- The paper introduces a decentralized MARL framework that mitigates congestion via CMDP-based constraint handling and multi-timescale optimization.
- It demonstrates superior scalability and sample efficiency compared to IQL and MAPPO, validated through extensive battery-driven offloading experiments.
- The study provides strong theoretical guarantees and practical insights for robust coordination in shared, resource-constrained wireless edge environments.
Multi-Agent Constrained Reinforcement Learning for Task Offloading at the Wireless Edge
Overview
"Multi-Agent Reinforcement Learning for Task Offloading in Wireless Edge Networks" (2509.01257) introduces a decentralized multi-agent reinforcement learning (MARL) framework for scalable and communication-efficient coordination in wireless mobile edge computing (MEC) environments. The paper focuses on the scenario where numerous devices independently determine whether to process computational tasks locally or offload them to a shared and bandwidth-constrained edge server. The primary technical challenge arises from the congestion effects at the server and on the wireless channel, which induce a coupling in the agents' rewards and create a coordination dilemma. The proposed framework explicitly models these shared resource constraints and leverages Constrained Markov Decision Processes (CMDPs) with decomposable surrogates and infrequent scalar communication to enable implicit coordination.
Problem Setting and Structural Coupling
The system involves N agents (devices), each with local state variables capturing workload, battery status, and other system observables. The central coupling arises via a "crowded" offloading action, whose global penalty depends non-additively on the number of agents selecting it—a scenario characteristic of congestion games and social dilemmas. The reward function for each agent thus contains a local utility term and a congestion penalty governed by d(Noffload), where d(⋅) is strictly increasing and potentially nonlinear. Classical value decomposition or independent learning fails due to this nonstationarity and non-additivity.
Decentralized Constrained Coordination Framework
To address the coordination challenge, the paper proposes the DCC (Decentralized Coordination via CMDPs) framework. The main idea is to decouple policy optimization across agents using agent-local CMDPs, embedding the global congestion impact via a shared long-term constraint θ. This constraint regulates the average offloading rate per agent, with all coordination executed at the level of occasional scalar updates to the vector θ. Each agent then follows a three-timescale optimization:
- Fast timescale: Each agent optimizes its policy with respect to its CMDP, given current constraints, using standard off-policy RL (e.g., Q-learning or PPO) and Lagrangian-based constraint enforcement.
- Intermediate timescale: The Lagrange multipliers for each agent are updated to enforce satisfaction of the constraint.
- Slow timescale: The shared constraint vector θ is improved using an approximate global objective and a scalable stochastic gradient method.
Critically, the framework replaces the stochastic global congestion term with its mean field approximation using θ, providing favorable theoretical error bounds and, in certain cases (e.g., linear congestion), exact equivalence to the global objective. This allows tractable, decentralized optimization while preserving the core interdependence structure.
Theoretical Results
The paper establishes formal results guaranteeing the soundness and convergence of the proposed decomposition and learning method. Specifically, it proves:
- The bias introduced by the surrogate reward is strictly bounded, vanishing when the congestion penalty is linear.
- Under mild regularity and constraint conditions, the multi-timescale algorithm converges to a local minimum of the decomposed objective.
- The gradient of the decomposed global objective with respect to θ admits an efficient structure that reduces sample complexity.
Numerical Evaluation and Empirical Observations
The framework is validated via an extensive suite of experiments using a realistic battery-driven offloading model with task aging and penalties for missed deadlines (see Figure 1 and Figure 2 in the paper). All code and additional experimental procedures are available open-source.
The core empirical finding is a substantial scalability and robustness advantage of the DCC-QL (Q-learning with DCC) method compared to both fully decentralized independent Q-learning (IQL) and state-of-the-art CTDE-based MAPPO baselines. In particular, DCC-QL:
- Outperforms IQL across all system sizes, especially as agent population increases, due to IQL's inability to internalize coupled congestion effects.
- Provides superior sample efficiency compared to MAPPO, maintaining high performance as the number of agents grows, with only lightweight scalar communication of constraint updates.
