Automating Transparency Mechanisms in the Judicial System Using LLMs: Opportunities and Challenges (2408.08477v1)
Abstract: Bringing more transparency to the judicial system for the purposes of increasing accountability often demands extensive effort from auditors who must meticulously sift through numerous disorganized legal case files to detect patterns of bias and errors. For example, the high-profile investigation into the Curtis Flowers case took seven reporters a full year to assemble evidence about the prosecutor's history of selecting racially biased juries. LLMs have the potential to automate and scale these transparency pipelines, especially given their demonstrated capabilities to extract information from unstructured documents. We discuss the opportunities and challenges of using LLMs to provide transparency in two important court processes: jury selection in criminal trials and housing eviction cases.
Collections
Sign up for free to add this paper to one or more collections.
Summary
- The paper demonstrates that LLMs can automate data extraction from legal documents to audit biases in jury selection and eviction cases.
- Experiments reveal varying accuracies, with challenges in handling complex tasks such as understanding juror demographics and handwritten notes.
- Findings call for significant technical and legal investments to standardize legal data and enhance LLM performance.
Automating Transparency Mechanisms in the Judicial System Using LLMs
The paper "Automating Transparency Mechanisms in the Judicial System Using LLMs: Opportunities and Challenges" (2408.08477) explores the potential and limitations of employing LLMs to enhance transparency in the judicial system. The authors focus on automating the extraction of information from unstructured legal documents to facilitate auditing for biases and errors in jury selection and housing eviction cases. The paper highlights the challenges in accessing and processing legal data and assesses LLM performance on specific information extraction tasks, emphasizing the need for both technical and legal investments to realize the potential of automated transparency mechanisms.
Background and Motivation
The judicial system is often scrutinized for structural biases that exacerbate social inequalities. Manual audits by journalists and researchers are essential for uncovering these biases, but they are resource-intensive and time-consuming. LLMs offer a promising avenue to automate and scale these transparency efforts by extracting key information from legal documents. The paper addresses the current gap in leveraging LLMs for transparency, distinguishing itself from prior work that primarily focuses on automating tasks for legal professionals. The authors aim to demonstrate the opportunities and challenges of using LLMs for transparency in jury selection and housing eviction processes.
Case Studies and Document Extraction Tasks
The paper presents two case studies: jury selection in criminal trials and housing eviction cases. Both areas are known for potential biases and exploitative practices.
Jury Selection
Transparency in jury selection requires analyzing court transcripts and jury strike sheets. The authors outline several document extraction tasks:
- Juror Demographic Information: name, race, gender, and occupation history.
- Trial Information: county, judge, attorneys, offense, and case verdict.
- Voir Dire Responses: reasons jurors are unable to be impartial.
- Selected Jurors: whether each prospective juror was selected or struck.
- Batson Challenges: whether a challenge claim was made and by whom.
Eviction
Transparency in eviction processes requires analyzing various court documents to uncover exploitative practices. Key document extraction tasks include:
- Case Background: address, tenancy details, landlord type, and legal representation.
- Procedural History of the Case: tenant defaults, executions issued, and case dispositions.
- Settlement Terms: specific settlement conditions and judgments.
LLM Capabilities and Experimental Setup
The paper identifies essential LLM capabilities for document extraction:
- Synthesis: Integrating information from multiple documents or sections.
- Inference: Deriving logical or legal conclusions from the extracted data.
- Non-Categorical Query: Handling queries that do not require specific categorical outputs.
- Handwritten Information: Processing and interpreting handwritten annotations within documents.
The authors conducted experiments using OpenAI's GPT-4 Turbo model (gpt-4-turbo-2024-04-09) and gpt-3.5-turbo-0125 for fine-tuning. The experiments involved zero-shot prompting and evaluated LLM performance on specific tasks within each case paper.
Results and Challenges
The results reveal varying LLM performance across different tasks, with accuracy generally decreasing as task complexity increases.
Jury Selection
- Selected Juror Names: Achieved 81.6% accuracy, with common errors including incomplete recall and misunderstanding the output format.
- Batson Challenges: Showed low accuracy (23.2%), attributed to the legal inference required to identify and classify Batson challenges.
- Jury Gender Composition: Demonstrated the lowest accuracy (3.6%), with challenges in synthesizing information across transcripts and understanding speech disfluencies.

