- The paper presents a novel structured prompting methodology that improves LLMs' accuracy for long legal documents.
- It utilizes a chunking and augmentation strategy to efficiently manage oversized texts while maintaining legal context.
- Heuristic candidate selection methods like DBL and ICW further refine outputs, increasing retrieval accuracy by up to 9%.
Structured Prompting Methodology for Long Legal Documents
The paper "LLMs for LLMs: A Structured Prompting Methodology for Long Legal Documents" presents a novel structured prompting methodology designed to enhance the performance of LLMs in processing long legal documents. This essay will explore the detailed methodologies and findings presented in the paper, focusing on the application of structured prompting for information retrieval tasks within the legal domain.
Introduction and Motivation
The advent of LLMs has revolutionized multiple fields; however, their application in the legal domain remains hindered by issues of reliability and transparency. Fine-tuning LLMs for legal tasks is resource-intensive and often impractical due to the specialized nature of legal language and the complexities involved in legal documents. This paper proposes structured prompting as an alternative to fine-tuning, providing a cost-effective and scalable solution for information retrieval in legal texts.
The core challenges addressed include the "long document problem," where a legal document exceeds the model's context window, and the "information retrieval problem," which involves extracting specific data from a document or a set of documents. The research leverages the Contract Understanding Atticus Dataset (CUAD) and the QWEN-2 LLM to demonstrate the efficacy of the proposed methods.
Methodology
Dataset and Model Selection
The authors utilize the CUAD dataset, a comprehensive collection of American legal documents annotated for information retrieval tasks. The dataset includes various document types and a wide range of questions related to contractual clauses. The QWEN-2 model serves as the generalist LLM used for experimentation, with a focus on demonstrating the potential of structured prompting without fine-tuning.
Chunking and Augmentation
To address the long document problem, the paper introduces a chunking and augmentation strategy. Documents are split into uniform chunks, allowing the model to process segments efficiently. This approach preserves the document’s inherently legal context, minimizing information loss.
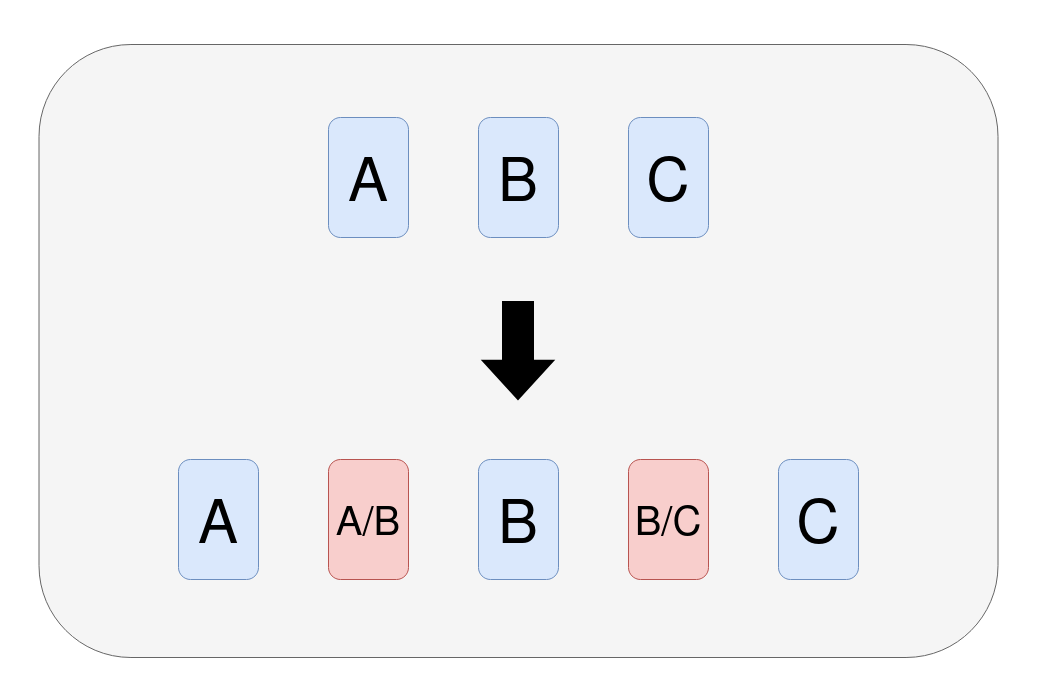
Figure 1: The augmentation (reduplication) step remedies the context splitting problem caused by having cut off points in chunking.
