- The paper presents LimiX, a unified transformer-based model tailored for structured-data tasks like classification, regression, and imputation through dual-axis attention.
- It employs context-conditional masked pretraining with synthetic data from DAGs, enhancing causal inference and robust prediction capabilities.
- The evaluation demonstrates superior performance and resilience to perturbations compared to baseline models across diverse tabular tasks.
"LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence"
Introduction
The paper "LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence" focuses on developing a structured-data model, LimiX, as a part of large structured-data models (LDMs), aimed at addressing tabular data tasks through conditional prediction capabilities. The authors posit that structured data requires a unique modeling approach distinct from NLP and perception-based models, due to its inherent characteristics such as metric geometry and patterns of missingness. LimiX is designed to solve multiple tabular tasks like classification, regression, missing value imputation, and data generation, utilizing a unified model architecture.
Architecture
LimiX's architecture is built around a transformer-based model, specifically tailored to address the distinctive features of structured data.
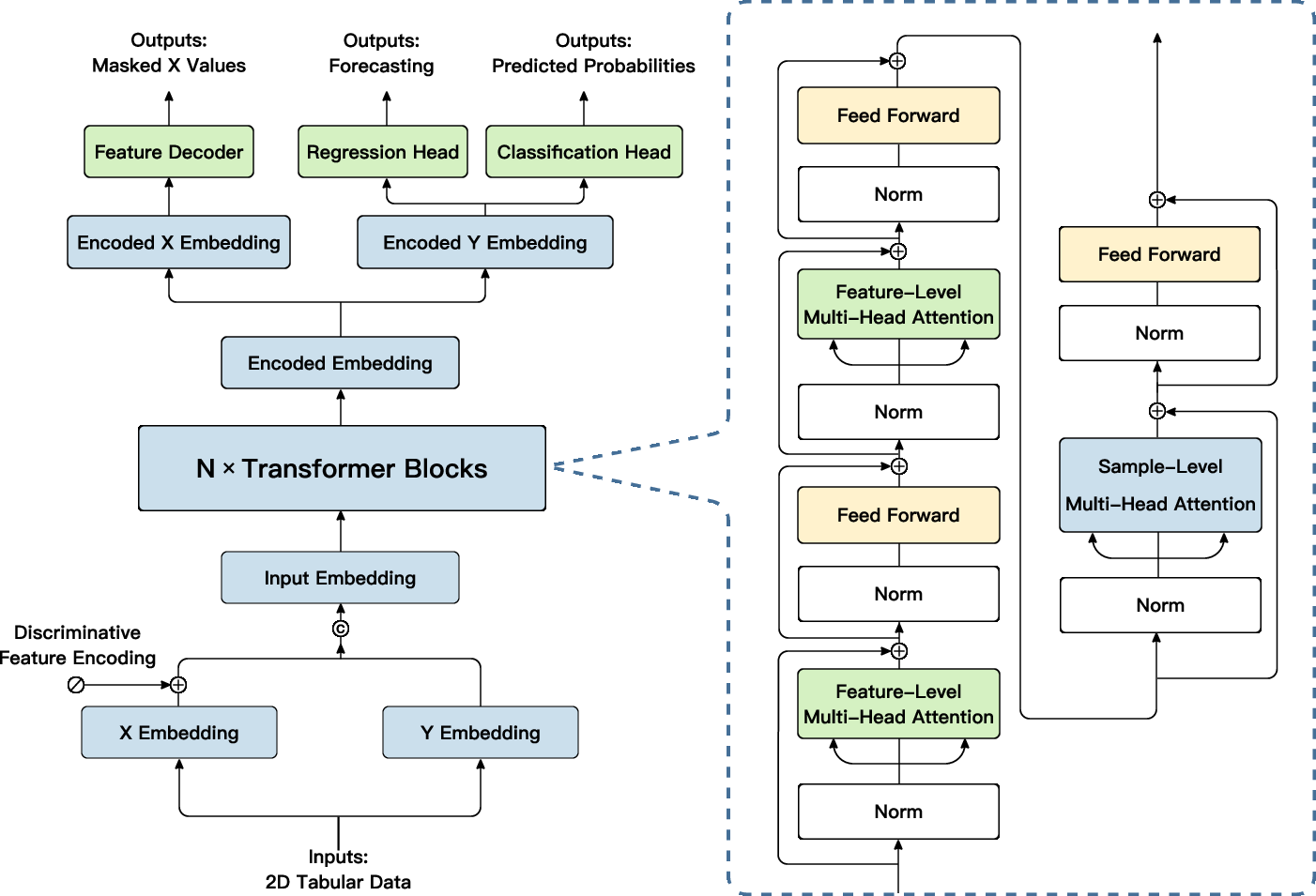
Figure 1: The overall model structure of LimiX.
