- The paper introduces FlowVLA, which improves world model learning by explicitly separating motion (optical flow) and appearance prediction for more coherent outcomes.
- It employs a two-stage training approach with a unified tokenization scheme within an autoregressive transformer, ensuring efficient prediction and policy fine-tuning.
- FlowVLA achieves state-of-the-art results on robotics benchmarks, demonstrating faster convergence, robust generalization, and enhanced physical plausibility in dynamic environments.
FlowVLA: Visual Chain of Thought for World Model Learning
Introduction
FlowVLA introduces a novel paradigm for world model learning in Vision-Language-Action (VLA) systems by explicitly disentangling appearance and motion through a Visual Chain of Thought (Visual CoT) framework. The central hypothesis is that next-frame prediction, the dominant approach in VLA world models, conflates static scene understanding with dynamic reasoning, resulting in physically implausible predictions and inefficient policy learning. FlowVLA addresses this by enforcing a structured reasoning process: the model first predicts an intermediate optical flow representation (motion), then conditions on this to forecast the next visual frame (appearance). This approach is implemented within a unified autoregressive Transformer architecture, leveraging shared tokenization for both modalities.
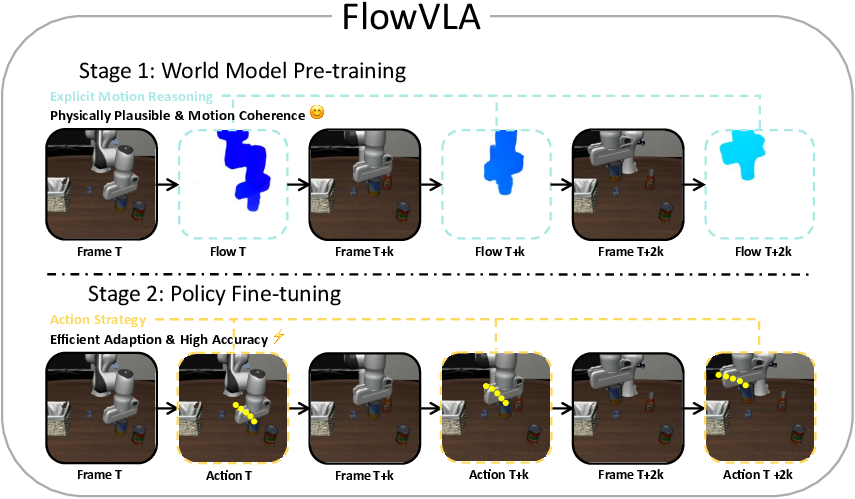
Figure 1: The FlowVLA two-stage training paradigm, illustrating world model pre-training with Visual CoT and subsequent policy fine-tuning for robot control.
FlowVLA Architecture and Training Paradigm
Two-Stage Training
FlowVLA adopts a two-stage training paradigm:
- World Model Pre-training: The model learns general physical dynamics from large-scale, action-free video data by executing the Visual CoT reasoning process.
- Policy Fine-tuning: The pre-trained world model is adapted for control, fine-tuned to generate robot actions from visual observations and language instructions.
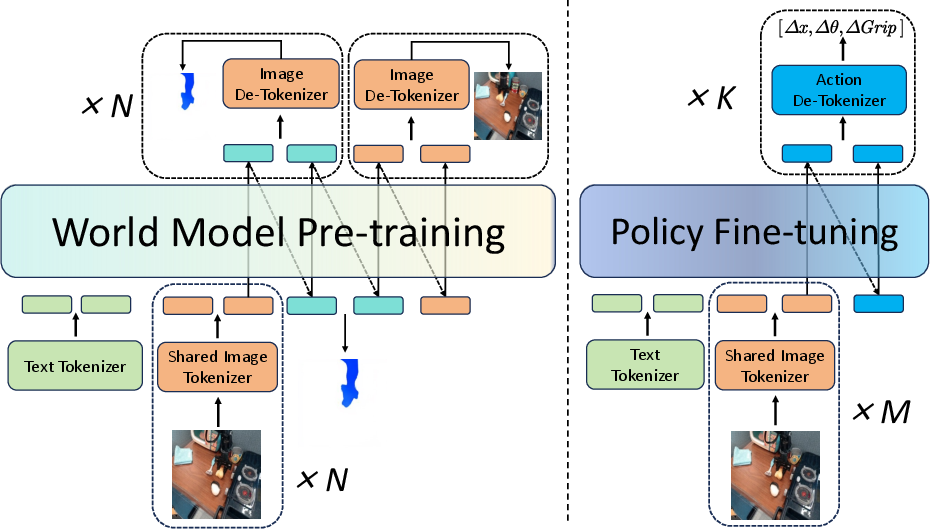
Figure 2: FlowVLA framework architecture, showing unified tokenization and interleaved prediction of appearance and motion tokens in Stage 1, and policy fine-tuning in Stage 2.
