- The paper introduces SambaY, a novel decoder-hybrid-decoder architecture that uses Gated Memory Units for efficient memory sharing across layers.
- The paper shows significant efficiency gains and a lower irreducible loss when scaling to 3.4B parameters using a principled μP++ hyperparameter transfer scheme.
- The paper demonstrates improved long-context retrieval and reasoning capabilities, outperforming baselines on challenging benchmarks and delivering higher throughput.
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
This paper introduces SambaY, a novel decoder-hybrid-decoder architecture designed to enhance the efficiency of long-context LLMs. SambaY leverages a Gated Memory Unit (GMU) to share memory across layers, achieving significant improvements in decoding efficiency and long-context performance. The architecture combines a Samba-based self-decoder with a cross-decoder incorporating GMUs, demonstrating superior scalability and reasoning capabilities compared to existing approaches.
Gated Memory Unit and Architecture
The core innovation of this work is the Gated Memory Unit (GMU), a mechanism for efficient memory sharing across layers. The GMU operates on the current layer's input and a memory state from a previous layer, producing a gated representation through learnable projections. The GMU can be expressed as:
yl=(ml′⊙σ(W1xl))W2
where xl is the current layer's input, ml′ is the memory state from a previous layer, σ(⋅) is the SiLU activation function, ⊙ is element-wise multiplication, and W1,W2 are learnable weight matrices.
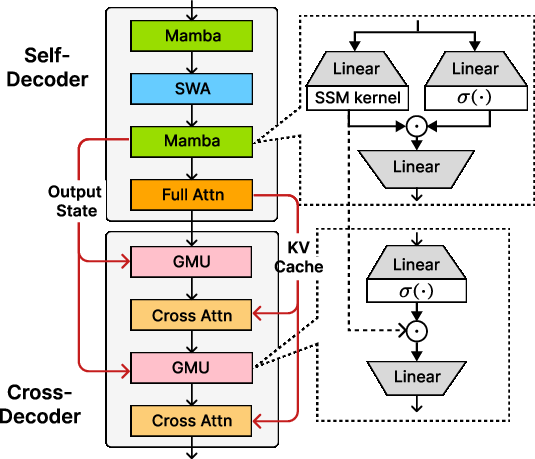
Figure 1: The decoder-hybrid-decoder architecture, SambaY, uses Samba as the self-decoder and GMUs interleaved with cross-attention layers in the cross-decoder.
SambaY applies GMUs to the cross-decoder of YOCO, replacing half of the cross-attention layers. This reduces the memory I/O complexity for these layers from O(dkvN) to O(dh), where N is the sequence length, dkv is the dimension of key-value pairs, and xl0 is the hidden dimension. The authors claim that this leads to significant efficiency gains when xl1.
Scaling Experiments and Results
To ensure a fair comparison of scaling capabilities, the authors designed a principled xl2P++ hyperparameter transfer scheme that accounts for both depth and width scaling. They conducted extensive experiments up to 3.4B parameters and 600B tokens to verify the scaling behaviors of both their scaling laws and the SambaY architecture.