Structured Prompting
The core of the methodology is a carefully engineered prompting strategy. Each document chunk is accompanied by a specificity-driven prompt crafted to guide the model’s attention towards relevant sections. Through empirical testing, the study defines an optimal base template for crafting these prompts, enhancing the model's ability to retrieve accurate responses.
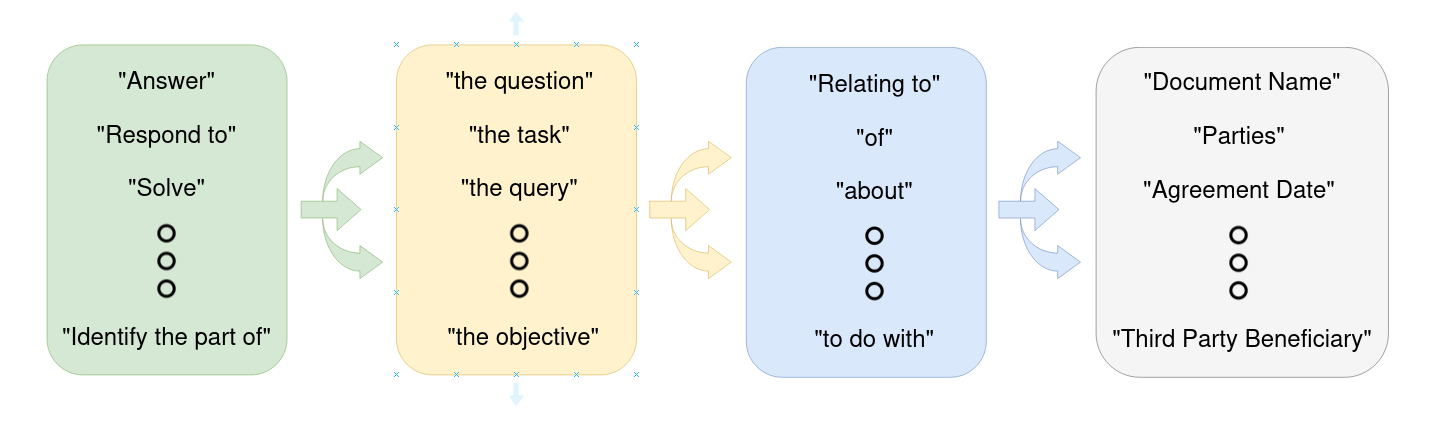
Figure 2: Methodology for creating the base template. Paraphrases are trialed on the test set to evaluate performance.
Heuristic Candidate Selection
The study introduces two heuristic strategies for refining model outputs:
- Distribution-Based Localisation (DBL): Utilizes a distribution over document segments to predict likely answer locations, enhancing reliability and accuracy.
- Inverse Cardinality Weighting (ICW): Groups outputs by similarity to identify the most probable answers, leveraging GritLM embeddings and the DBSCAN clustering algorithm for candidate refinement.
Results and Analysis
The proposed methodology demonstrates a substantial improvement in retrieval tasks. QWEN-2, augmented with structured prompts, achieves a notable average correctness increase of about 9% per question compared to the baseline DeBERTa-large model.