This is quantitatively illustrated by the normalized final average reward across methods (Figure 3):
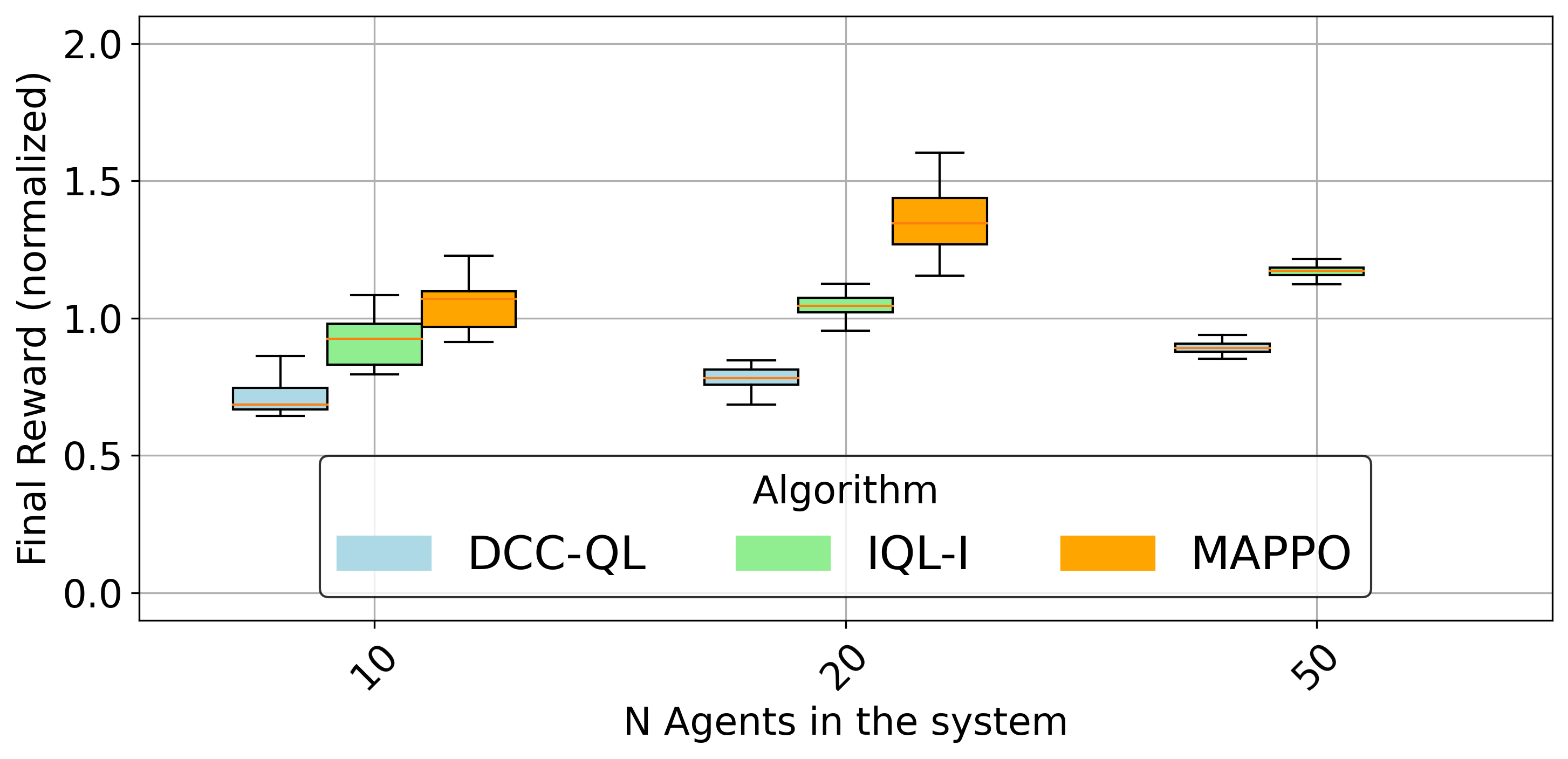
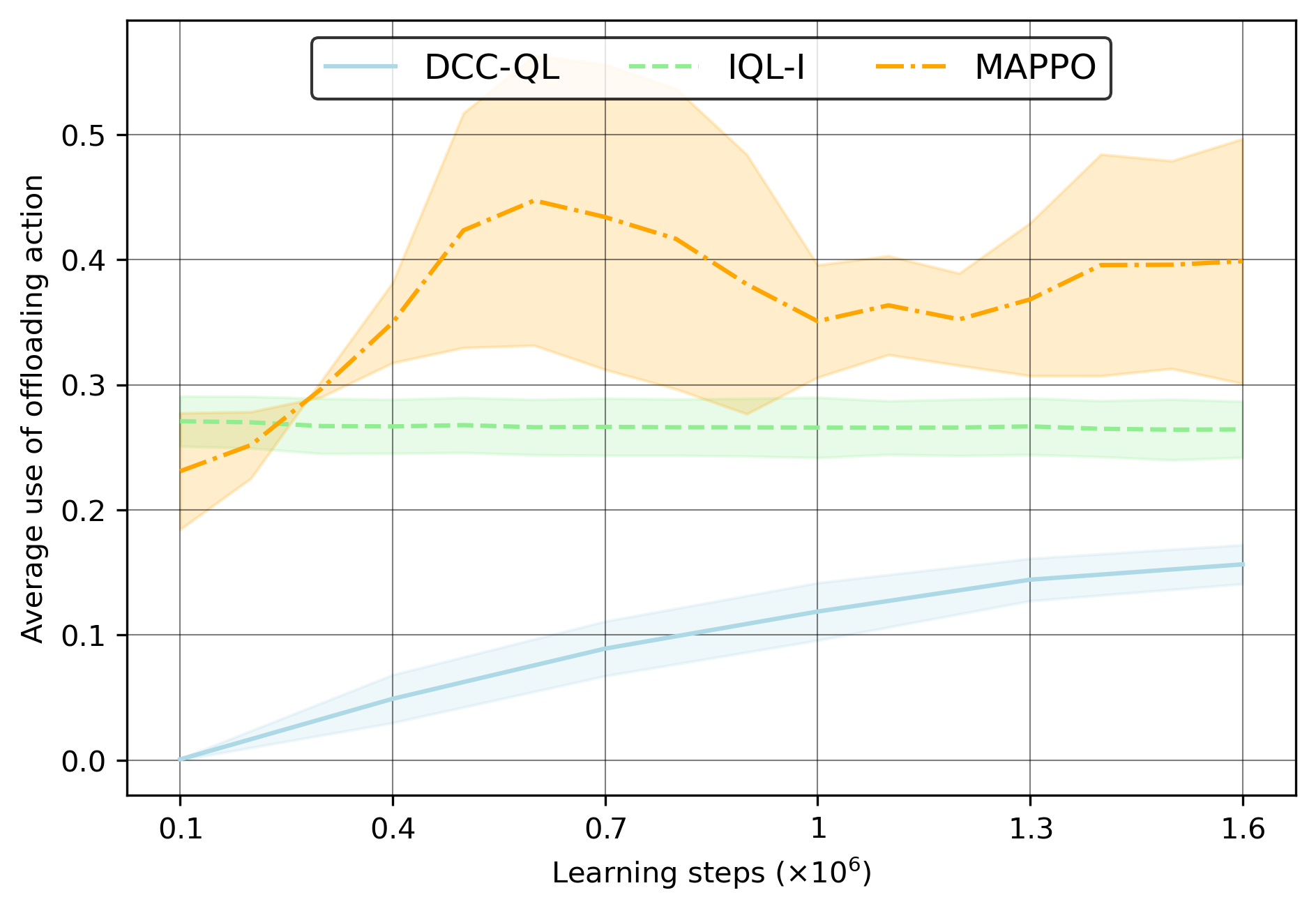
Figure 3: Comparison of normalized final average reward for various methods; DCC-QL maintains strong performance as system size grows, outperforming IQL and MAPPO at scale.