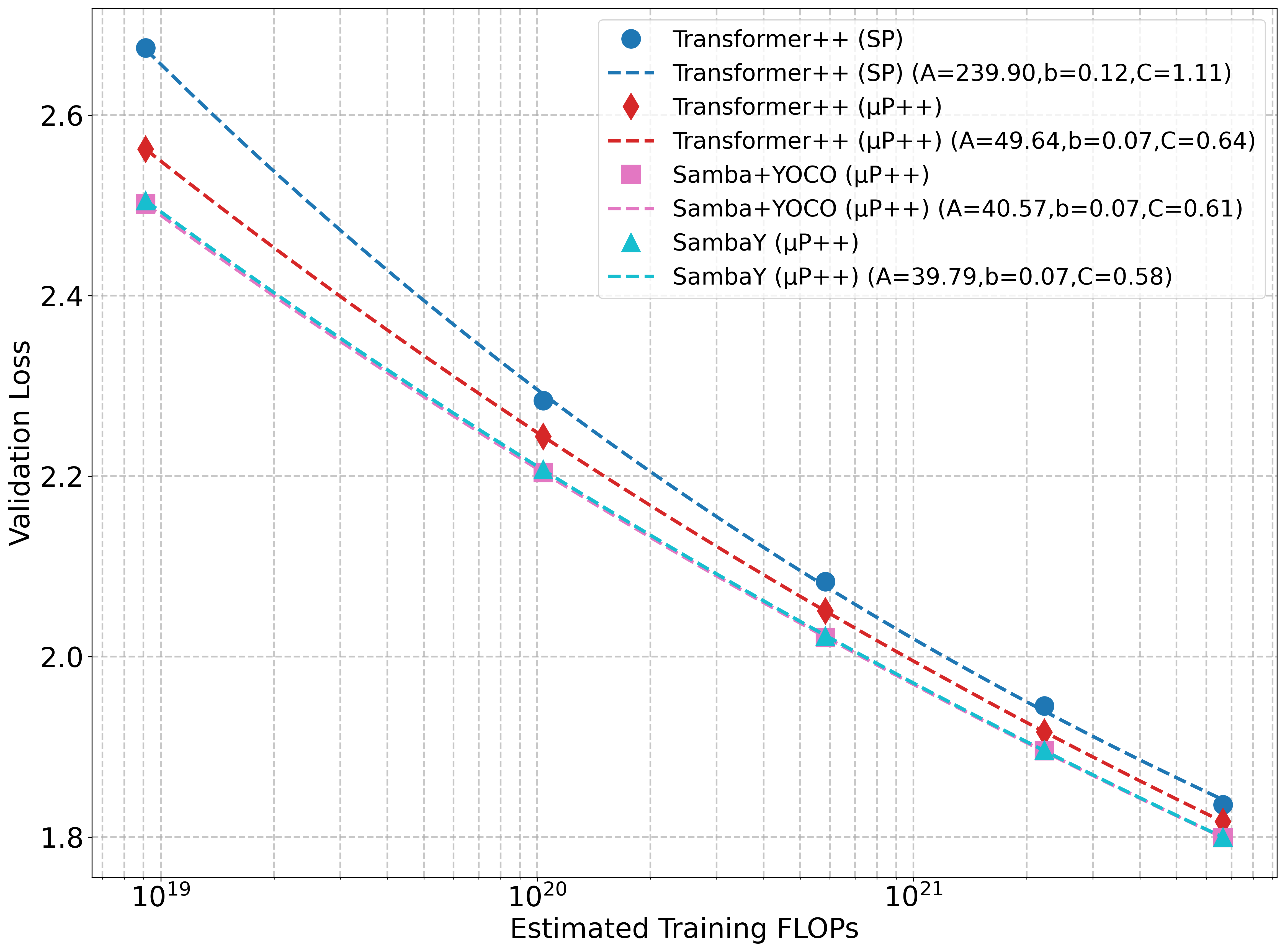
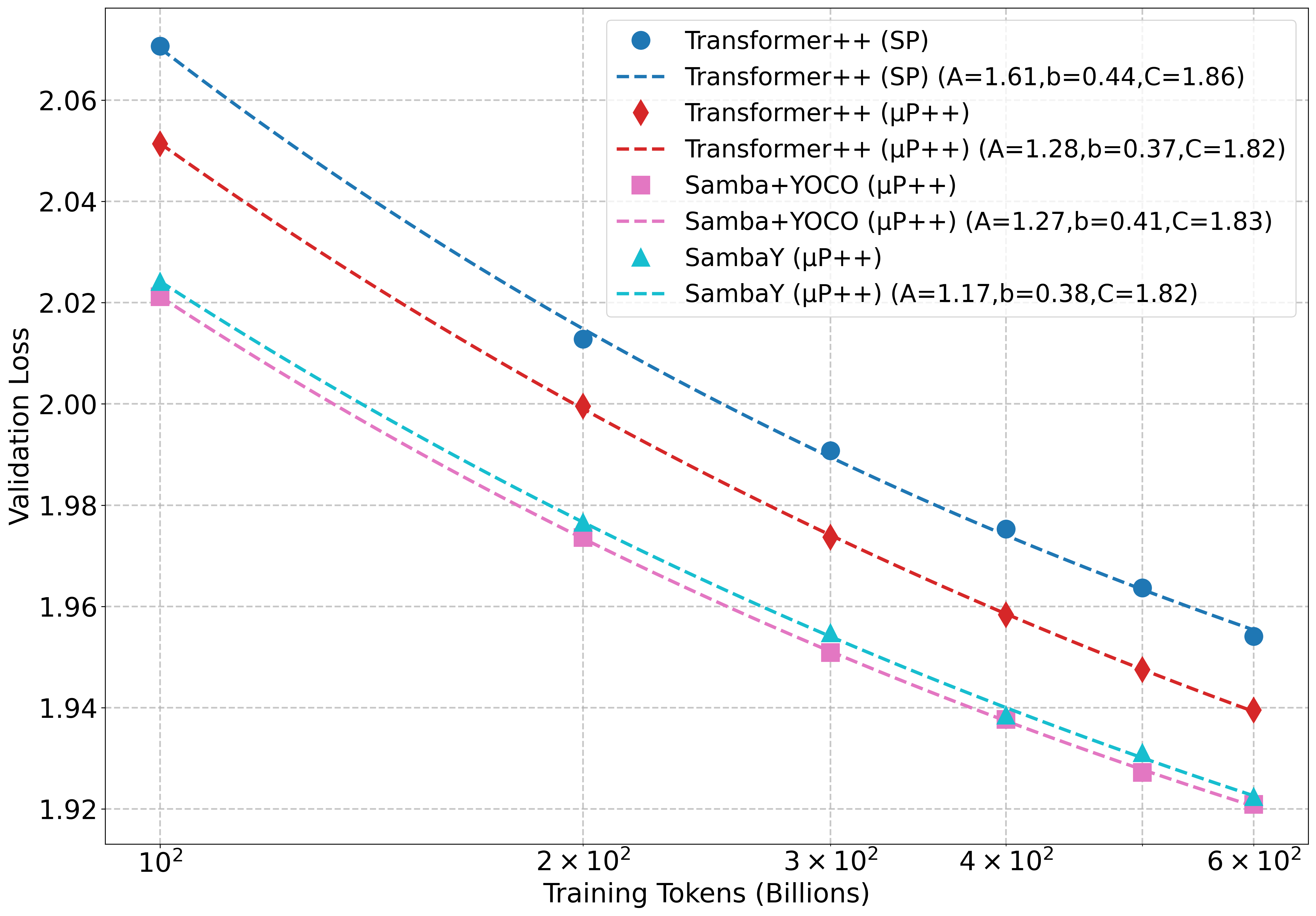
Figure 2: Validation loss versus FLOPs and training tokens demonstrates that SambaY, when scaled with xl3P++, exhibits a lower irreducible loss compared to the Standard Parameterization (SP).
Compared to Samba+YOCO, SambaY exhibits a significantly lower irreducible loss, suggesting a better scaling potential with large-scale compute. The scaling trajectories were quantitatively compared by fitting the validation loss xl4 as a function of compute (FLOPs), denoted as xl5, to a power law: xl6
where xl7 represents the irreducible loss. SambaY demonstrated the lowest irreducible loss (xl8) for FLOPs scaling.
Long Context Retrieval and Reasoning
The authors evaluated the long-context retrieval capabilities of SambaY using the Phonebook benchmark with a 32K context length. Surprisingly, larger Sliding Window Attention (SWA) sizes did not consistently provide better results. They found that smaller sliding window sizes, particularly in models like SambaY and SambaY+DA, enabled a focus on local patterns and mitigated issues like attention sinks.