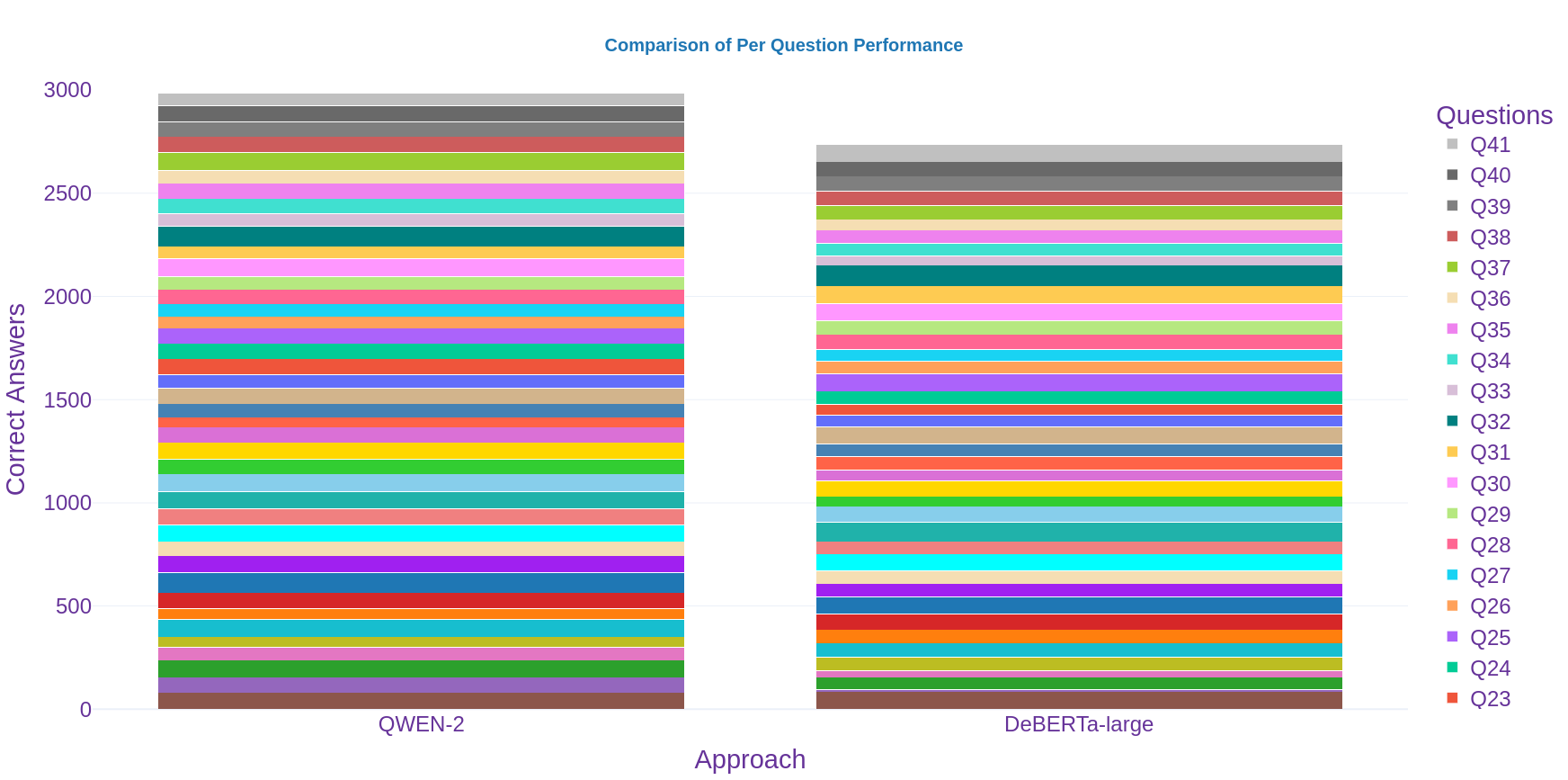
Figure 3: Comparison shows QWEN-2, with few exceptions, matches or surpasses DeBERTa-large across almost all questions.
Further analysis excludes true negative results from the comparison, focusing on practical usage for legal experts where clause existence is the primary concern. This consideration led to an observed average correctness increase of 6% per question, highlighting the methodology’s effectiveness in real-world applications.
