- The paper presents a modular full-duplex voice interaction system integrating both cascaded and semi-cascaded architectures for controlled, low-latency performance.
- It introduces a streaming personalized VAD and semantic end-of-turn detection via fine-tuned BERT to accurately manage turn-taking and minimize false interruptions.
- Empirical results demonstrate significant improvements in barge-in accuracy, detection precision, and end-to-end latency, offering promising implications for conversational AI.
FireRedChat: A Modular, Full-Duplex Voice Interaction System with Cascaded and Semi-Cascaded Architectures
Introduction
FireRedChat addresses the challenge of enabling robust, natural, and low-latency full-duplex voice interaction in AI assistants and conversational agents. The system is designed as a modular, pluggable framework that supports both cascaded and semi-cascaded pipelines, integrating a dedicated turn-taking controller, interaction module, and dialogue manager. The architecture emphasizes controllability, extensibility, and the ability to leverage both lexical and paralinguistic cues for improved conversational quality. This essay provides a technical analysis of the system's design, implementation, and empirical performance, with a focus on its contributions to full-duplex voice interaction.
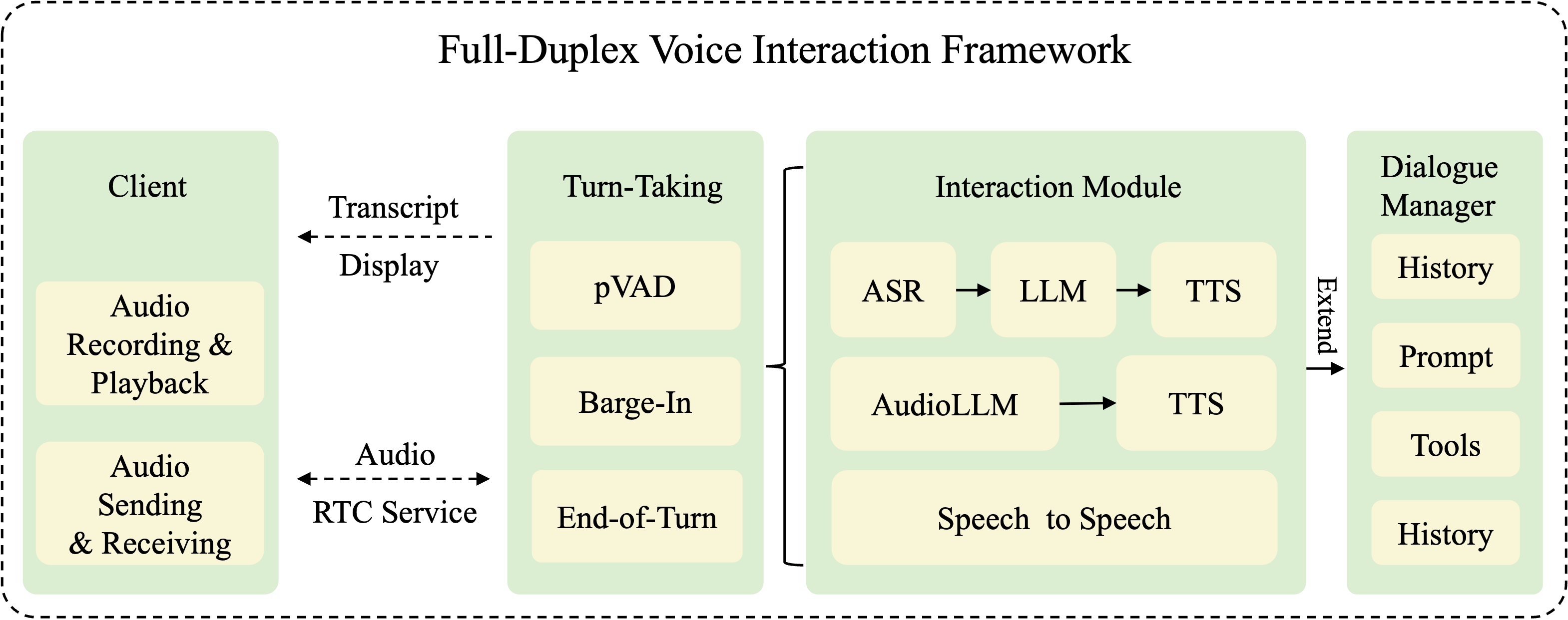
Figure 1: FireRedChat system modules, illustrating the modular architecture with turn-taking controller, interaction module, and dialogue manager.
System Architecture and Workflow
FireRedChat's architecture is organized into three principal modules: the turn-taking controller, the interaction module, and the dialogue manager. The system is designed to be agnostic to the underlying interaction pipeline, supporting cascaded, semi-cascaded, and speech-to-speech configurations.