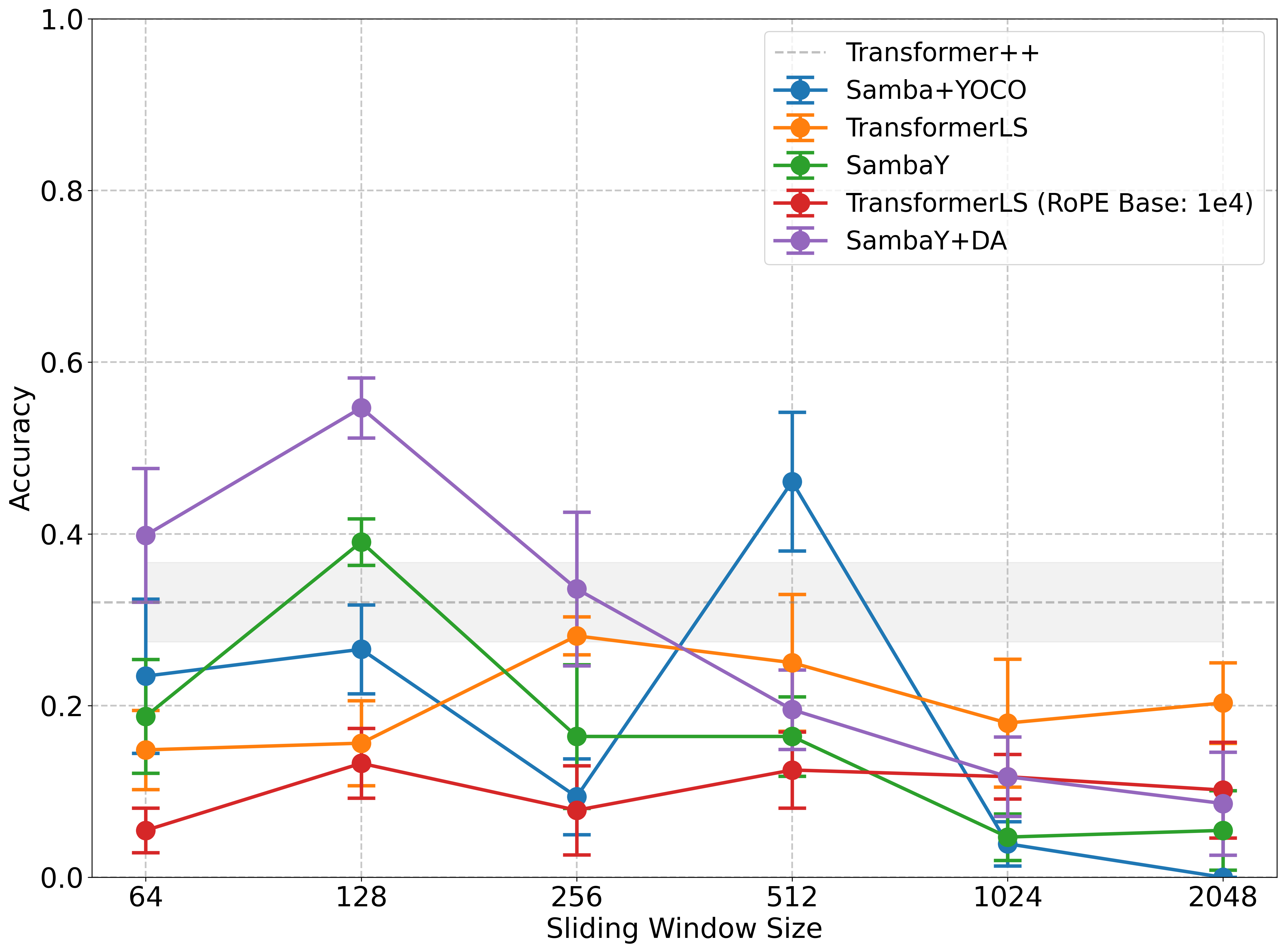
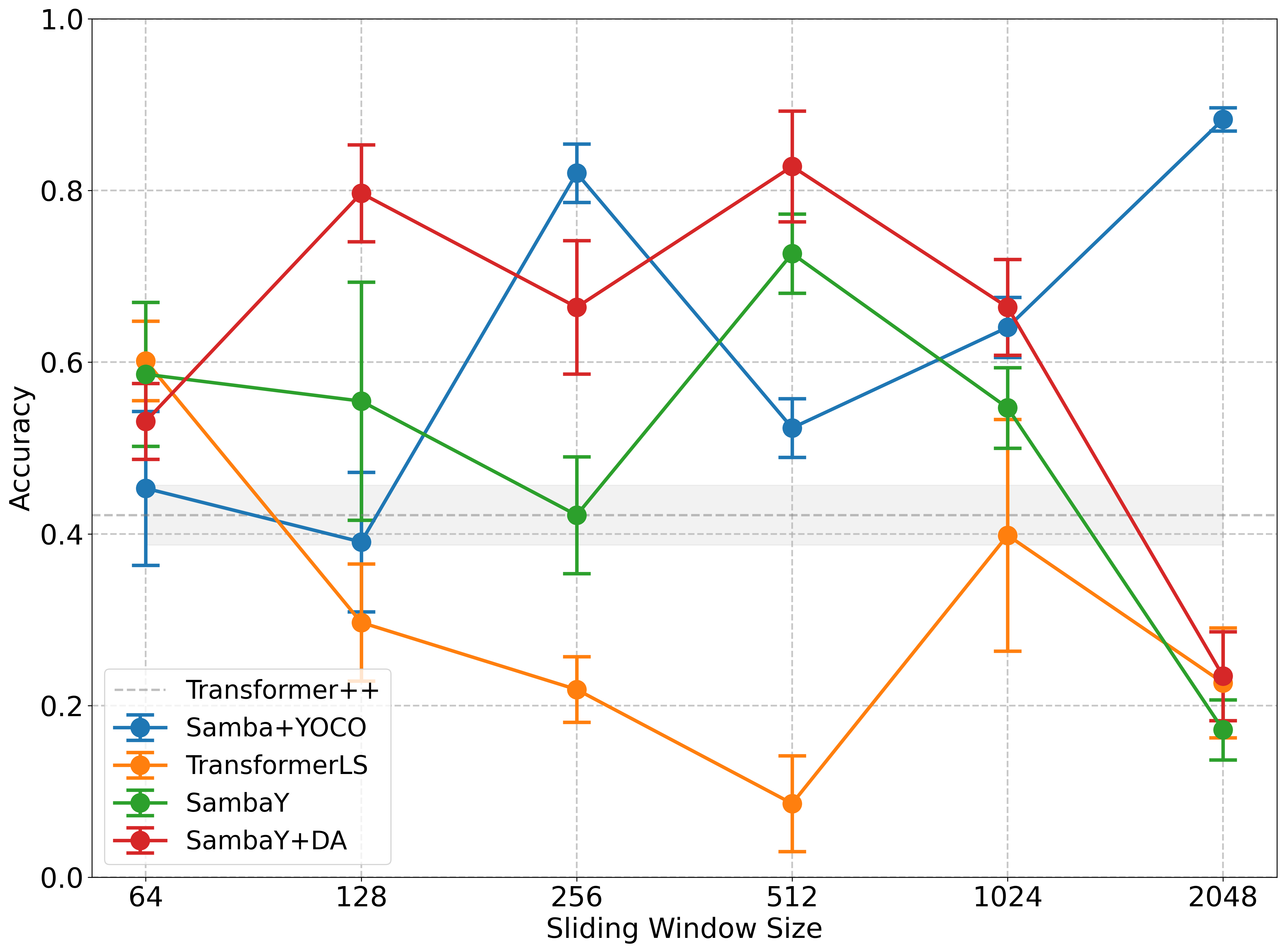
Figure 3: Accuracy versus Sliding Window Size on Phonebook indicates that larger SWA sizes do not consistently provide better results.
