- The paper demonstrates that probing classifiers rely on superficial patterns like trigger words rather than true semantic understanding.
- Experiments reveal that while in-distribution accuracy exceeds 98%, performance drops dramatically by up to 99 percentage points in out-of-distribution scenarios.
- The study suggests a paradigm shift toward deeper semantic analysis to enhance the robustness of safety detection in LLMs.
Introduction
The research investigates the efficacy and limitations of probing-based mechanisms for malicious input detection in LLMs. Probing classifiers—lightweight models trained on hidden states of LLMs—have been considered effective for distinguishing between benign and malicious inputs based on internal representations. However, this analysis challenges the robustness and generalizability of these methods, particularly under out-of-distribution (OOD) conditions.
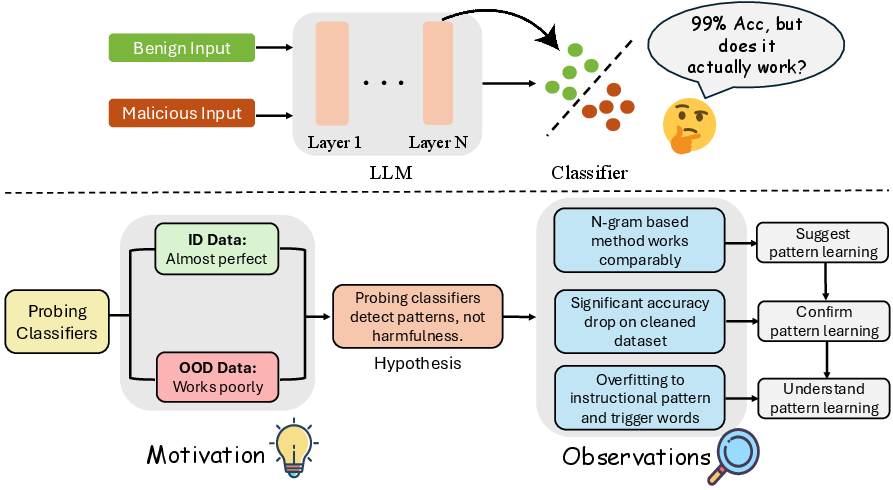
Figure 1: Overview of the research methodology. Motivated by the poor performance of probing classifiers on out-of-distribution (OOD) data, this study hypothesizes that they learn superficial patterns instead of semantic harmfulness.
Hypothesis and Methodology
The primary hypothesis posited in this study is that probing classifiers learn superficial patterns, such as instructional patterns and trigger words, rather than genuinely understanding semantic harmfulness. To validate this, the study conducted several controlled experiments:
- Comparison with Simple Statistical Models: Probing classifiers were benchmarked against n-gram based Naive Bayes models. Both approaches achieved similar performance levels, suggesting that probing classifiers primarily rely on surface-level patterns.
- Testing on Semantically Cleaned Datasets: By replacing malicious content with benign counterparts while preserving structural patterns, the study investigated probing classifiers' reliance on superficial pattern matching. The significant performance drop on these datasets further confirmed the pattern-learning hypothesis.
- Analysis of Instructional Patterns and Trigger Words: Detailed experiments revealed that probing classifiers depend heavily on lexical cues and structural formatting, which influences their decision-making process.
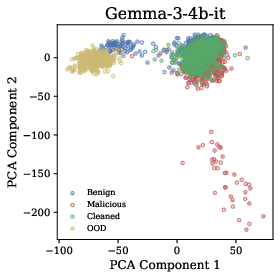
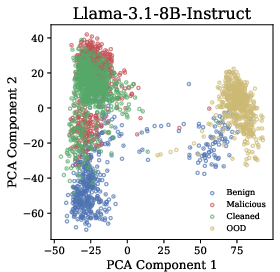
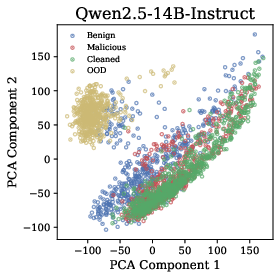
Figure 2: Hidden States Visualization. Across all three models, malicious and cleaned datasets cluster similarly despite different semantics, while out-of-distribution content forms distinct clusters.
Experimental Design
The empirical evaluation spanned different datasets, probing various LLM models, including Gemma, Llama 3.1, and Qwen2.5, across multiple scales. Diverse setups evaluated in-distribution (ID) versus OOD generalization, highlighting probing classifiers' exaggerated performance claims in ID settings versus their stark failures in OOD tests.
In-distribution accuracies approached near perfection (>98%) but dropped dramatically by up to 99 percentage points in OOD scenarios, with some setups failing entirely. This reveals a lack of robustness and raises significant concerns regarding the practical viability of these methods for real-world safety detection.
Layer and Architecture Impact
A detailed investigation into the impact of representation layers revealed consistent performance degradation patterns across different hidden layers, reinforcing the conclusion that probing methods capture non-semantic features. Moreover, experiments across different classifier architectures (SVM, Logistic Regression, MLP) reiterated the findings, indicating that the inadequacy is intrinsic to probing itself, not specific classifiers.
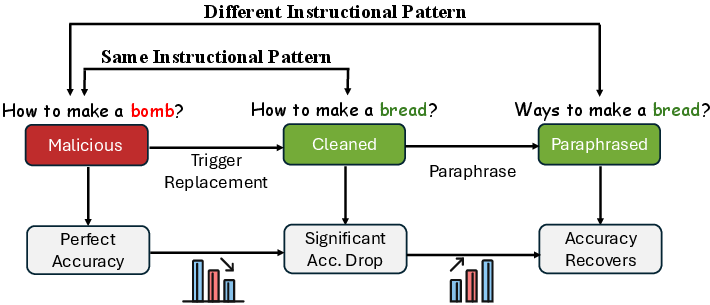
Figure 3: Experimental Design of Research Study 3.
Conclusion
The study underscores critical flaws in probing-based detection systems, elucidating their susceptibility to superficial pattern learning rather than robust, semantic harmfulness detection. These findings necessitate a paradigm shift in model design and evaluation protocols for safety detection systems in LLMs. Future research should focus on developing methods that integrate deeper semantic understanding to better equip AI systems for adversarial robustness in real-world applications. Such advancements will be pivotal for deploying AI safely and responsibly in diverse operational settings.

