- The paper introduces a weakly-supervised framework leveraging vision-language models to generate dense functional correspondences across object categories.
- It employs a novel combination of functional and spatial contrastive losses, ensuring semantic alignment and structural consistency in correspondences.
- Experimental results show superior performance over traditional keypoint methods, enabling accurate pixel-level mapping in both synthetic and real-world datasets.
Weakly-Supervised Learning of Dense Functional Correspondences
Introduction and Motivation
The paper addresses the problem of establishing dense pixel-level correspondences between object instances based on functional similarity, particularly across different object categories. This is a critical capability for applications such as shape reconstruction, robotic manipulation, and imitation learning, where transferring knowledge or actions between objects with similar functions but disparate appearances is required. The central challenge is that functionally similar parts may be visually dissimilar, necessitating both semantic and structural reasoning to identify and align these regions.

Figure 1: Dense functional correspondence requires both semantic and structural understanding to align functionally similar parts across visually distinct objects.
The authors formalize dense functional correspondence as the mapping between pixels of functionally equivalent parts of two objects, such that the corresponding surface points are spatially close in 3D when the objects are aligned for a given function. This is operationalized by leveraging 3D object assets and defining correspondences via 3D alignment of functional parts, followed by projection to 2D image space.

Figure 2: Ground-truth dense correspondences are derived by aligning functional parts in 3D and projecting to 2D, enabling large-scale evaluation without manual annotation.
To support both training and evaluation, the paper introduces two datasets:
- Synthetic Evaluation Dataset: 950 pairs of Objaverse assets, spanning 24 functions, with 1,800+ rendered image pairs and dense ground-truth correspondences.
- Real Evaluation Dataset: 190 pairs from the HANDAL dataset, covering 13 functions, with 500+ real image pairs and ground-truth correspondences.
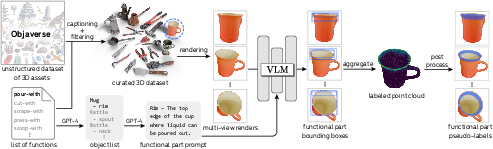
Weakly-Supervised Data Curation via Vision-LLMs
A key contribution is the scalable curation of pseudo-labeled training data using vision-LLMs (VLMs). The pipeline involves:
This approach enables the generation of a large, diverse dataset of functional part segmentations, facilitating weakly-supervised learning without expensive manual annotation.
Model Architecture and Training Objectives
The proposed model builds on frozen DINOv2 and CLIP backbones, extracting local image features and conditioning them on function text embeddings. A 3-layer MLP processes the concatenated features to produce function-conditioned pixel embeddings. Optionally, an additional layer predicts functional part masks.
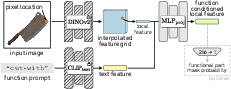
Figure 4: Local functional feature extraction via an MLP conditioned on both spatial and functional information.
Training employs a combination of contrastive objectives:
Implementation uses DINOv2-B as backbone, 224×224 images, 3-layer MLPs with 1024 hidden units, Adam optimizer, and batch sizes of 50 image pairs. Hyperparameters for loss weights are tuned via sensitivity analysis.
Experimental Results
Quantitative evaluation demonstrates that the proposed model, trained solely on synthetic data, generalizes effectively to real images. The model consistently outperforms baselines including self-supervised features (DINOv2, Stable Diffusion), VLM-based grounding (CogVLM, ManipVQA), and their combinations. Notably, the model achieves superior performance in both label transfer and correspondence discovery tasks, especially for cross-category pairs, where self-supervised features struggle.

Figure 6: The proposed method retrieves functionally relevant correspondences with higher precision than DINOv2, particularly in cross-category scenarios.
Ablation studies reveal that:
- Functional loss alone is insufficient; spatial loss is necessary to avoid feature collapse.
- Mask loss provides marginal gains, particularly in unconstrained real-world settings.
- Larger ViT backbones and reduced stride sizes improve performance, albeit with increased computational cost.
Qualitative results further illustrate the model's ability to focus on functionally relevant regions and maintain fine-grained structural alignment, even between objects with significant visual differences.
Comparison with Prior Work
The approach contrasts with keypoint-based methods such as FunKPoint [lai2021functional], which rely on sparse, manually defined keypoints and are limited in capturing nuanced part-level correspondences across categories. The dense formulation here enables higher precision and scalability, with minimal human input.

Figure 7: Visual comparison with FunKPoint [lai2021functional] highlights the increased granularity and precision of dense correspondences.
Limitations and Future Directions
The method faces challenges in cases of ambiguity, such as objects with multiple functionally relevant parts or radially symmetric regions. Addressing these may require probabilistic modeling or additional conditioning. The reliance on segmentation assumes object masks are available, which may not hold in all real-world scenarios.
Potential future directions include:
- Extending to multi-modal or probabilistic correspondence prediction.
- Integrating with robotic manipulation pipelines for demonstration transfer.
- Scaling to larger, more diverse datasets via improved pseudo-labeling.
Conclusion
This work introduces a principled, weakly-supervised framework for learning dense functional correspondences across object categories. By distilling semantic knowledge from VLMs and structural priors from self-supervised features, the model achieves state-of-the-art performance in both synthetic and real-world benchmarks. The approach is highly scalable and generalizes well, providing a foundation for advanced object understanding and manipulation in vision and robotics.