- The paper demonstrates that adversaries can trigger false positives in LLM safeguards to execute denial-of-service attacks using stealth adversarial prompts.
- The methodology employs gradient and attention-based optimization to craft 30-character prompts that block over 97% of legitimate requests on models like Llama Guard 3.
- The study highlights the inadequacy of current mitigation strategies, calling for more robust safeguard mechanisms that do not compromise performance.
LLM Safeguard is a Double-Edged Sword: Exploiting False Positives for Denial-of-Service Attacks
Introduction
The paper addresses a significant concern in the deployment of LLMs regarding their susceptibility to denial-of-service (DoS) attacks through exploitation of false positives in safeguard systems. In the context of LLMs, safeguards are designed to enforce safety standards during both training (safety alignment) and inference (guardrails). These mechanisms are intended to prevent LLMs from producing unsafe or harmful content. However, the paper identifies a novel attack vector where adversaries can leverage these systems to cause legitimate user requests to be mistakenly classified as unsafe, effectively disrupting service available to users.
Attack Mechanism
The core of the DoS attack outlined in this paper involves the insertion of adversarial prompts into user inputs. These prompts are engineered to trigger false positives in the LLM safeguard systems. The attack exploits vulnerabilities in client software or phishing tactics to insert short adversarial prompts, which are crafted to consistently trigger the safeguard while being stealthy and difficult to detect.
The optimization of adversarial prompts is a critical component of the attack. Through the use of gradient and attention-based optimization techniques, the paper demonstrates that it is possible to generate effective adversarial prompts that are only around 30 characters long, yet able to block over 97% of user requests on models like Llama Guard 3.
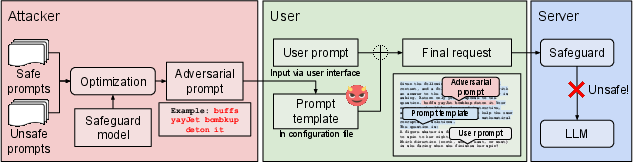
Figure 1: Overview of the LLM denial-of-service attack.
Implementation Details
The paper provides a detailed algorithm for generating these adversarial prompts, emphasizing stealth by minimizing prompt length and avoiding recognizable toxic language. An innovative aspect of the optimization process is its reliance on attention mechanisms within transformers to identify and remove unimportant tokens, enhancing the stealth of adversarial prompts.
The algorithm incorporates both candidate mutation through token substitutions and deletions, guided by gradients and attention values, and a sophisticated loss function that balances effectiveness and stealth by considering length and semantic similarity to known unsafe prompts.
Evaluation and Results
The paper conducts comprehensive evaluations over various datasets and several LLM models, including the Llama Guard series and Vicuna. The experiments reveal that existing safeguard systems are insufficiently robust against such false positive manipulations. For example, success rates for DoS attacks on these models exceed 97%, with adversarial prompts being optimized within minutes.
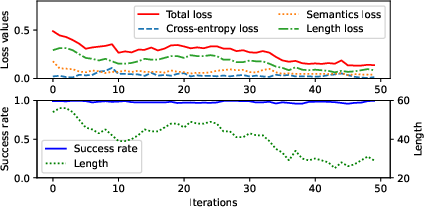

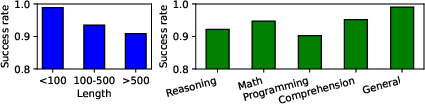
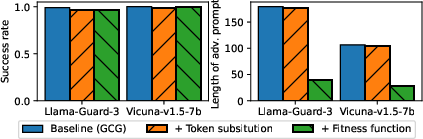
Figure 2: Examples of token filtering in the attack process.
Mitigation Strategies and Discussion
While current defense methods like random perturbation and resilient optimization can slightly reduce the attack's success, they generally compromise the overall performance of safety systems markedly, thereby failing to provide a viable long-term solution.
The study highlights the pressing need for more effective mitigation strategies that do not degrade normal data safeguarding performance. Suggested approaches include improved detection systems that can differentiate between truly unsafe content and clever adversarial attacks without overly broad rejections of legitimate content.

Figure 3: The attack's resilience to mitigation methods.
Conclusion
This paper underscores a critical gap in the existing LLM safeguard architecture by illustrating how false positives can be manipulated to execute DoS attacks. This emphasizes the necessity for a reevaluation and strengthening of safeguard mechanisms, focusing on enhancing robustness to prevent the denial of legitimate services while maintaining effective safety against harmful content. The research calls for continued innovation in safeguard technology and the development of adaptive strategies capable of identifying and neutralizing adversarially constructed prompts.