The turn-taking controller is responsible for managing conversational flow, including barge-in handling and end-of-turn (EoT) detection. The interaction module processes user input and generates system responses, while the dialogue manager orchestrates tool invocation and context management.
The workflow proceeds as follows: user speech is transmitted via RTC and analyzed by a streaming personalized VAD (pVAD) to suppress noise and non-primary speakers, yielding precise timestamps for the primary speaker. The system immediately suspends TTS playback upon detecting a barge-in, enabling full-duplex interaction. The original, non-denoised audio is then processed by the ASR or AudioLLM, followed by semantic EoT detection. The dialogue manager may invoke external tools as needed, and the response is synthesized by the TTS module.
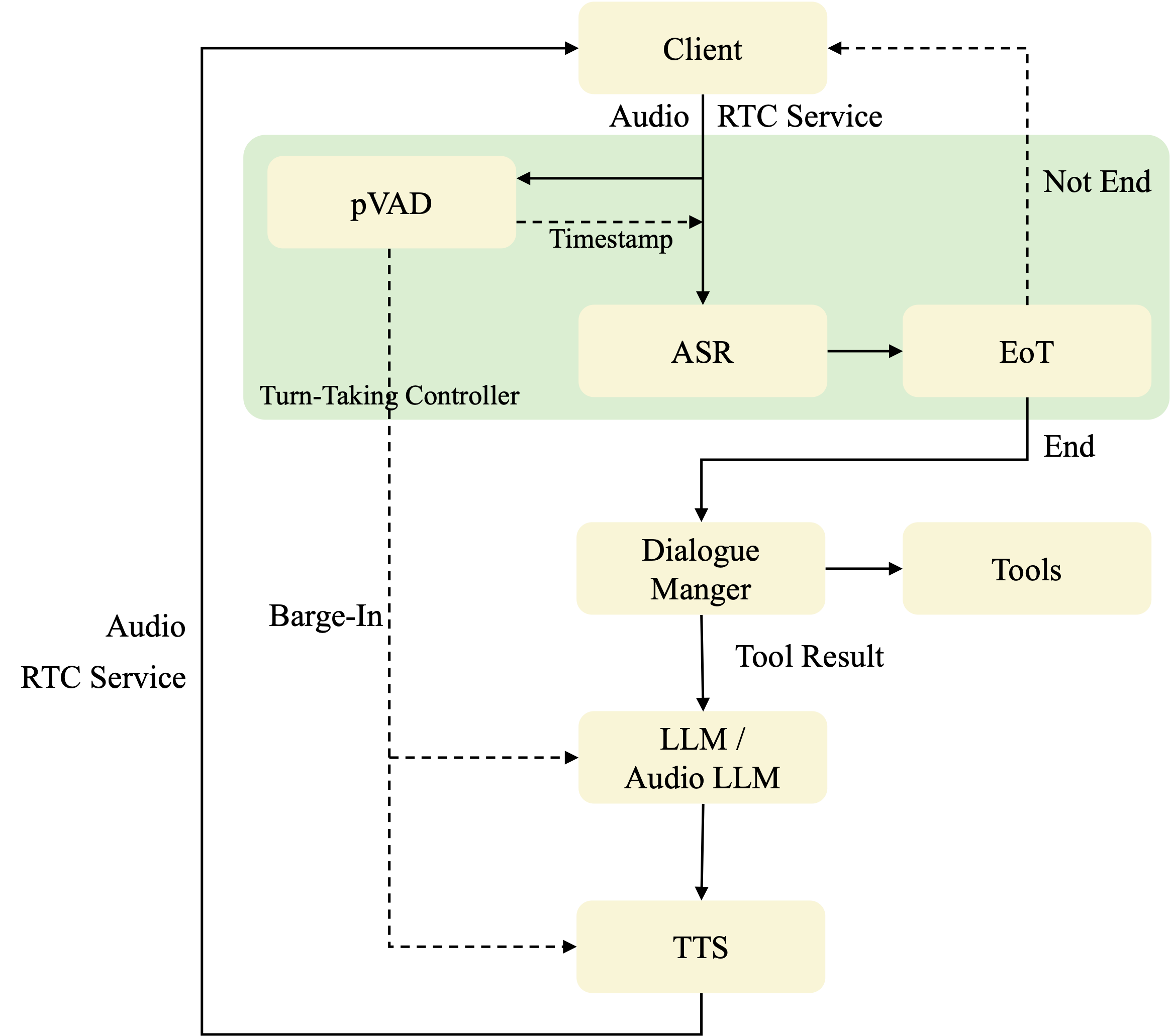
Figure 2: FireRedChat voice interaction flow, detailing the sequence from user speech input to system response with barge-in and EoT control.