Figure 1: Example of a jury selection voir dire transcript excerpt. We extracted these excerpts of the final jury roll call in order to improve performance on the tasks of extracting selected juror names and determining the jury's gender composition. The highlighted text is a disfluency that causes the model to miscount jurors.
Eviction
- Zip Code: High accuracy (95.8%) due to the straightforward nature of the task.
- Landlord Type: Achieved 89.7% accuracy, with errors mainly due to the model failing to find relevant information.
- Landlord Representation Status: Demonstrated 71.0% accuracy, with inference from signatory names posing a challenge.
- Case Disposition: Surprisingly high accuracy (94.9%), attributed to specific files indicating the ultimate disposition.
- Settlement Type: Achieved 88.6% accuracy, with performance affected by handwritten information in settlement agreements.
- Execution Issued: Lowest accuracy (68.8%) due to the legal context required and reliance on handwritten information.
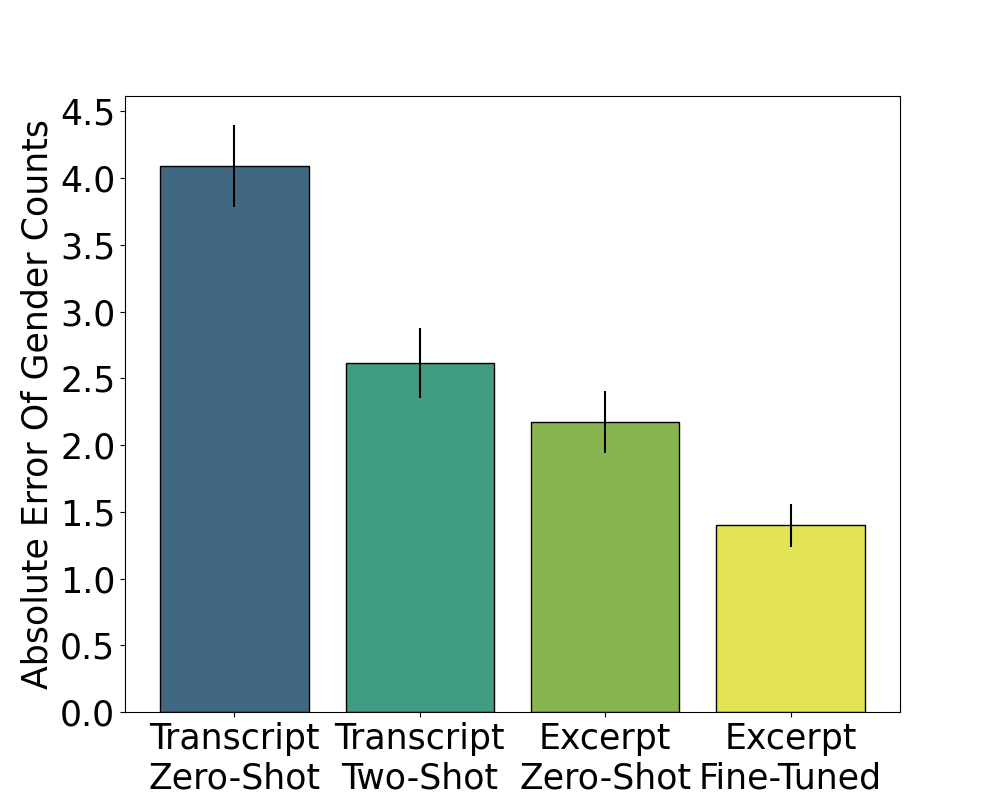
Figure 2: Absolute error for the jury gender composition task across different technical interventions. Error bars represent the standard error over all iterations.
Improving Jury Selection Performance
The paper explored few-shot prompting, reducing document length, and fine-tuning to improve performance on jury selection tasks. Two-shot prompting significantly improved the Batson challenges task, increasing accuracy from 23.2% to 76.8%. Limiting the input to final jury roll call excerpts improved jury gender composition accuracy. Fine-tuning further enhanced performance, reducing absolute error.
Downstream Impact Tests
The authors highlighted the importance of measuring model performance in the context of downstream auditing questions. Using LLM outputs to determine jury gender composition altered the outcomes of potential audits, affecting the ranking of counties and prosecutors with the most female bias in jury selection.
Technical and Legal Investments
The paper underscores the need for significant technical and legal investments to facilitate the use of LLMs for legal auditing.
Technical Investments
- Re-Orienting Benchmarks: Developing benchmarks that align with real-world impact.
- Training Datasets: Expanding training on unstructured legal data.
- Pre-Processing Capabilities: Improving OCR tools for handwritten information and methods for identifying relevant document sections.
Legal Investments
- Data Accessibility and Standardization: Mandating standard document formats and digital databases.
- Model End-Users: Collaborating with legal experts and journalists to address hesitations in adopting LLMs.
- Mitigating Disparate Impacts: Addressing potential biases in model performance across different jurisdictions and communities.

Figure 3: Example strike sheets showing the variance in note-taking that occurs to document juror demographics and strike status. Common demarcations include 'W'/'B' for race, 'F'/'M' for gender, SX/DX for state and defense strikes, and 'C' for for-cause strikes.

Figure 4: Example Summary Process Summons and Complaint issued by the landlord to call the tenant to court and inform them of the grounds of eviction.

Figure 5: Example docket entry page including the final disposition (Agreement for Judgement) of an eviction case. The variability in handwriting and format of this page makes it difficult to automatically extract information.
Conclusion
The paper provides valuable insights into the opportunities and challenges of using LLMs to automate transparency mechanisms in the judicial system. The authors demonstrate that while LLMs have the potential to assist in information extraction from legal documents, their performance is highly dependent on task complexity and data quality. The paper emphasizes the need for targeted technical and legal investments to ensure that LLMs can effectively contribute to transparency and accountability in the judicial system.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Follow-up Questions
- How does the paper evaluate the performance of LLMs in extracting legal information?
- What differences in accuracy were observed between jury selection and eviction case studies?
- How can few-shot prompting be optimized to improve LLM performance on complex legal tasks?
- What are the key technical challenges in processing unstructured legal data such as handwritten annotations?
- Find recent papers about judicial transparency automation.
Related Papers
- LawBench: Benchmarking Legal Knowledge of Large Language Models (2023)
- DISC-LawLLM: Fine-tuning Large Language Models for Intelligent Legal Services (2023)
- A Short Survey of Viewing Large Language Models in Legal Aspect (2023)
- LegalLens: Leveraging LLMs for Legal Violation Identification in Unstructured Text (2024)
- Automatic Information Extraction From Employment Tribunal Judgements Using Large Language Models (2024)
- Leveraging Large Language Models for Relevance Judgments in Legal Case Retrieval (2024)
- Exploring the Nexus of Large Language Models and Legal Systems: A Short Survey (2024)
- LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks (2024)
- Equitable Access to Justice: Logical LLMs Show Promise (2024)
- Bye-bye, Bluebook? Automating Legal Procedure with Large Language Models (2025)