Analyzing the action statistics supports that IQL agents rapidly converge to overusing the crowded action (offloading), resulting in system-wide congestion, while DCC-QL converges to refined, stable utilization (see Figure 4 and Figure 5):
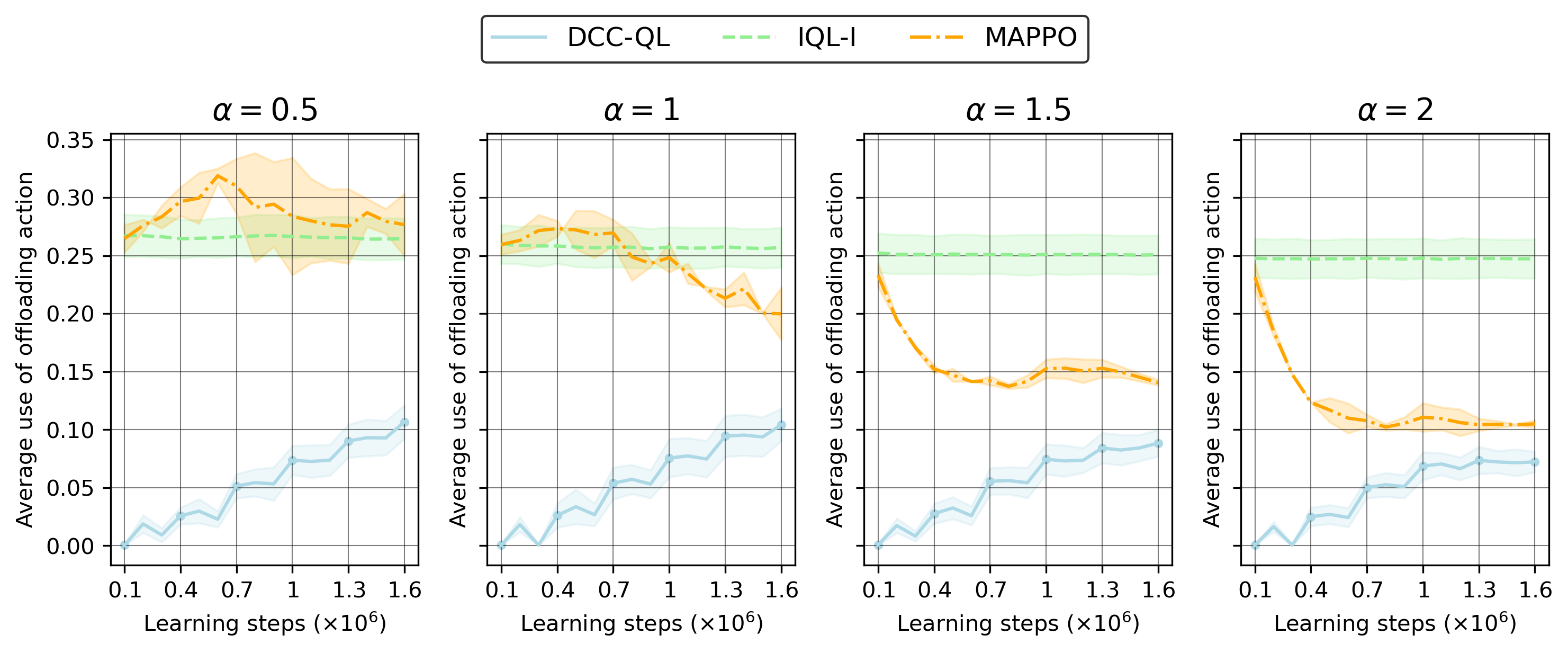
Figure 5: Offloading frequency decreases consistently as the penalty exponent α increases, which sharpens the system-level constraint and differentiates algorithms' behaviors.
