- The paper introduces a novel decentralized MARL framework that adapts its communication strategy to reduce noise and congestion in traffic networks.
- It integrates representational message compression with deep Q-learning to optimize traffic signal decisions, achieving lower queue lengths in simulations.
- Selective recipient identification and dynamic message length adjustment enable efficient bandwidth use, proving scalable in both synthetic and real-world networks.
Multi-Agent Reinforcement Learning for Traffic Signal Control
Introduction
The advancement of urban intelligent transportation systems (ITS) necessitates sophisticated approaches to address traffic congestion, a critical issue exacerbated by increased urbanization and growth of ride-hailing services. Multi-Agent Reinforcement Learning (MARL) frameworks have shown promise in controlling traffic signals dynamically. However, centralized methods face scalability challenges, while decentralized protocols introduce complications such as partial observability. Communication between agents within decentralized MARL systems is pivotal for coordination, yet excessive communication can lead to noise and performance degradation. This paper proposes a novel communication-oriented MARL approach, enhancing large-scale Traffic Signal Control (TSC) by selectively determining message recipients and adjusting message content length to optimize communication.
Communication Framework
The study introduces a decentralized MARL framework incorporating communication policies that allow agents to dynamically decide the recipients and parts of messages that need transmission. This selective communication protocol aims to reduce noise and optimize bandwidth usage in large-scale settings. The proposed method builds upon existing frameworks such as Q-MIX and NDQ, enhancing them with representational message compression and selective recipient identification. Implementation within synthetic and real-world traffic networks demonstrates significant efficiency improvements.