Unified Tokenization of Appearance and Motion
A key technical contribution is the unified tokenization scheme for both appearance (RGB frames) and motion (optical flow). Optical flow fields are encoded as RGB-like images using a polar coordinate mapping, allowing both modalities to be processed by a shared VQ-GAN tokenizer. This design maintains architectural simplicity and parameter efficiency, enabling the autoregressive Transformer to learn interleaved sequences of appearance and motion tokens.
Autoregressive Visual Chain of Thought
The model is trained to predict sequences of the form vt→ft→vt+1, where vt is the current frame, ft is the predicted optical flow, and vt+1 is the next frame. The training objective is a sum of cross-entropy losses over both flow and frame tokens, enforcing explicit reasoning about dynamics before appearance prediction.
Experimental Results
Robotics Benchmarks
FlowVLA is evaluated on LIBERO and SimplerEnv, two challenging robotics manipulation benchmarks. On LIBERO, FlowVLA achieves state-of-the-art success rates across all suites, with the most pronounced gains on long-horizon tasks, indicating superior physical reasoning and planning capabilities. On SimplerEnv, which introduces significant visual domain shifts, FlowVLA demonstrates robust generalization, outperforming prior models by a substantial margin.
World Modeling Capabilities
Qualitative analysis on the Bridge V2 dataset reveals that standard next-frame prediction baselines suffer from two critical failure modes: physical implausibility (e.g., disappearing manipulators, erratic object motion) and semantic misalignment (predicted actions not matching language instructions). FlowVLA, by reasoning about motion first, produces physically coherent and semantically aligned predictions.

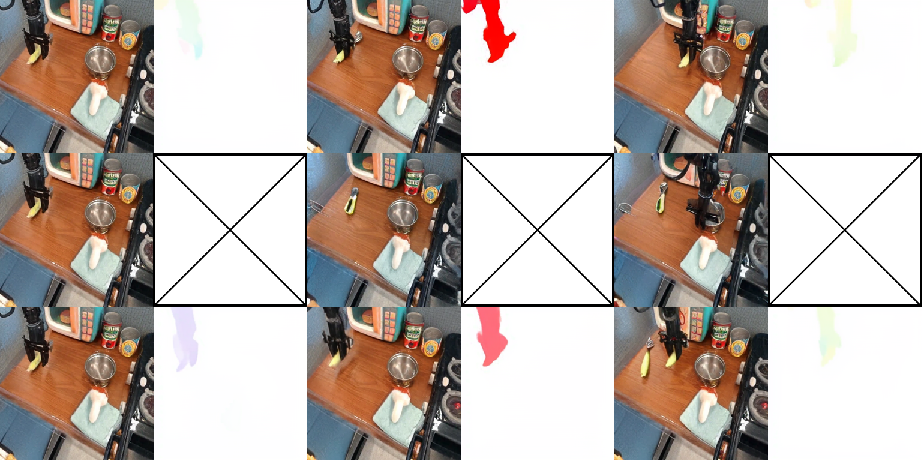
Figure 3: Example of FlowVLA maintaining physical plausibility in the task "Put the rectangular on top of the rectangular block next to it."
