OmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation
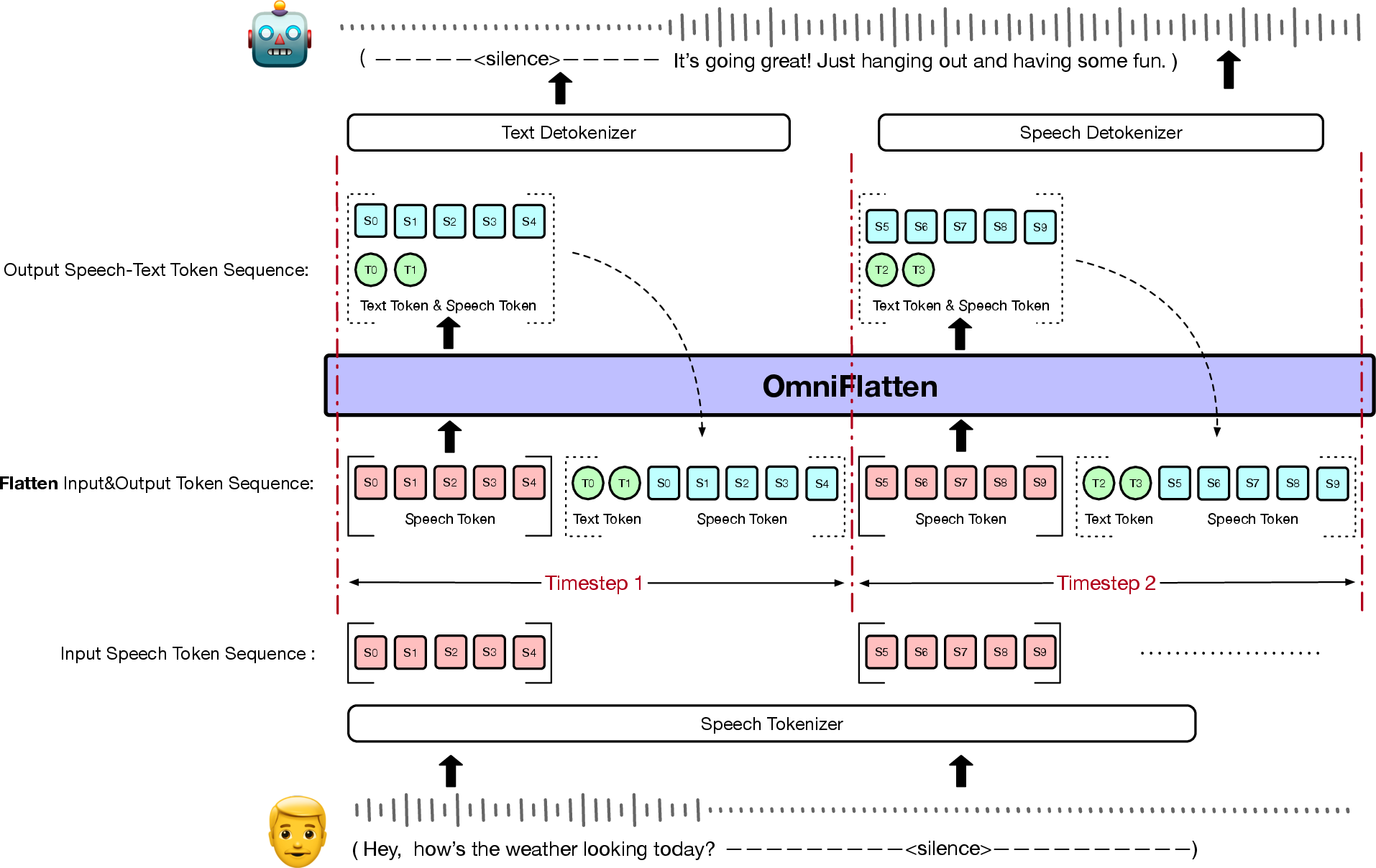
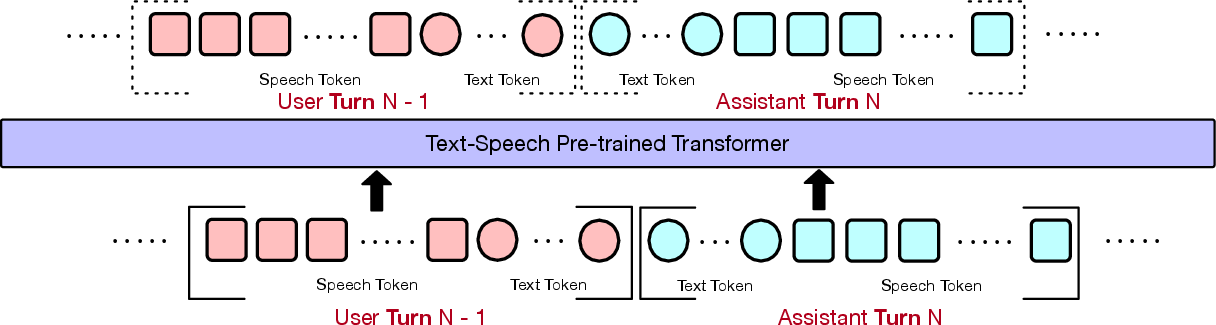
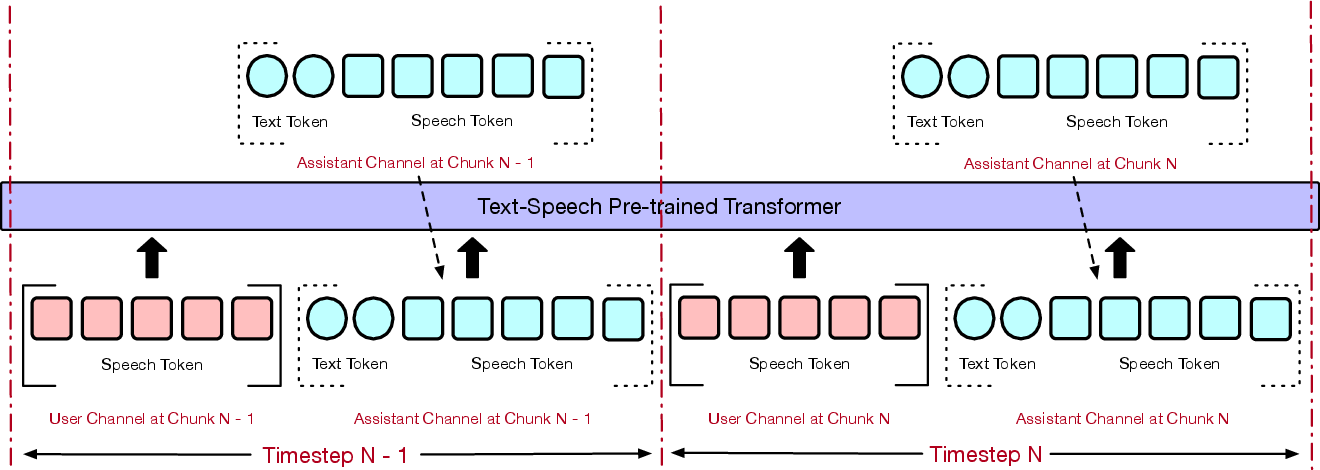
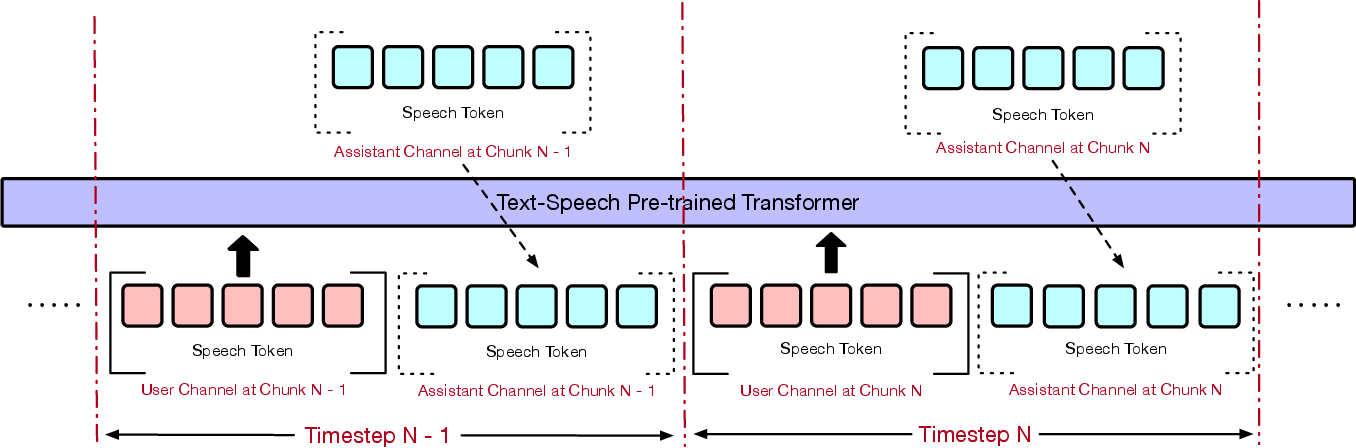
Abstract: Full-duplex spoken dialogue systems significantly surpass traditional turn-based dialogue systems, as they allow simultaneous bidirectional communication, closely mirroring human-human interactions. However, achieving low latency and natural interactions in full-duplex dialogue systems remains a significant challenge, especially considering human conversation dynamics such as interruptions, backchannels, and overlapping speech. In this paper, we introduce a novel End-to-End GPT-based model OmniFlatten for full-duplex conversation, capable of effectively modeling the complex behaviors inherent to natural conversations with low latency. To achieve full-duplex conversation capabilities, we propose a multi-stage post-training scheme that progressively adapts a text LLM backbone into a speech-text dialogue LLM, capable of generating text and speech in real time, without modifying the architecture of the backbone LLM. The training process comprises three stages: modality alignment, half-duplex dialogue learning, and full-duplex dialogue learning. In all training stages, we standardize the data using a flattening operation, which enables unifying the training methods and the GPT backbone across different modalities and tasks. Our approach offers a simple modeling technique and a promising research direction for developing efficient and natural end-to-end full-duplex spoken dialogue systems. Audio samples of dialogues generated by OmniFlatten can be found at this web site (https://omniflatten.github.io/).