Embedding and Encoding
The input tabular data is projected into a latent embedding space using a two-layer MLP with LayerNorm and GELU activations. To enhance the model's understanding of column identities, a discriminative feature encoding (DFE) approach is employed, allowing implicit interaction awareness without parameter inflation.
Model Structure
The model uses a 12-block transformer design, where attention mechanisms are applied along both feature and sample axes. This dual-axis attention is crucial for capturing dependencies within the structured data, allowing LimiX to generalize across various tasks without requiring specific training for each.
Pretraining and Data Generation
LimiX utilizes a masked distribution modeling approach for pretraining, enabling it to answer conditional queries effectively.
Context-Conditional Masked Modeling
The pretraining strategy involves splitting datasets into context and query subsets. The model forms context-specific priors and focuses on query predictions, promoting adaptability without the necessity for fine-tuning.
Synthetic Data Generation
To ensure robust generalization, LimiX is pretrained on a diverse set of synthetic datasets derived from Directed Acyclic Graphs (DAGs) representing complex causal relationships. This approach enhances its ability to infer causal dependencies present in real-world structured data.
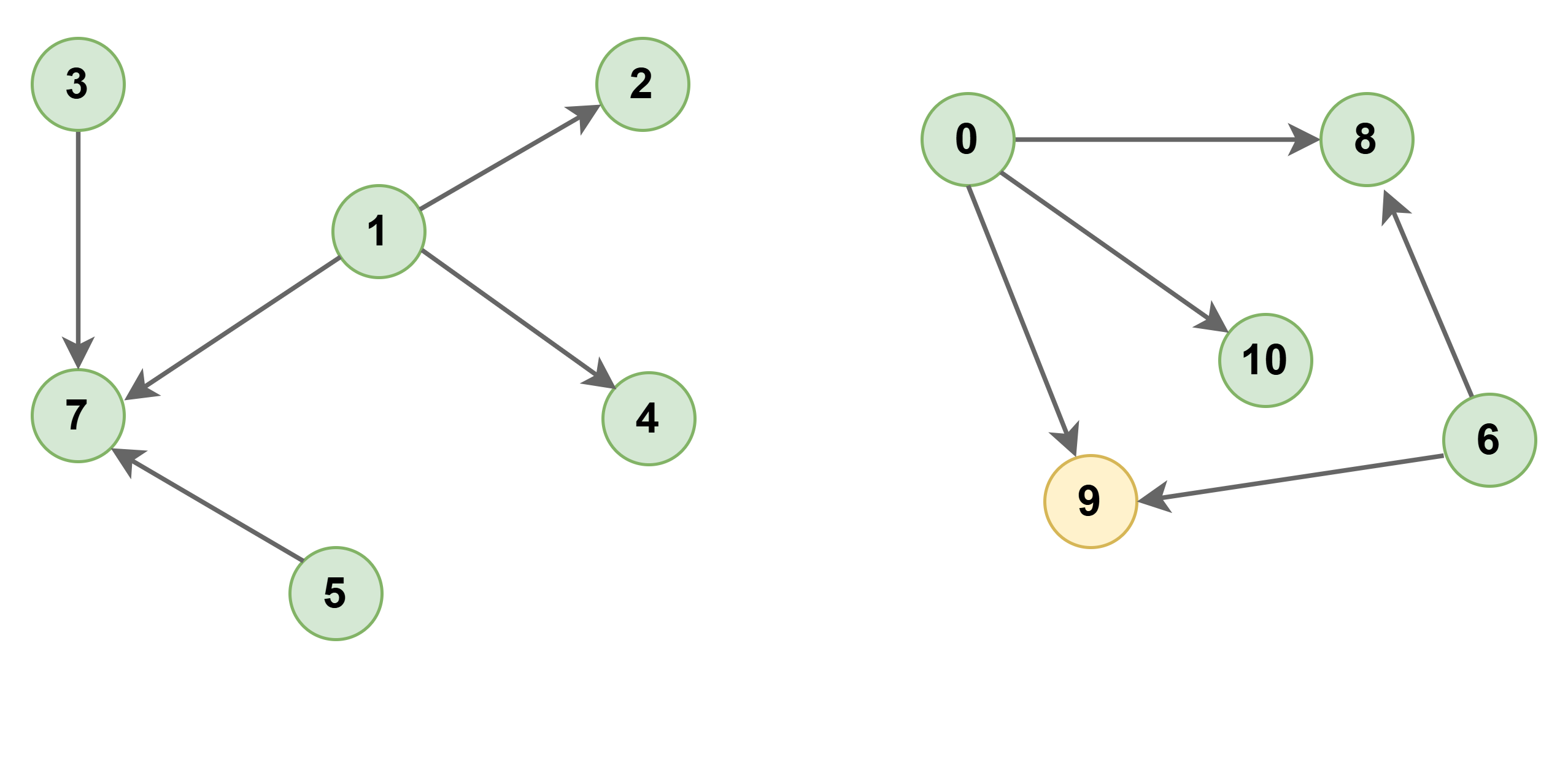