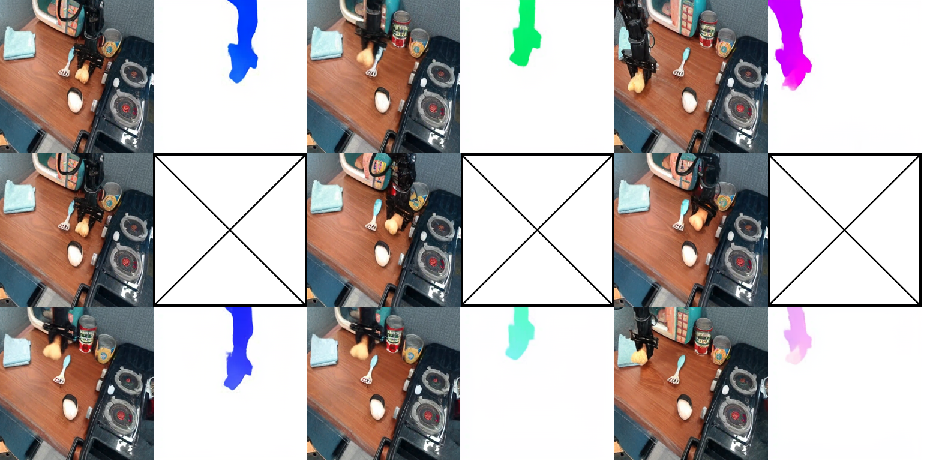
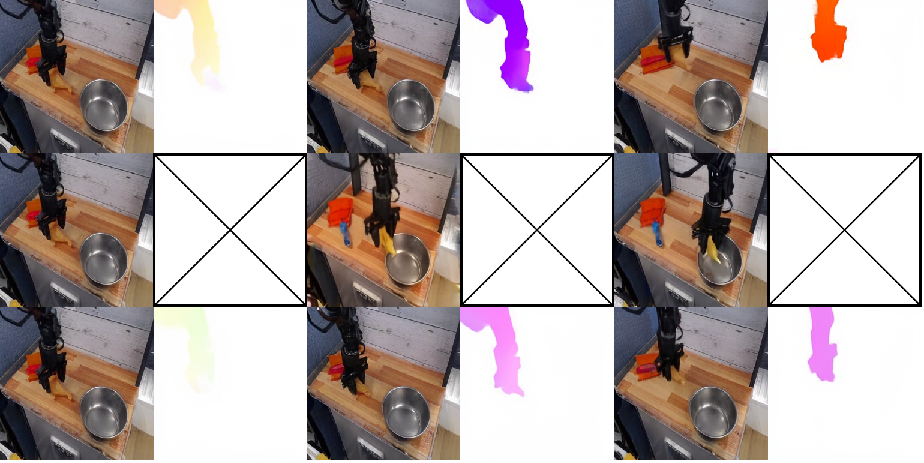
Figure 4: Example of FlowVLA achieving semantic alignment in the task "Put the toy into left of table."
Convergence Speed and Sample Efficiency
FlowVLA exhibits dramatically improved sample efficiency during policy fine-tuning. In both full and low-data regimes, FlowVLA converges faster and achieves higher peak performance compared to baselines. The efficiency gap widens under data scarcity, validating the inductive bias introduced by explicit motion reasoning.
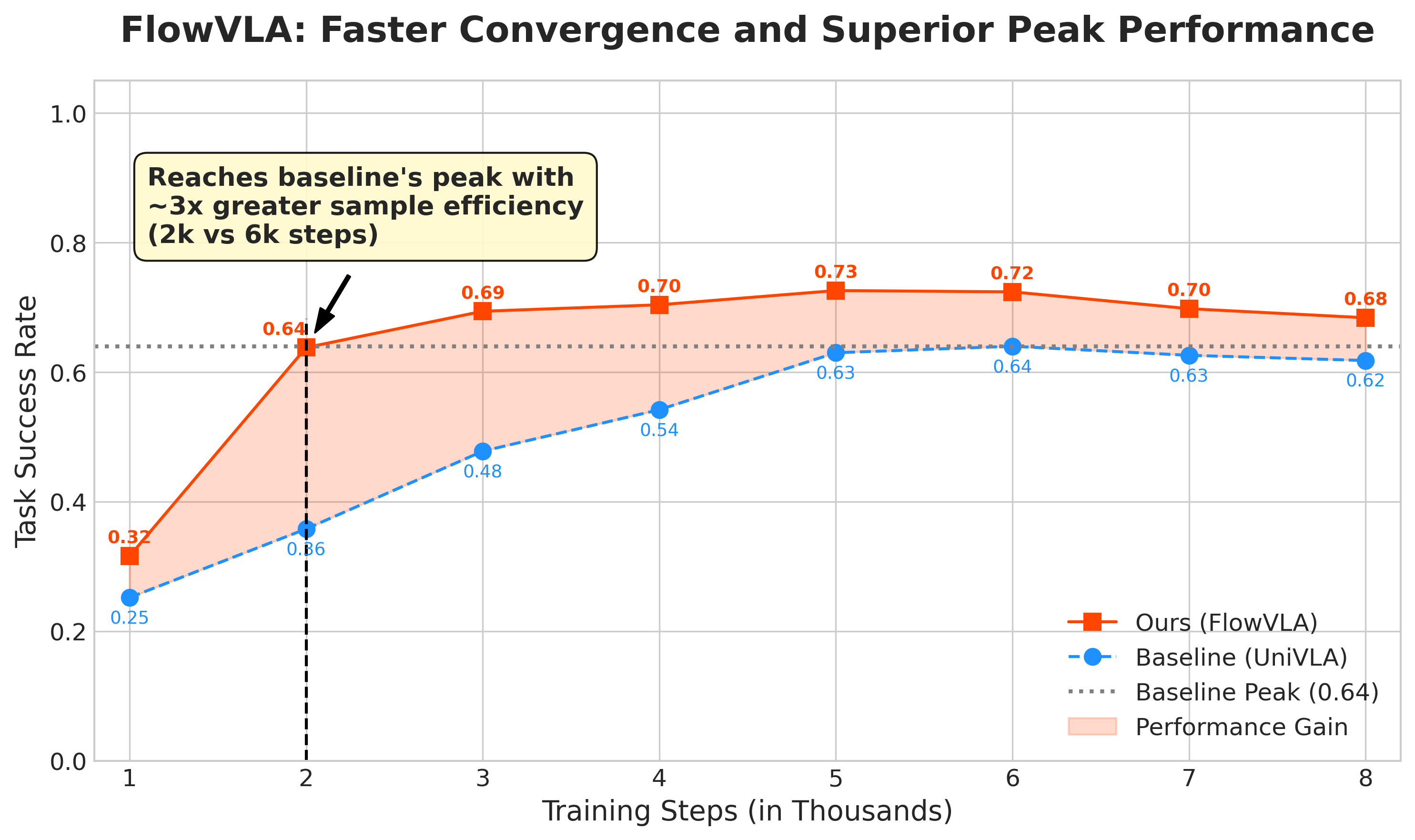
Figure 5: Training efficiency comparison, showing FlowVLA's superior convergence speed and final success rate when trained on 100% of data.
Ablation Studies
Ablation experiments confirm the necessity of the Visual CoT structure, direct supervision of the flow prediction, and the interleaved sequence format. Removing any of these components leads to significant drops in success rate, with the interleaved causal chain (vt→ft→vt+1) being essential for effective planning and action generation.
Theoretical and Practical Implications
FlowVLA's explicit separation of appearance and motion learning addresses a fundamental limitation in world model design for robotics. By enforcing a reasoning-first approach, the model acquires a more causally grounded understanding of physical dynamics, which translates to improved long-horizon prediction, robust generalization, and efficient policy adaptation. The unified tokenization and autoregressive architecture facilitate scalable training and deployment without introducing modality-specific components.
Practically, FlowVLA's sample efficiency and robustness to domain shifts make it well-suited for real-world robotic applications, where data collection is expensive and environments are variable. The framework also provides a foundation for integrating low-level physical reasoning with higher-level semantic and geometric planning, potentially enabling more capable and generalist embodied agents.
Future Directions
Potential future developments include:
- Extending the Visual CoT framework to incorporate additional intermediate representations (e.g., depth, contact maps) for richer physical reasoning.
- Integrating FlowVLA with hierarchical planning systems that combine pixel-level dynamics with abstract task decomposition.
- Exploring transfer learning and continual adaptation in open-ended environments, leveraging the model's robust world understanding.
- Investigating the limits of unified tokenization for multimodal reasoning beyond vision and motion, such as tactile or auditory signals.
Conclusion
FlowVLA establishes Visual Chain of Thought as a principled approach for world model learning in VLA systems. By decomposing prediction into motion and appearance, FlowVLA achieves coherent dynamics, state-of-the-art performance, and improved sample efficiency. The results underscore the importance of explicit motion reasoning for bridging perception and control, with significant implications for the design of generalist robotic agents.