- The paper presents OneTwoVLA, a unified model that integrates adaptive reasoning with action execution to improve task performance.
- It employs dual modes—reasoning for decision points and acting for execution—to enhance long-horizon planning and error recovery.
- Experimental results show a 30% success rate improvement over baselines in complex real-world and simulated task scenarios.
OneTwoVLA: A Unified Vision-Language-Action Model with Adaptive Reasoning
Introduction
The development of general-purpose robots capable of executing diverse tasks in unstructured environments necessitates the seamless integration of reasoning and acting capabilities. Traditional approaches, which bifurcate high-level cognitive reasoning from low-level physical execution, often face the challenge of latency and miscommunication between the separate systems. "OneTwoVLA: A Unified Vision-Language-Action Model with Adaptive Reasoning" introduces OneTwoVLA, a single unified model that synergistically handles both reasoning and acting tasks, addressing the limitations of previous separated frameworks.
OneTwoVLA employs a novel architecture capable of adaptively switching modes between reasoning and acting, thus enhancing task execution efficiency and decision-making accuracy. The model is systematically trained on a robust dataset that combines real-world robot demonstrations with large-scale, synthesized vision-language data enriched with reasoning-focused content, aiming to bolster the model’s generalization across varied scenarios.
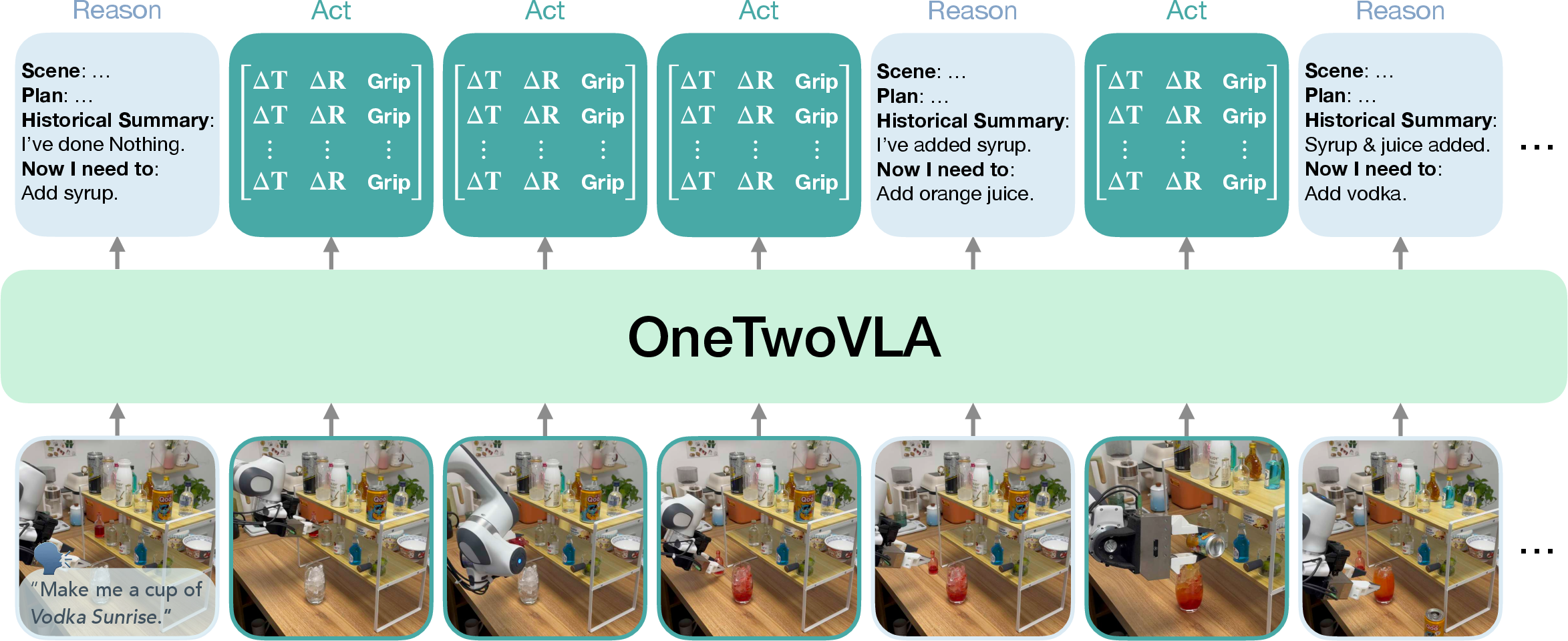
Figure 1: Overview. OneTwoVLA is a single unified vision-language-action model capable of both reasoning and acting. Crucially, OneTwoVLA can adaptively reason at critical moments during execution (e.g., upon completing subtasks, detecting errors, or requiring human inputs), while generating actions at other times.
Methodology
OneTwoVLA’s methodology is centered on its dual-mode operation: reasoning mode and acting mode. The reasoning mode is triggered at key decision points, such as when encountering errors or completing subtasks, where the model generates detailed textual reasoning outputs. Acting mode involves executing actions based on the latest reasoning, aiming for efficient task completion without unnecessary delays.
A sophisticated pipeline for data synthesis has been developed to train OneTwoVLA, featuring synthetic vision-language data that mimics intricate task environments and requirements. This pipeline includes intricate scene descriptions and task plans, enabling the model to handle long-horizon tasks and adapt to unforeseen conditions effectively.

Figure 2: Left. Example of robot data with reasoning content. The reasoning content comprises a scene description, a high-level plan, a historical summary, and the next-step instruction. Right. Examples of synthetic embodied reasoning-centric vision-language data.
Experimental Results
Through real-world and simulated experiments, OneTwoVLA has demonstrated superior capability in long-horizon task planning, error recovery, human-robot interaction, and visual grounding compared to both traditional VLA models and dual-system approaches. The model achieves an overall success rate increase of up to 30% over baseline models in complex task scenarios, attributable to its unified architecture and data-driven training approach.
In the evaluation of long-horizon tasks, OneTwoVLA consistently formulated accurate task plans and dynamically adjusted actions upon receiving execution feedback. The model exhibited exemplary performance in error detection, promptly devising and executing corrective strategies that support uninterrupted task progress.

Figure 3: Task illustrations and reasoning examples. In the three leftmost columns, we present three challenging, long-horizon manipulation tasks. Completing these tasks requires not only planning abilities but also error detection and recovery capabilities, as well as the ability to interact naturally with humans.
Discussion
OneTwoVLA’s performance underscores the potential of a unified architecture that seamlessly integrates reasoning and acting capabilities. This convergence promises reduced latency and improved adaptability, critical for deployment in real-world dynamic environments. The synthesized vision-language data play a pivotal role in enhancing the model's understanding and generalization, signifying the importance of diverse, high-quality training datasets.
Future explorations could further exploit reinforcement learning techniques to supplement supervised reasoning content, potentially advancing the model's autonomous reasoning capabilities. Moreover, the exploration of asynchronous models that allow concurrent reasoning and physical execution could further optimize OneTwoVLA's efficiency, particularly beneficial in time-sensitive applications.
Conclusion
The OneTwoVLA model sets a new standard in robotic systems by effectively merging cognitive reasoning with reactive physical capabilities. Its adaptive framework not only enhances computational efficiency but also paves the way for more intuitive and resilient human-robot collaborations. The success of OneTwoVLA highlights the importance of unified model architectures and comprehensive data ecosystems in driving the next generation of intelligent robotic systems.