Early iterations with better or worse prior constraints show only modest effects on final performance, but a "good" initialization can accelerate convergence, especially in smaller systems (Figure 6, Figure 7):
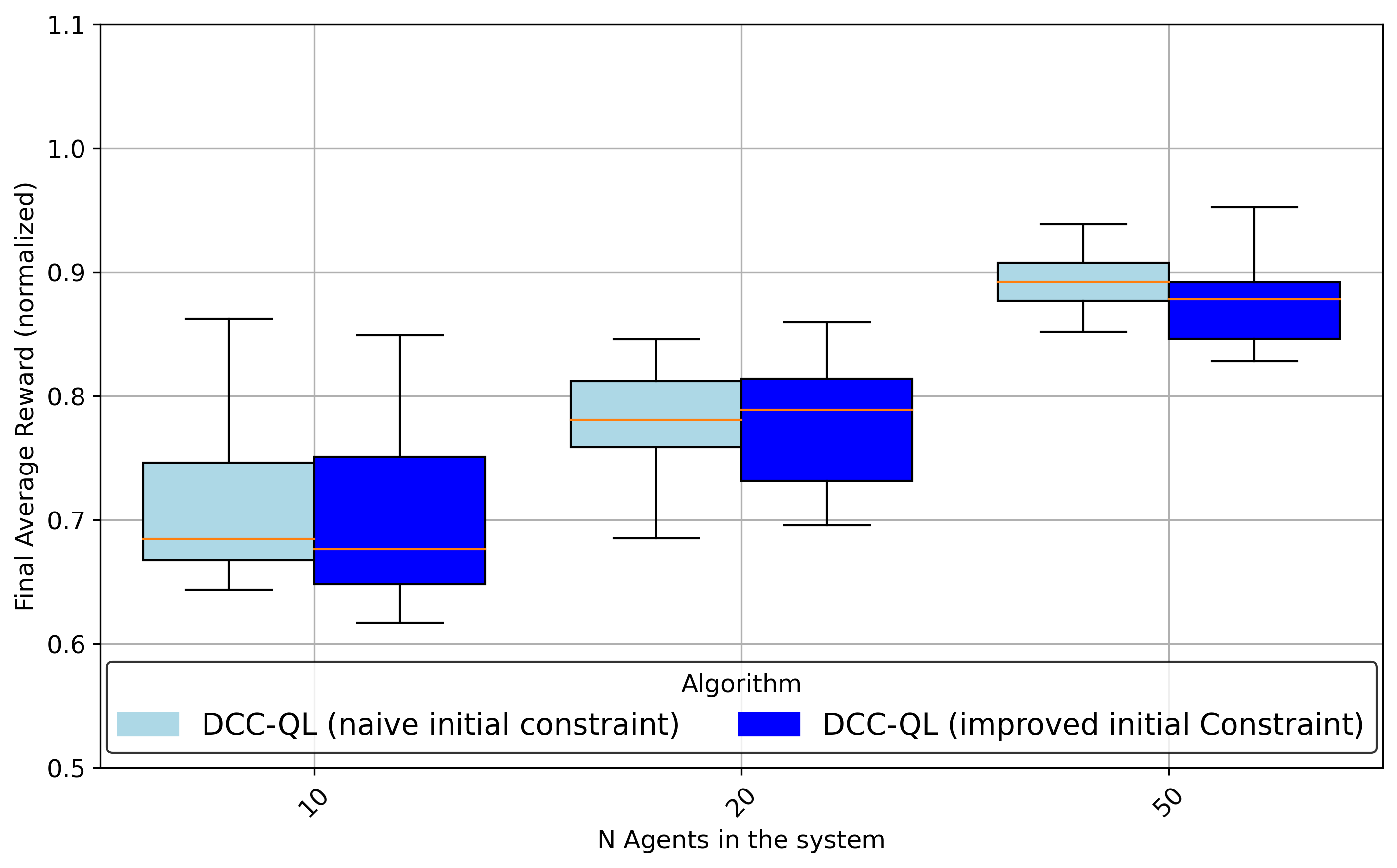
Figure 6: Final reward comparison for different initializations of the constraint vector—warmer starts converge more rapidly.
Gradient Structure and Algorithmic Implications
The paper further validates, both theoretically and empirically, that the gradient of the objective with respect to local constraints matches the negative Lagrange multiplier at the solution, up to scaling—supporting the correctness of the finite-difference estimation and suggesting an avenue for further reducing gradient estimation variance (see Figure 8):
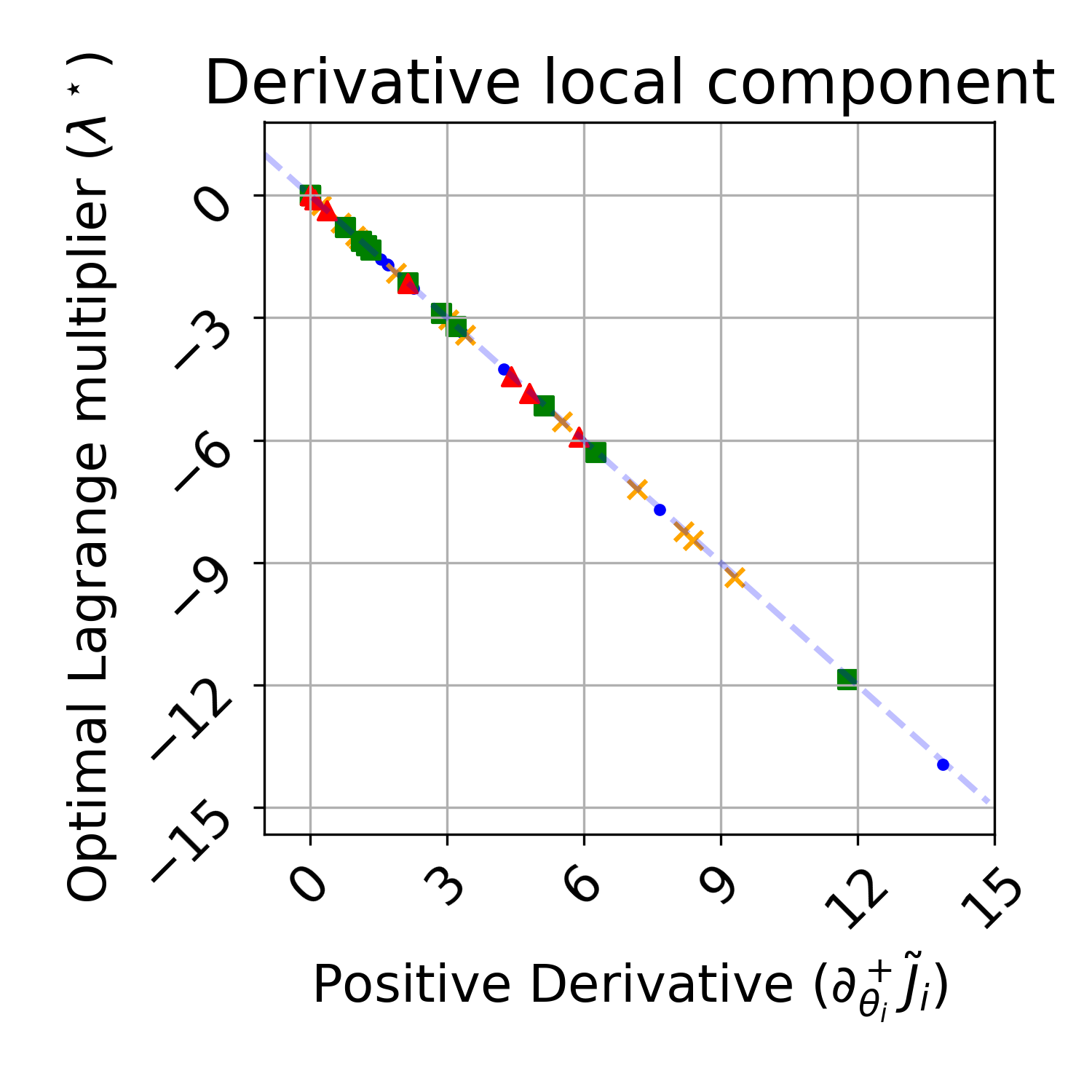
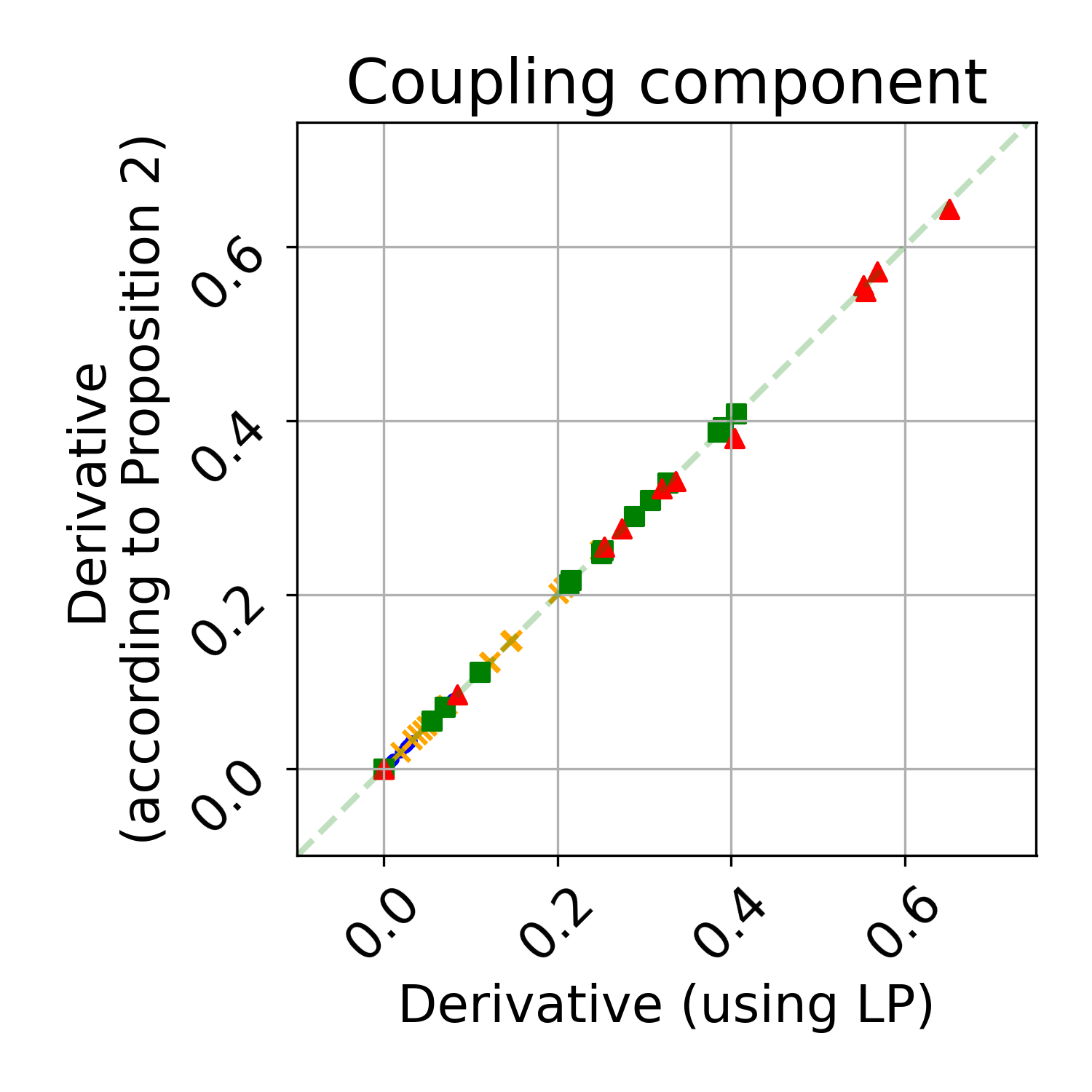
Figure 8: The finite-difference local gradient matches the negative of the optimal Lagrange multiplier, confirming the envelope theorem in CMDP structure.
Theoretical and Practical Implications
