 demonstrates that coupling predictive visual foresight with multimodal grounding in a unified VLA framework yields substantial gains in robustness, generalization, and long-horizon planning. The modular MoT architecture and progressive training scheme facilitate transfer across tasks and embodiments, moving beyond the limitations of reactive policies.
The explicit integration of foresight as a planning signal enables agents to anticipate and adapt to dynamic environments, supporting more reliable and interpretable control. The positive correlation between foresight quality and action reliability suggests that further advances in generative modeling can directly enhance embodied intelligence.
Future Directions
Potential avenues for future research include:
- Scaling foresight-driven policies to broader task families (locomotion, dexterous manipulation, multi-agent collaboration).
- Enriching foresight generation with structured world models or physics-informed priors for improved long-horizon reasoning.
- Integrating reinforcement learning or online adaptation to refine policies beyond imitation.
- Incorporating human feedback or interactive correction to align agent behavior with human intentions.
Conclusion
F1 establishes a new paradigm for VLA models by bridging understanding, generation, and action through explicit visual foresight and modular reasoning. Extensive empirical results validate its superiority over reactive baselines, particularly in dynamic and long-horizon tasks. The framework provides a scalable and interpretable foundation for robust visuomotor control, with clear implications for advancing embodied AI in real-world settings.