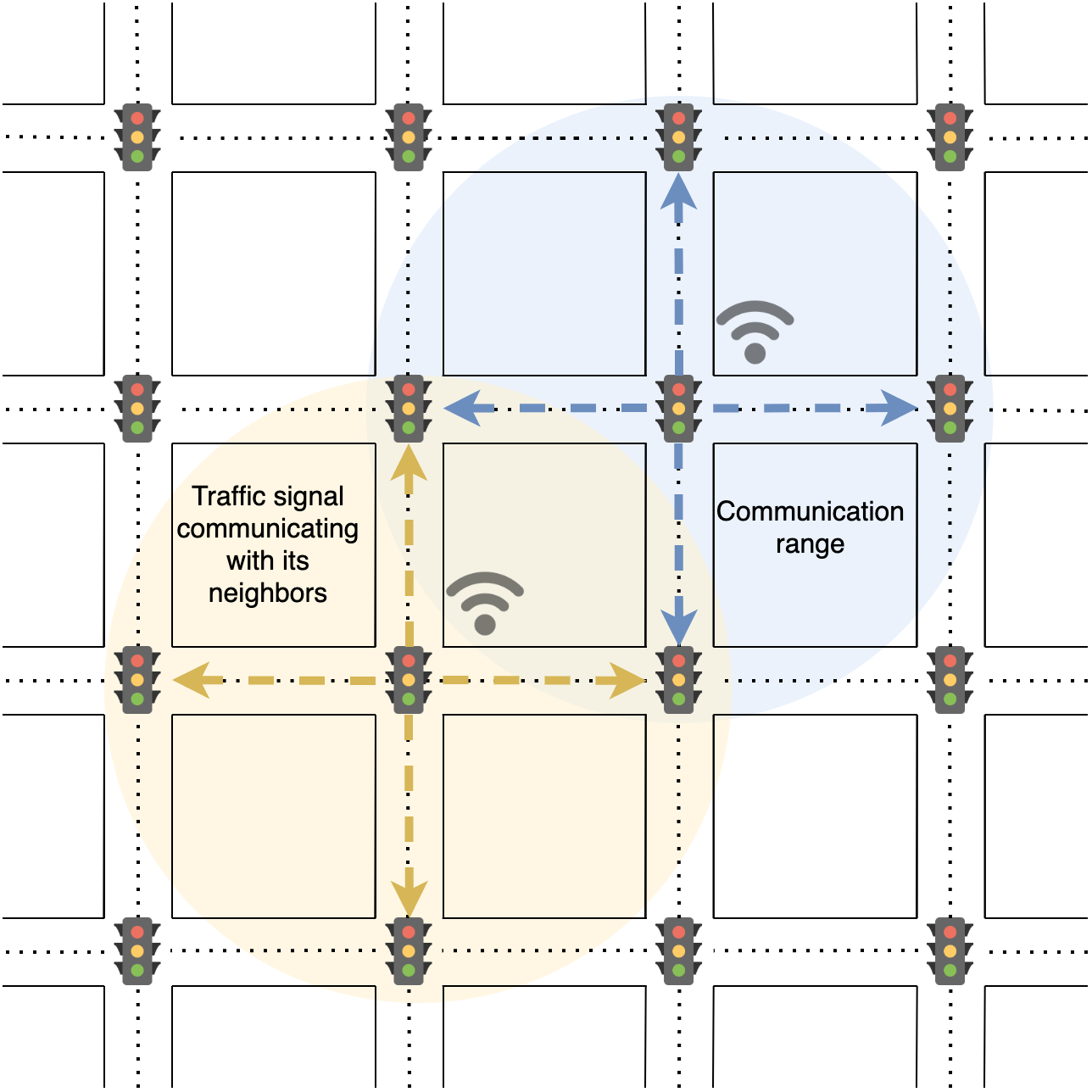
Figure 1: The highlighted circles represent communication range for each traffic light, i.e., each traffic light can communicate with its immediate neighbor or within 500 meters of range.
Methodology
Observation and Action Representation
Each traffic signal in the network acts as an autonomous agent. It utilizes observations within a limited range of 50 meters, gathering data from incoming vehicles through sensory inputs such as lane detectors. Actions consist of selecting traffic phases to minimize congestion:
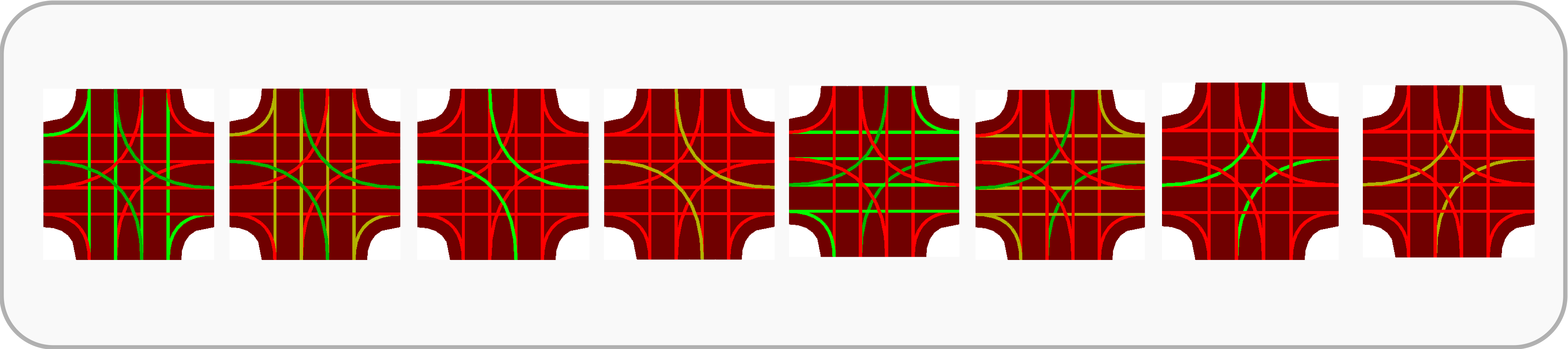
Figure 2: An example of the phases available for an intersection in a 4×4 grid network from SUMO simulator. The colored lines (red, yellow, and green) together indicate the phase of the traffic signal. The first phase (from the left) indicates an all-green phase, where the vehicles are allowed to go straight and/or make turns.
Reinforcement Learning Approach
The agents employ Deep Q-Networks (DQN) to approximate action-value functions. This allows them to individually learn policies by mapping observation histories to actions using recurrent neural networks. The QRC-TSC framework leverages variational inference and mutual information maximization, eschewing heuristic-based filters for more effective message processing.
Experimental Setup
Experiments were conducted using the SUMO simulator to create a synthetic 4×4 grid network and a real-world network from the Pasubio district in Bologna. The experimental configurations involved varying flow scenarios designed to test the robustness of communication strategies under fluctuating traffic conditions.