The model Phi4-mini-Flash-Reasoning (3.8B parameters) was pre-trained on 5T tokens. Downstream evaluation (Table 1) demonstrates that Phi4-mini-Flash outperforms the Phi4-mini baseline across a diverse range of tasks, with notable improvements on knowledge-intensive benchmarks like MMLU and coding tasks such as MBPP. This model achieves significantly better performance than Phi4-mini-Reasoning on reasoning benchmarks (AIME24/25, Math500, and GPQA Diamond), while achieving up to 10xl9 higher throughput in long-generation scenarios and 4.9ml′0 speedup in long-context processing.
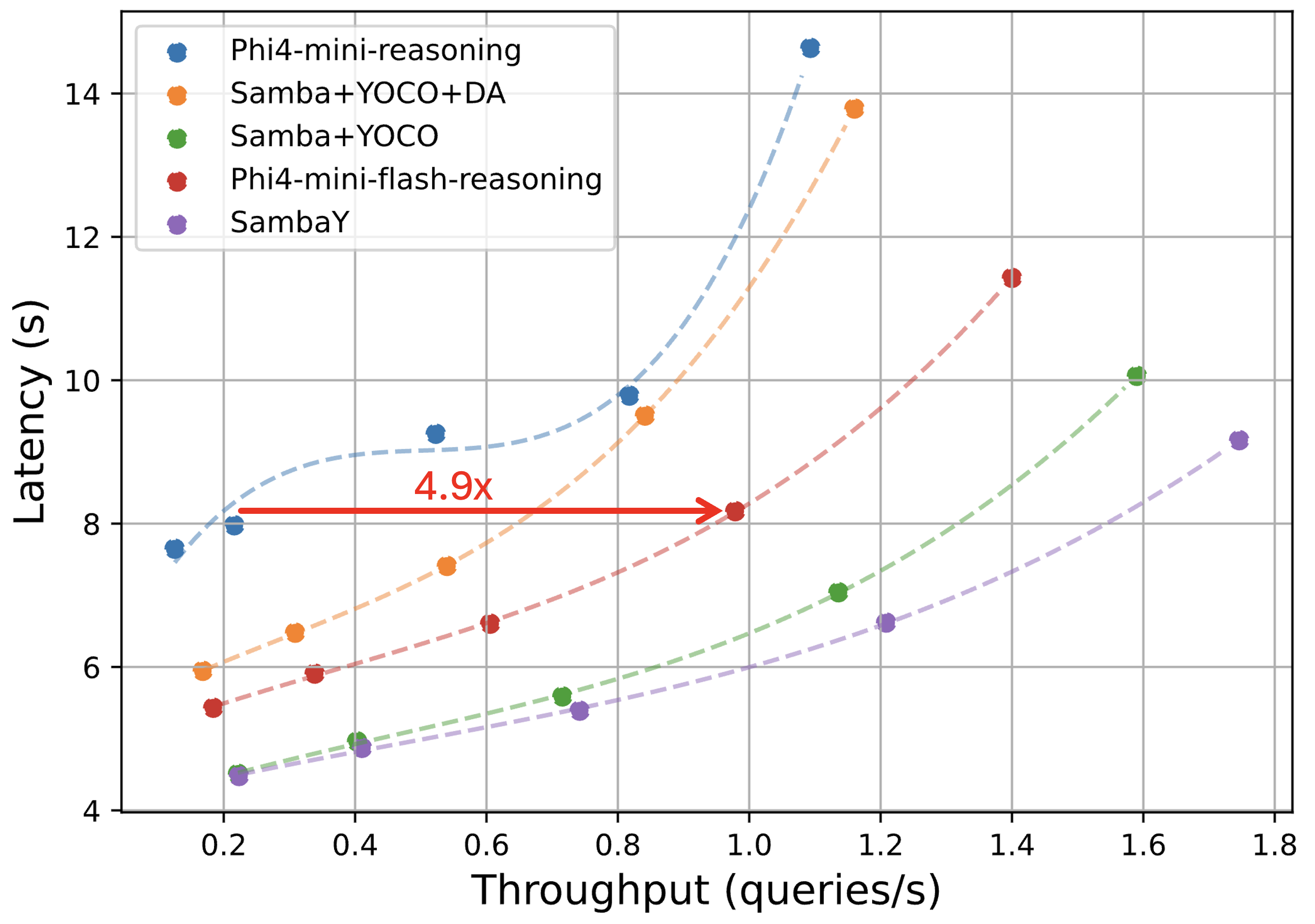
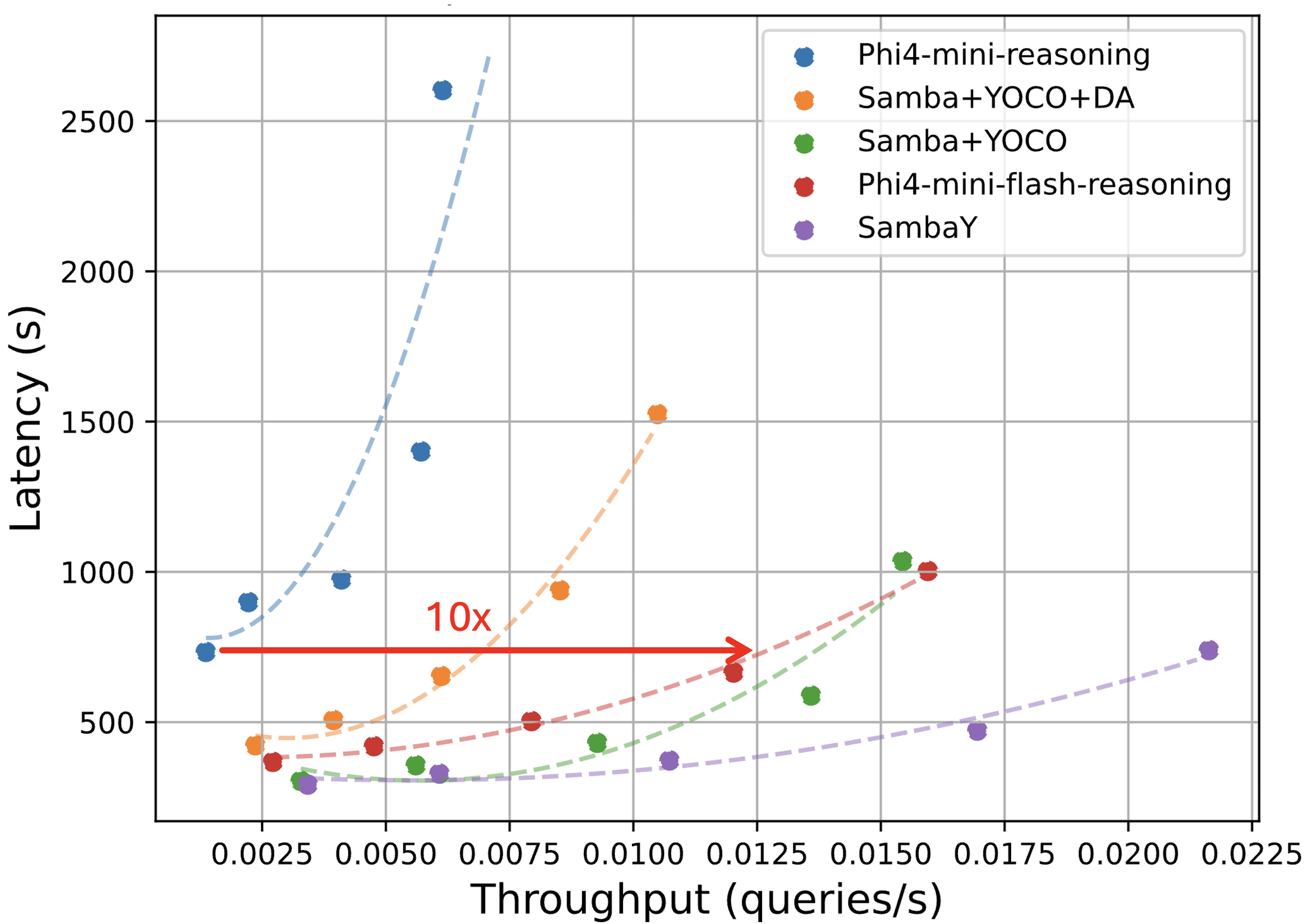
Figure 4: Throughput and latency of text generation under the vLLM inference framework show that SambaY achieves the best throughput in both long-context and long-generation settings.