The primary theoretical contribution is establishing, in a formal and constructive fashion, that implicit coordination at scale is possible for strongly-coupled MARL systems under strict observability and communication constraints, by leveraging carefully designed surrogate objectives, CMDP structures, and multi-timescale optimization. This approach is fundamentally compatible with general safe RL algorithms and is robust to moderate model errors on the congestion function.
Practically, this method describes a scalable blueprint for decentralized RL in a wide range of settings—beyond MEC, to any large-scale shared-resource system (IoT orchestration, smart grid balancing, distributed sensor fusion)—where frequent communication, centralized training, or dense reward signal exchange is infeasible. The results caution against naïve application of independent learners in systems with externalities, and show that even scalar coordination channels (as in virtual admission control) are sufficient to resolve deep coordination challenges.
Future Directions
Future work could address (1) support for asynchronous constraint updates, (2) richer classes of coupled constraints, (3) incomplete or adversarial communication, and (4) sample complexity analysis under finite agents and high-dimensional constraints. Application to realistic wireless and MEC simulators, including time-varying channel models, heterogeneous cost profiles, and adversarial agents, is likely to validate and extend these theoretical gains.
Conclusion
This work establishes an effective, theoretically-grounded model for multi-agent implicit coordination in constrained offloading and other congested wireless resource allocation problems. The DCC framework generalizes beyond offloading and admits scalable, decentralized policy learning with strong empirical and analytical justification. The insights provided lay a robust foundation for extending safe and efficient MARL to practical, large-scale systems encountered in future autonomous wireless networks.
Reference:
Fox, A., De Pellegrini, F., & Altman, E. "Multi-Agent Reinforcement Learning for Task Offloading in Wireless Edge Networks" (2509.01257)