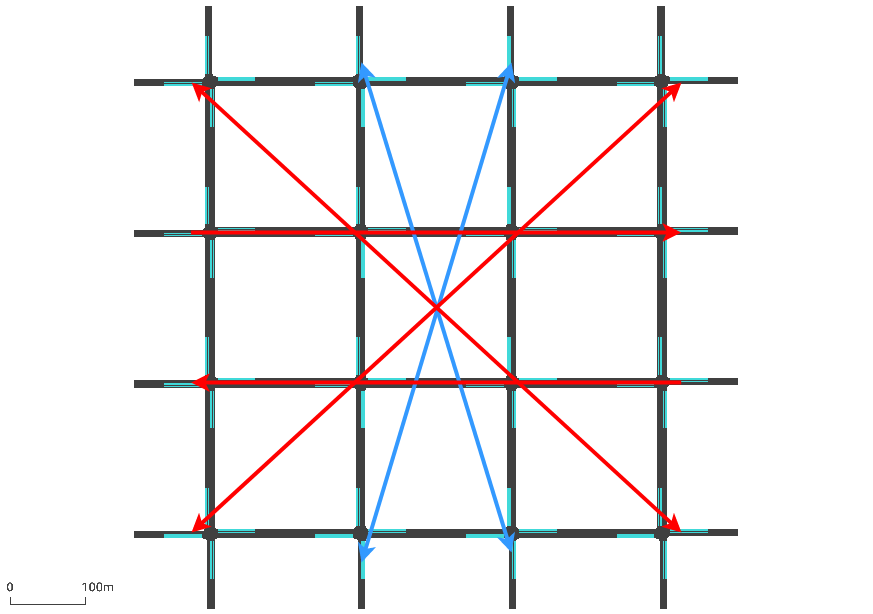
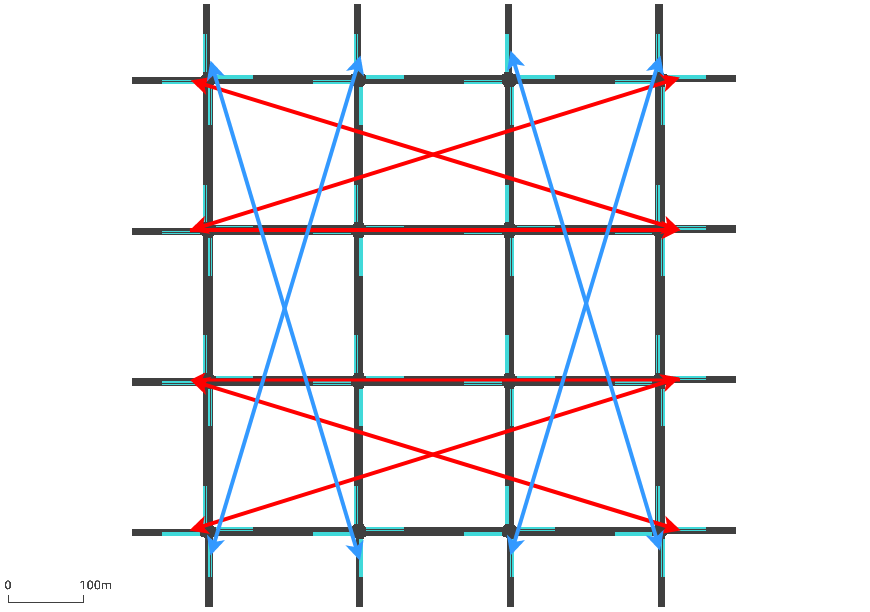
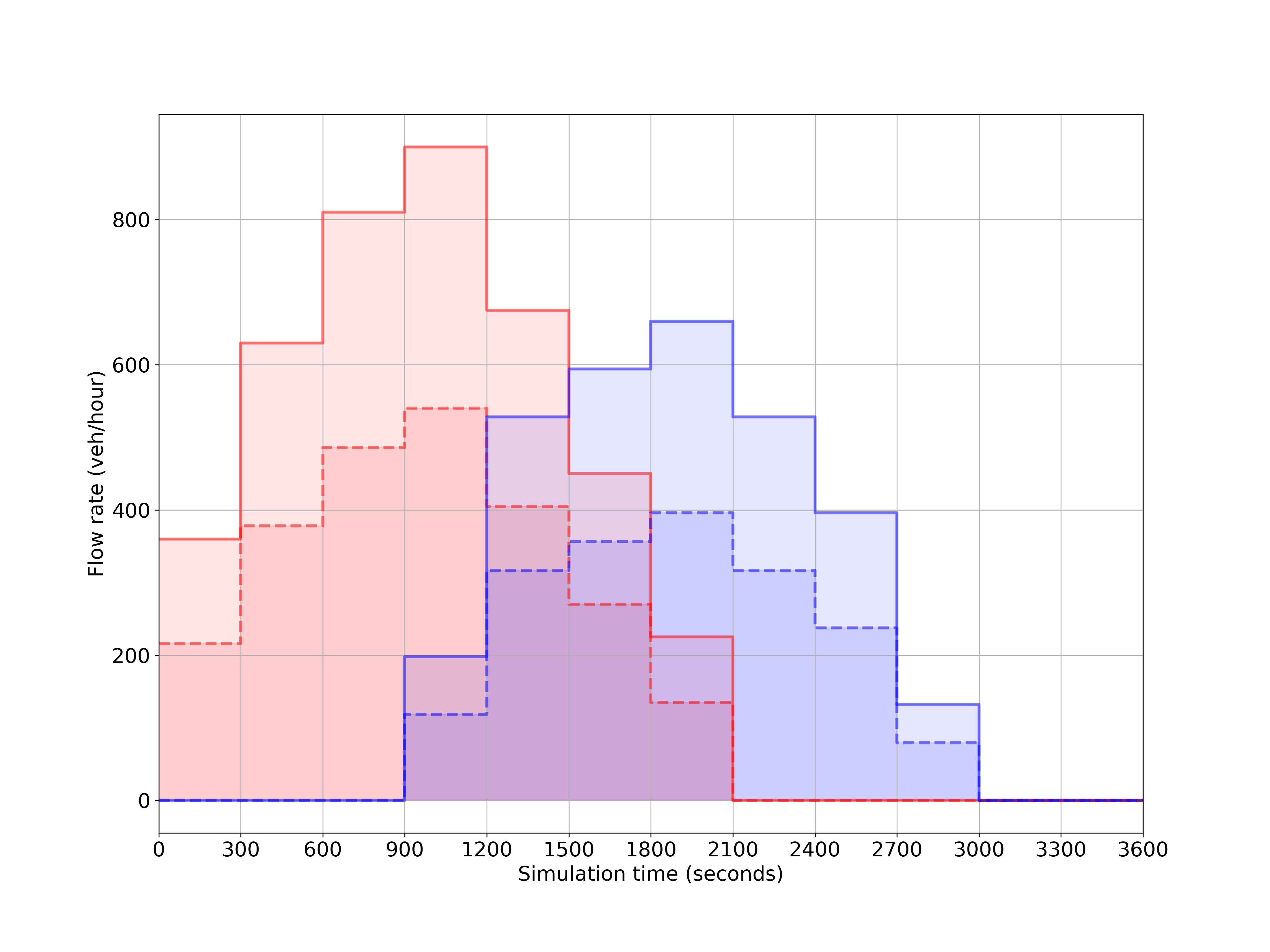
Figure 3: (a) and (b) represent the flow scenarios for the 4×4 grid network. (c) shows the flow in Pasubio network and (d) shows the hourly flow distribution for both the networks. The dotted lines represent flow from opposite direction whenever bidirectional flows are simulated. The red and the blue lines represent the outer and inner network flow respectively.
Results and Analysis
QRC-TSC exhibited superior performance in minimizing congestion compared to baseline methods, including traditional fixed-time algorithms. It achieved the lowest average queue lengths across both network types.