Turn-Taking Controller: Streaming Personalized VAD and End-of-Turn Detection
Streaming Personalized VAD
The pVAD module is a key innovation, designed to robustly distinguish the primary speaker from background noise and competing speakers. It employs causal convolutional layers for streaming inference, concatenates a target-speaker embedding (extracted via ECAPA-TDNN) with mel-spectrogram features, and models temporal dependencies with a GRU. The classifier outputs speaking probabilities at 10 ms resolution.
Training data comprises 2000 hours of clean Mandarin and English speech, with mixtures constructed by combining target and interfering speakers or noise at varying SNRs. The pVAD operates in real time, enabling prompt barge-in detection and minimizing false interruptions.
End-of-Turn Detection
The EoT module addresses the challenge of semantic turn completion in speech-based interaction. It is implemented as a classifier fine-tuned on top of a pre-trained multilingual BERT, trained to distinguish between partial (unfinished) and complete (finished) utterances using a corpus of 830,000 text instances. This enables the system to make semantic-level stop decisions, improving conversational naturalness and reducing premature truncation.
Interaction Module: Cascaded and Semi-Cascaded Implementations
Cascaded Pipeline
The cascaded configuration utilizes FireRedASR for speech recognition, Qwen2.5 as the LLM, and FireRedTTS-1s for speech synthesis. This approach benefits from established deployment practices and allows independent optimization of each component. Streaming decoding in both ASR and TTS reduces end-to-end latency.
Semi-Cascaded Pipeline
The semi-cascaded pipeline replaces the ASR+LLM stages with an AudioLLM, which directly consumes user speech and produces a textual response. FireRedTTS-2 then synthesizes the response, conditioning on the user's input audio for paralinguistic consistency. This design offers several advantages:
- Paralinguistic Awareness: Both AudioLLM and FireRedTTS-2 can perceive and utilize emotional and acoustic cues, enabling more contextually appropriate and natural responses.
- Reduced Error Propagation: Joint modeling of acoustic and linguistic information mitigates ASR error cascades.
- Audio Understanding: The system can recognize non-lexical audio events, supporting richer interaction scenarios.
- Lower Latency: The pipeline is simplified, reducing processing steps and potential bottlenecks.
- Consistent Synthesis: Conditioning TTS on user speech ensures emotional and stylistic coherence in responses.
AudioLLM is trained from scratch following the Qwen2-Audio architecture, with large-scale data spanning ASR, emotion recognition, acoustic scene classification, and dialog-style synthesis. FireRedTTS-2 is trained on 1.1M hours of single-sentence speech and 300k hours of dialog data, with fine-tuning for signature timbres.
The dialogue manager, integrated via Dify, supports tool invocation and context management. It enables the system to extend its capabilities beyond open-domain conversation, such as web search or task execution, and ensures that tool outputs are appropriately integrated into the response generation process.
Empirical Evaluation
FireRedChat is evaluated on three system-level metrics: barge-in handling, end-of-turn detection, and end-to-end latency.
- Barge-In: The system achieves a T90 (minimum latency to 90% barge-in accuracy) of 170 ms and a false barge-in rate of 10.2%. This is a significant reduction in false interruptions compared to LiveKit (33.4%) and Ten (78.1%), with only a modest increase in T90, representing a favorable trade-off between responsiveness and robustness.
- End-of-Turn Detection: FireRedChat achieves 96.0% (Chinese) and 94.9% (English) average EoT detection accuracy with a 170M parameter model, outperforming LiveKit and matching the much larger Ten (7B) model.
- Latency: The system achieves P50 and P95 latencies of 2.341 s and 3.015 s, respectively, outperforming open-source frameworks and approaching the performance of industrial systems such as DouBao.
Implications and Future Directions
FireRedChat demonstrates that a modular, pluggable architecture with dedicated turn-taking control can deliver robust, low-latency, and natural full-duplex voice interaction. The integration of streaming personalized VAD and semantic EoT detection enables precise control over conversational flow, while the semi-cascaded pipeline leverages paralinguistic cues for improved response quality.
The empirical results highlight the importance of target-speaker conditioning and semantic-level turn detection in minimizing false interruptions and enhancing user experience. The system's modularity facilitates independent optimization and rapid integration of new models or capabilities.
Future developments may focus on further reducing latency through more aggressive streaming in ASR and TTS, expanding paralinguistic conditioning in synthesis, and extending the system to support multilingual and multimodal interaction. The architecture is well-suited for integration with emerging end-to-end speech-to-speech models, provided that controllability and modularity are preserved.
Conclusion
FireRedChat provides a comprehensive, modular solution for full-duplex voice interaction, combining robust turn-taking control, flexible pipeline integration, and advanced paralinguistic modeling. The system achieves strong empirical performance in barge-in handling, end-of-turn detection, and latency, narrowing the gap with industrial-grade applications. Its design principles and empirical findings offer valuable guidance for the development of future conversational AI systems with lifelike, real-time interaction capabilities.