- The paper introduces a novel architecture integrating a streaming speech encoder, LLM backbone, and speech synthesizer for efficient full-duplex speech processing.
- The model employs a unique codec-free integration and dynamic thinking strategy to enable smooth turn-taking and backchanneling in natural conversations.
- Reinforcement learning enhancements yield a 35.9% performance boost in turn-taking and dialogue accuracy, demonstrating improved conversational fluidity.
SALMONN-omni: A Standalone Speech LLM for Full-duplex Conversation
Introduction and Background
SALMONN-omni introduces a novel method for full-duplex speech interaction without the need for codec injection in its token space. It operates as a standalone model capable of simultaneously processing speech input and output, significantly improving conversational AI's fluidity and responsiveness. Traditional duplex systems, using modular architectures, suffer from performance degradation and error accumulation due to the necessity of auxiliary components like voice activity detectors and dialogue controllers. Conversely, SALMONN-omni achieves superior performance by leveraging a new dynamic thinking mechanism that facilitates transitions between listening and speaking states.
The model's innovations lie in integrating a streaming speech encoder, an LLM backbone devoid of codec tokens, and a speech synthesizer. This architecture enhances interaction by interleaving speech and textual embeddings into the LLM, achieving seamless state transitions necessary for natural conversation dynamics like turn-taking and backchanneling.
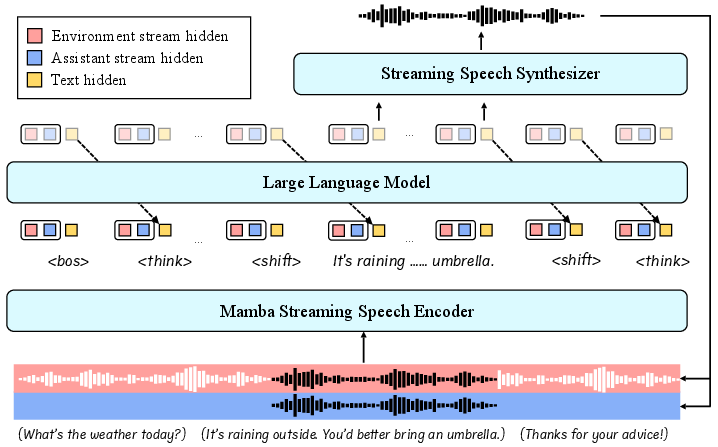
Figure 1: The architecture of SALMONN-omni. Two input streams, the environment stream and the assistant stream, are processed by the streaming speech encoder.
Methodology
SALMONN-omni employs a comprehensive methodology encompassing several core innovations:
- Codec-free Streaming Integration: The streaming speech encoder enables SALMONN-omni to handle long-sequence conversational contexts while fine-tuning embeddings through log-Mel filter bank features fed into Mamba LLM blocks. This approach omits codec tokens, thus preserving the LLM's text-based functionality and avoiding modality gaps.
- Full-duplex Processing: A unified stream sequence composed of environment and assistant speech streams is interleaved into the model's processing pipeline. SALMONN-omni accommodates the environmental audio stream while generating assistant responses, effectively managing real-time echo-related challenges through continuous interleaving of input-output dynamics.
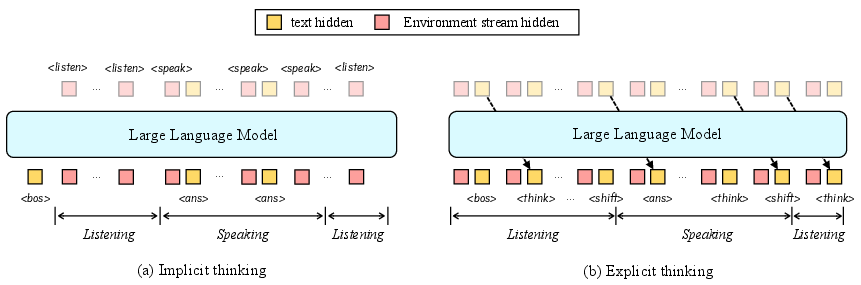
Figure 2: Illustration of "Implicit" and "Explicit" thinking strategies. The tokens on the top of the LLM are predicted by speech embeddings, while the bottom ones are predicted by textual embeddings.