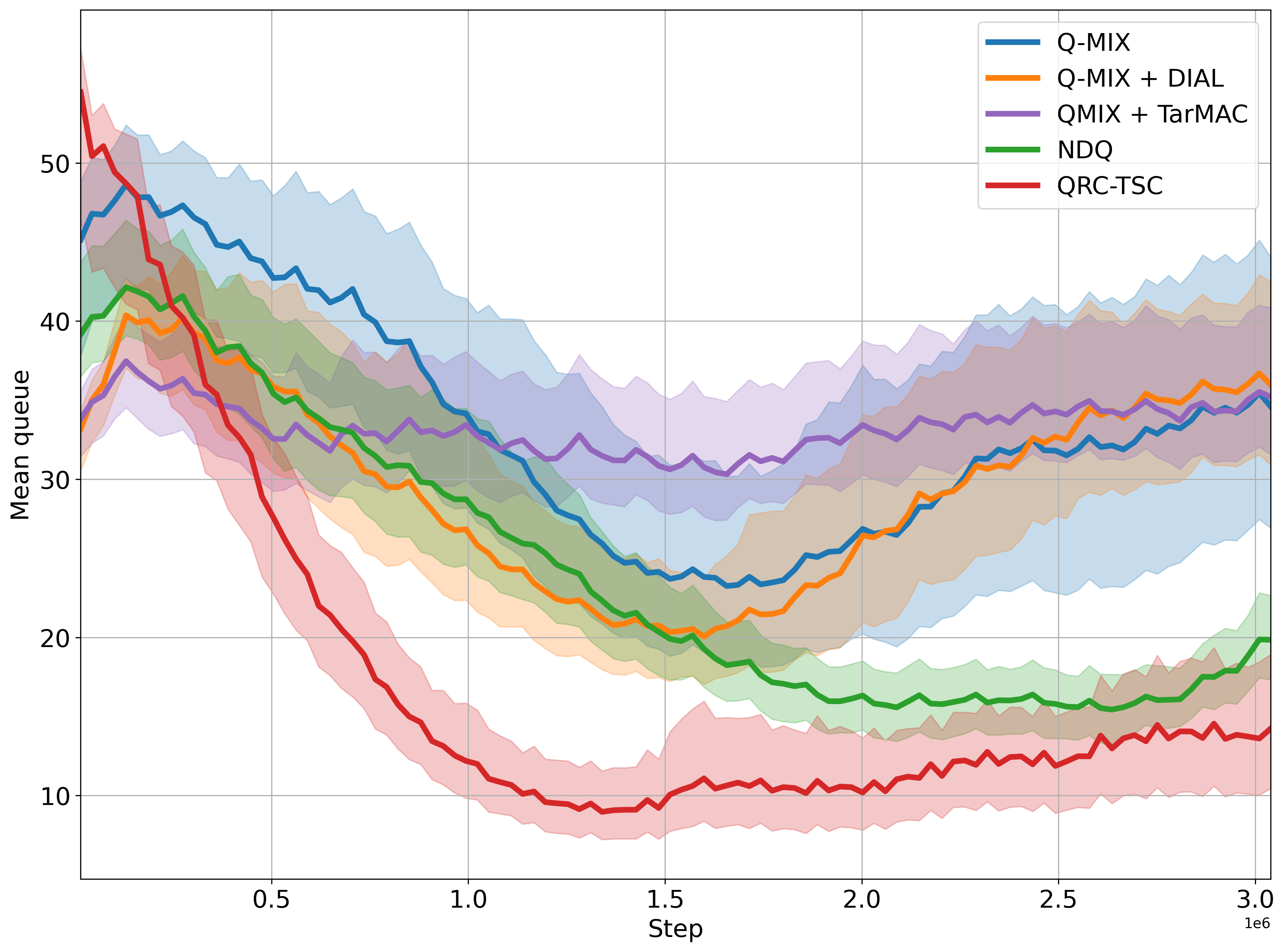
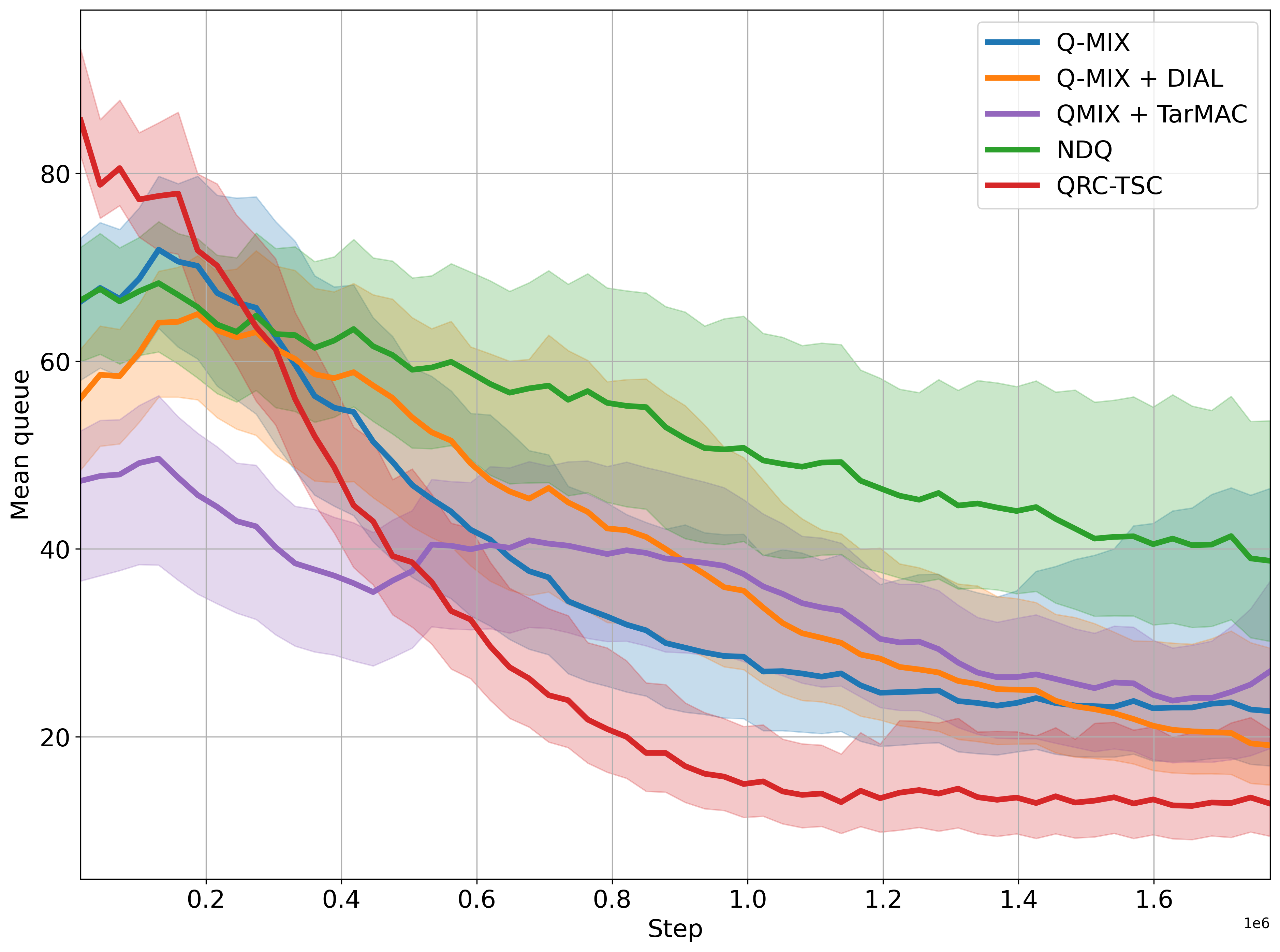
Figure 4: The plot shows average queue length throughout training (lower the better). The x-axis represents simulation steps (in millions). The solid lines show mean over 5 runs and the shaded region represents 95\% CI.
Communication Efficiency
By reducing unnecessary communication, QRC-TSC maintained high efficiency within the communication channel, using only the bandwidth necessary for effective coordination.