- Funaudiollm: Voice understanding and generation foundation models for natural interaction between humans and llms.
- Qwen2-audio technical report.
- Moshi: a speech-text foundation model for real-time dialogue. Technical report, Kyutai.
- Enhancing chat language models by scaling high-quality instructional conversations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 3029–3051. Association for Computational Linguistics.
- Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens.
- Lauragpt: Listen, attend, understand, and regenerate audio with gpt.
- Llama-omni: Seamless speech interaction with large language models.
- Vita: Towards open-source interactive omni multimodal llm.
- TED-LIUM 3: Twice as much data and corpus repartition for experiments on speaker adaptation. In Speech and Computer - 20th International Conference, SPECOM 2018, Leipzig, Germany, September 18-22, 2018, Proceedings, volume 11096 of Lecture Notes in Computer Science, pages 198–208. Springer.
- Towards better instruction following language models for chinese: Investigating the impact of training data and evaluation.
- Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. In NeurIPS.
- Flow matching for generative modeling. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Librispeech: An asr corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5206–5210.
- Instruction tuning with GPT-4. CoRR, abs/2304.03277.
- Mls: A large-scale multilingual dataset for speech research. ArXiv, abs/2012.03411.
- Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pages 28492–28518. PMLR.
- MUSAN: A Music, Speech, and Noise Corpus. ArXiv:1510.08484v1.
- Moss: An open conversational large language model. Machine Intelligence Research, 21(5):888–905.
- Salmonn: Towards generic hearing abilities for large language models.
- Improving and generalizing flow-based generative models with minibatch optimal transport. Trans. Mach. Learn. Res., 2024.
- Beyond turn-based interfaces: Synchronous llms as full-duplex dialogue agents.
- Voxpopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pages 993–1003. Association for Computational Linguistics.
- Zhifei Xie and Changqiao Wu. 2024. Mini-omni: Language models can hear, talk while thinking in streaming.
- Qwen2 technical report.
- Xin Xu Shaoji Zhang Ming Li Yao Shi, Hui Bu. 2015. Aishell-3: A multi-speaker mandarin tts corpus and the baselines.
- Libritts: A corpus derived from librispeech for text-to-speech. In 20th Annual Conference of the International Speech Communication Association, Interspeech 2019, Graz, Austria, September 15-19, 2019, pages 1526–1530. ISCA.
- Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition. In International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE.
- Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities.
- Judging llm-as-a-judge with mt-bench and chatbot arena. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023.
- 3d-speaker: A large-scale multi-device, multi-distance, and multi-dialect corpus for speech representation disentanglement.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.