Figure 2: Causal DAG of synthetic samples.
Retrieval-Based Ensemble
At inference time, LimiX employs a retrieval-based ensemble strategy to enhance predictive accuracy. Using attention scores, important samples and features are identified, allowing the model to leverage relevant data effectively for improved predictions.
Evaluation
LimiX is rigorously evaluated against baseline models, showcasing superior performance across classification, regression, and imputation tasks. It demonstrates robustness under various perturbations, such as the addition of uninformative features and outliers.
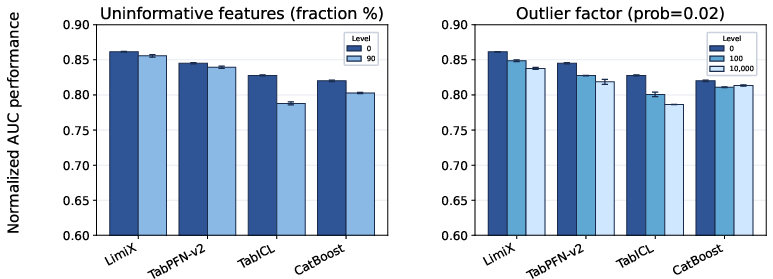
Figure 3: Robustness analysis in classification Tasks. LimiX consistently exhibits the best performance and superior robustness under perturbations.
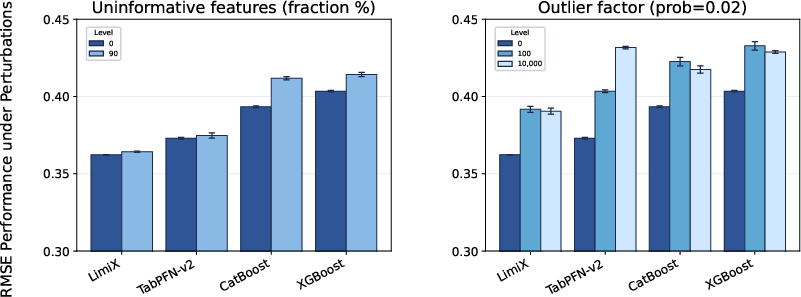
Figure 4: Robustness analysis in regression tasks. LimiX consistently exhibits the best performance and superior robustness under perturbations.
Conclusion
LimiX represents a step forward in structured-data modeling, achieving state-of-the-art performance across a variety of benchmarks. Its ability to handle multiple structured-data tasks within a single model framework marks a significant advancement in the development of generalist intelligence models. The methodology, architecture design, and comprehensive evaluation underscore LimiX's potential as a foundational tool for structured-data analysis.