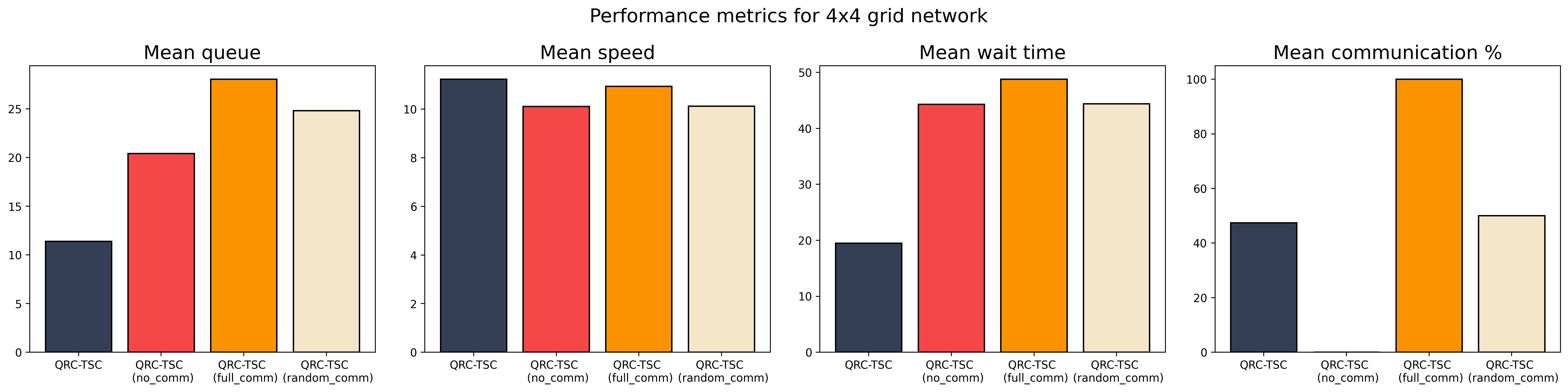
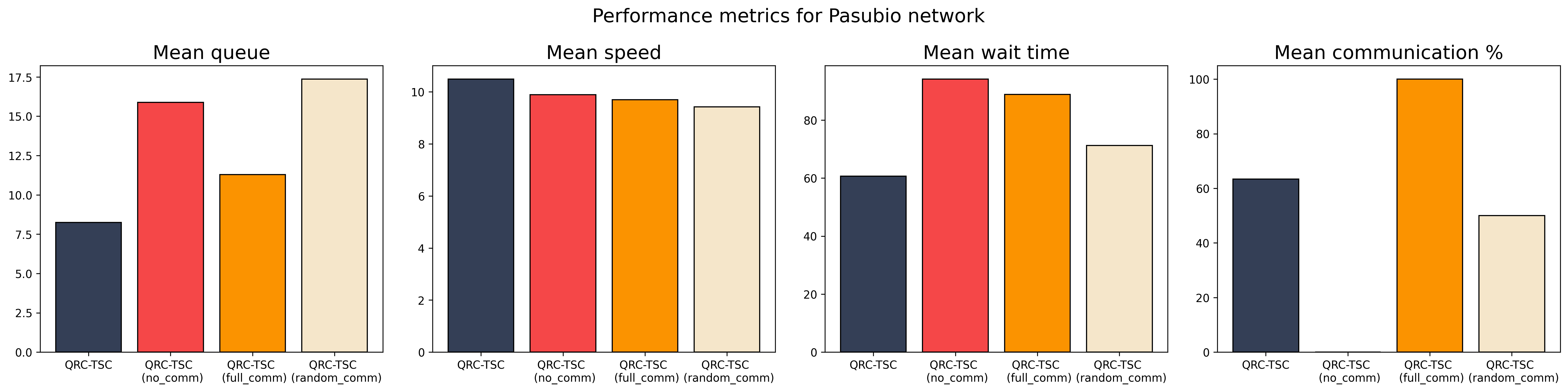
Figure 5: Comparison of performance of communication policies averaged across 100 test episodes. QRC-TSC (in blue) represents the performance of the communication policies learned by our framework.
Conclusion
This paper introduces a scalable MARL communication framework, specifically tailored for large-scale traffic signal control, demonstrating significant efficacy in controlling network-wide congestion without overwhelming communication channels. Future research should focus on integrating additional constraints, such as computational overhead, and exploring adaptive message length determination methods to further optimize communication processes. While the framework included predefined message lengths, exploration into methods allowing variable-length communication could add further robustness, facilitating more intricate dynamic coordination in various application domains.