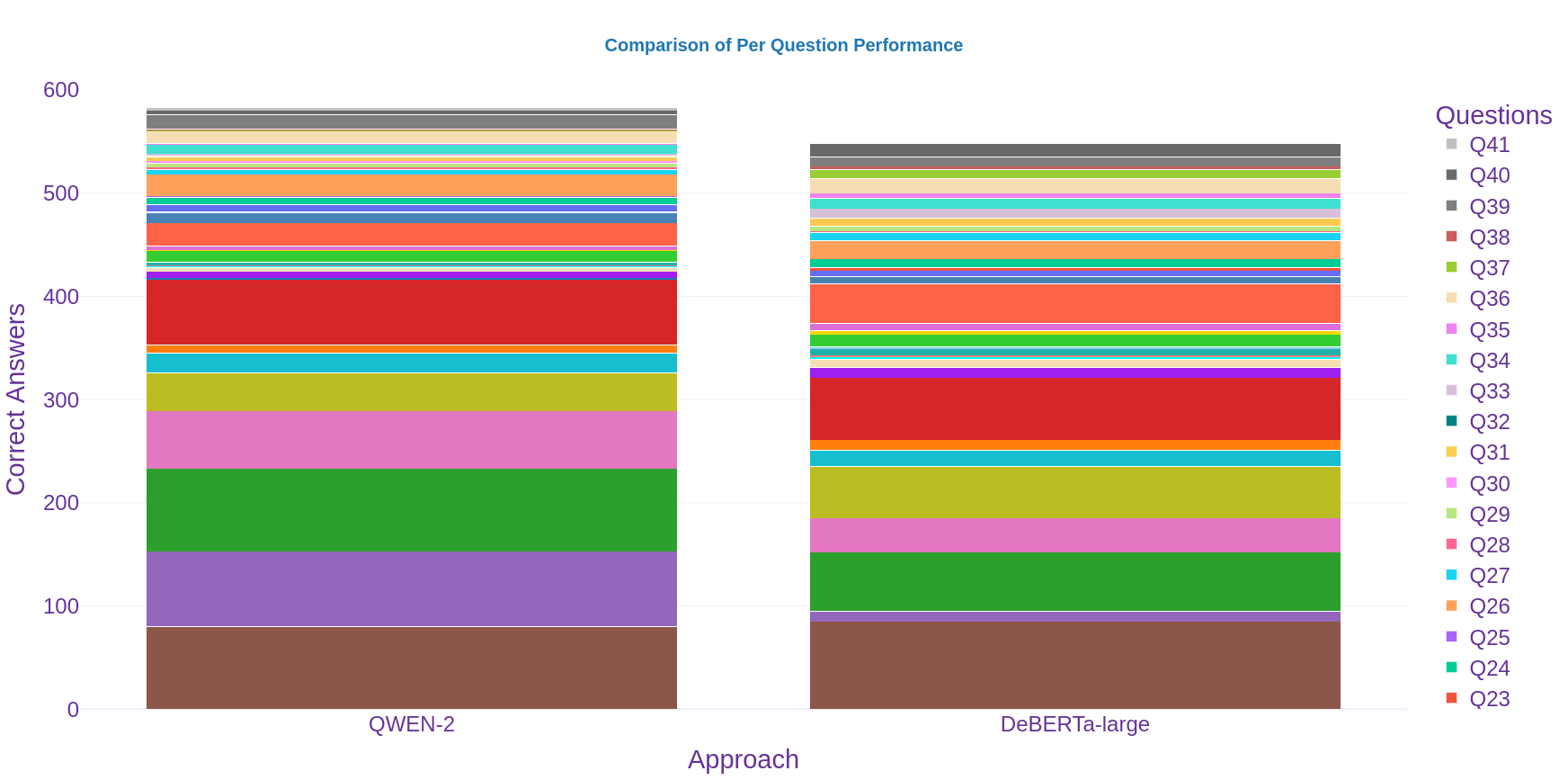
Figure 4: Excluding true negatives, QWEN shows increased performance reflecting the practical utility for legal practitioners.
Conclusion
The paper convincingly argues that structured prompting is a viable alternative to model fine-tuning for long legal documents, achieving state-of-the-art performance with minimal resources. The techniques developed not only enhance information retrieval accuracy but also improve transparency by mitigating the black-box nature of LLMs. Future work could focus on refining heuristic evaluation metrics to further advance the methodology's applicability across various AI-driven legal tasks. The study also underscores the importance of human-understandable AI in ensuring accountability, paving the way for ethically sound AI practices within and beyond the legal domain.