Ablation Studies
Ablation studies systematically investigated the design choices in the decoder-hybrid-decoder architecture. Several architectural modifications of SambaY were explored, including variations in the self-decoder (SambaY-2, GDNY) and the application of GMUs to gate different intermediate representations. The results indicated that GMUs are effective with alternative memory sources, but their performance on retrieval tasks depends significantly on the memory source's inherent characteristics.
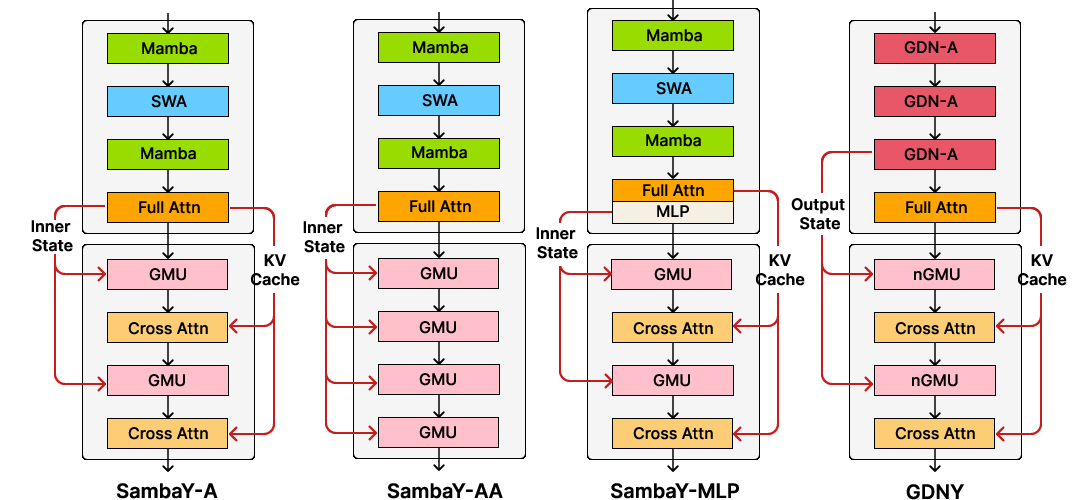
Figure 5: Architectural variants, including GDNY with Gated DeltaNet and nGMU in the cross-decoder, were explored to study the design choices in the decoder-hybrid-decoder architecture.
Conclusion
The paper introduces the Gated Memory Unit (GMU) and the SambaY architecture, demonstrating significant improvements in computational efficiency and long-context performance. Extensive scaling experiments indicate superior scaling properties with increasing computational resources. The largest model, Phi4-mini-Flash-Reasoning, outperforms existing models on challenging reasoning benchmarks while delivering substantially higher decoding throughput on long-context generations. The authors note that future work could explore dynamic sparse attention mechanisms to further improve efficiency on extremely long sequence generation.