- Thinking Strategy for State Transitions: An exclusive explicit "thinking" strategy is employed to ensure state transitions occur correctly. State changes (e.g., listening to speaking) are dictated by special tokens correlating with natural language processing, creating an internally responsive system.
- Three-stage Training Regime: The training methodology introduces a systematic, staged protocol to solidify connections between model components and optimize performance using reinforcement learning adjustments to ensure the LLM can appropriately manage dialogue interruptions.
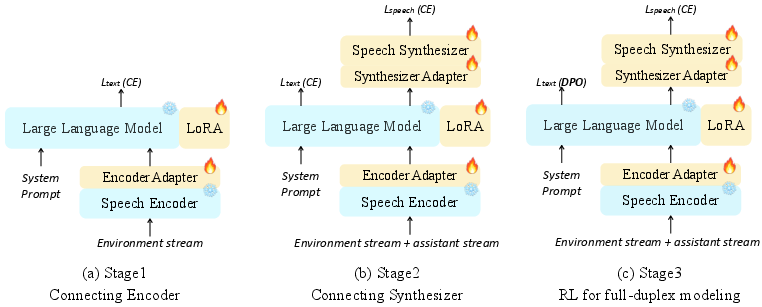
Figure 3: Three-stage training strategy for SALMONN-omni.
Experimental Evaluation
SALMONN-omni demonstrates substantial improvements over existing models in both full-duplex and half-duplex scenarios. In key evaluations like spoken QA and open-domain dialogue, it achieves a 35.9% relative performance increase against alternative duplex models.
- Turn-Taking Success: Achieving a consistent high rate of success in predicting turn-taking moments showcases the model's adeptness at conversational flow management.
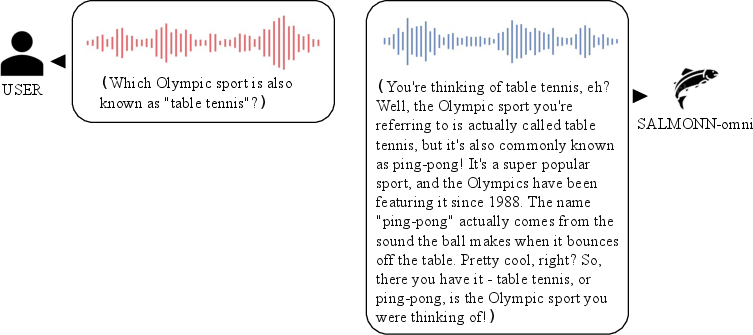
Figure 4: Spoken QA: SALMONN-omni can handle turn-taking in spoken question answering scenarios with "thinking" mechanism.
- Barge-in and Backchanneling: Contextual tests highlight the model’s ability to discern between user interruptions and conversational cues, significantly improving user interaction quality.

Figure 5: Open-domain dialogue: SALMONN-omni can handle turn-taking in spoken question answering scenarios with "thinking" mechanism.
- Reinforcement Learning Enhancements: Applying reinforcement learning to improve interaction modeling has shown to reduce interruption tendencies, refining overall dialogue engagement dynamics.
Conclusion
SALMONN-omni represents a significant advancement in the development of full-duplex conversational AI systems. Through its novel architecture and methodological advancements, it efficiently addresses the challenges of natural human-like interaction without reliance on audio codec injections, offering promising directions for future AI research in standalone speech models. Its robust performance and innovative training protocols support further exploration into dynamic, real-time conversational capabilities, solidifying SALMONN-omni as a pivotal development in full-duplex AI technologies.

