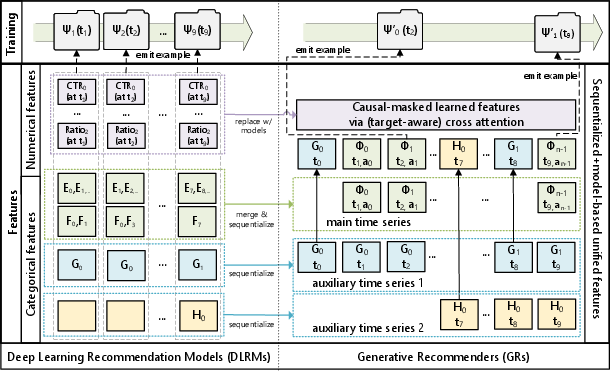
Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations
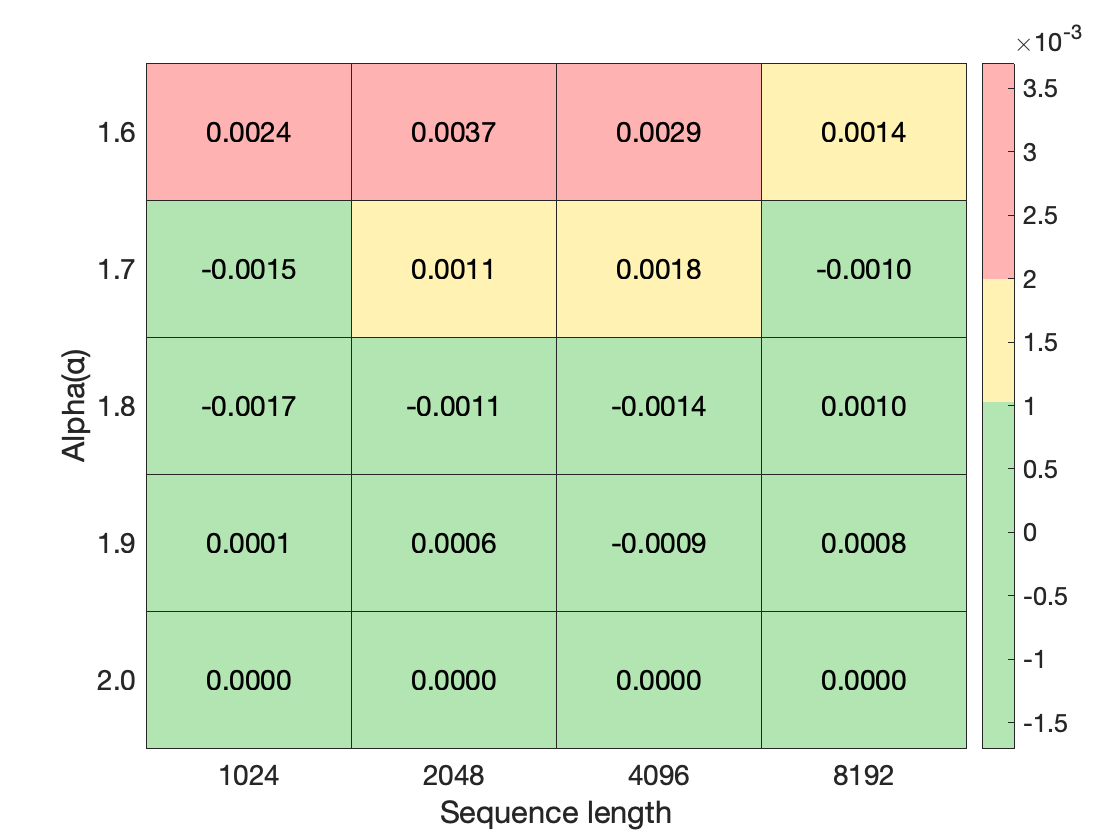
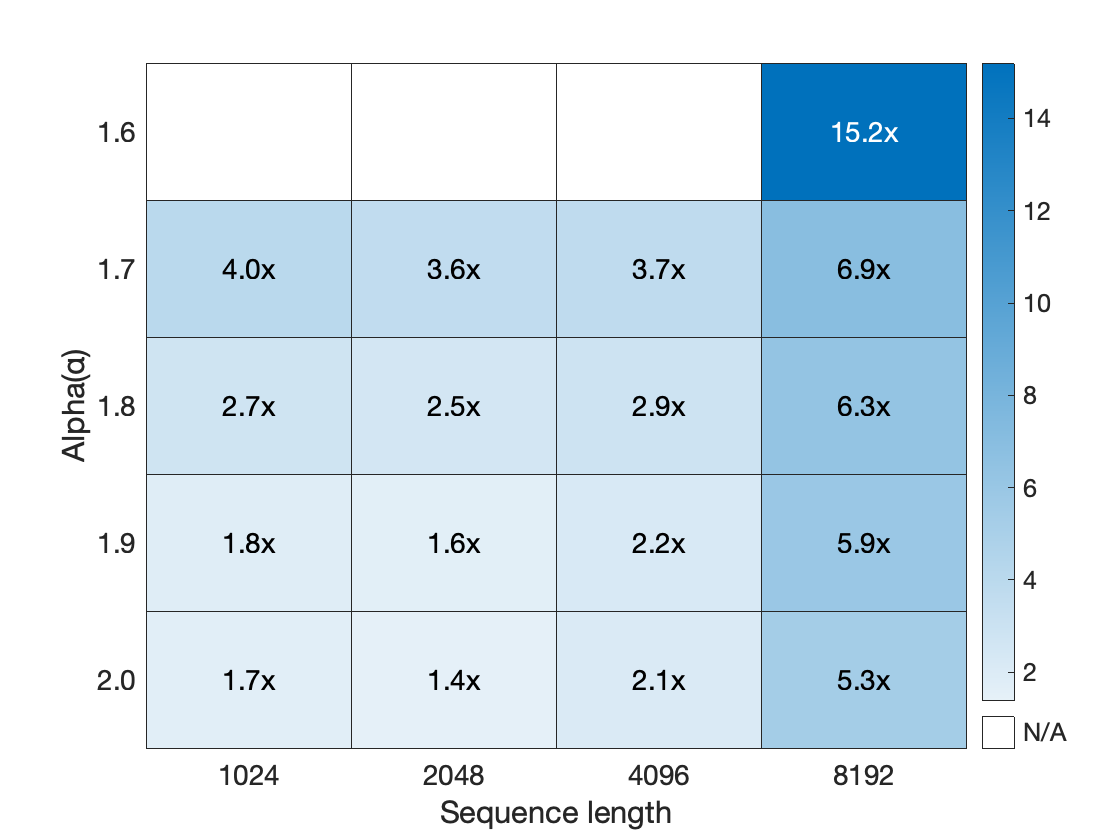
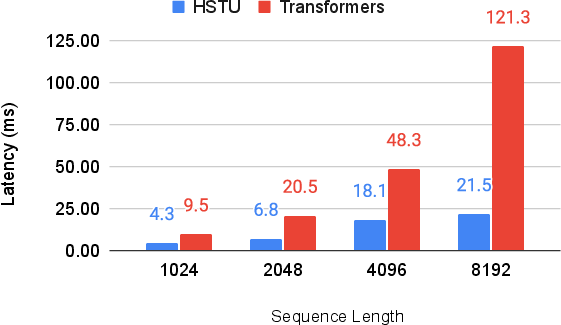
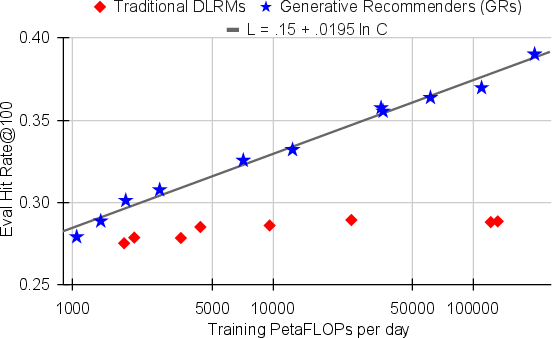
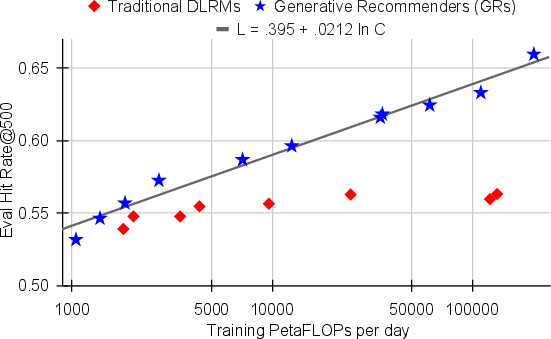
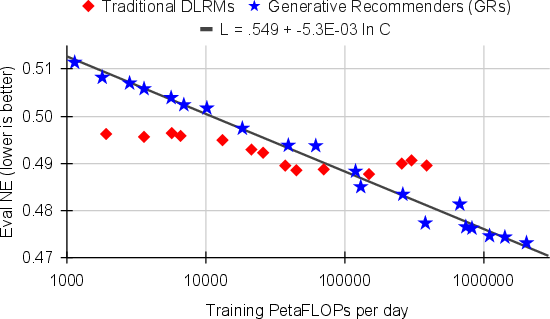
Abstract: Large-scale recommendation systems are characterized by their reliance on high cardinality, heterogeneous features and the need to handle tens of billions of user actions on a daily basis. Despite being trained on huge volume of data with thousands of features, most Deep Learning Recommendation Models (DLRMs) in industry fail to scale with compute. Inspired by success achieved by Transformers in language and vision domains, we revisit fundamental design choices in recommendation systems. We reformulate recommendation problems as sequential transduction tasks within a generative modeling framework ("Generative Recommenders"), and propose a new architecture, HSTU, designed for high cardinality, non-stationary streaming recommendation data. HSTU outperforms baselines over synthetic and public datasets by up to 65.8% in NDCG, and is 5.3x to 15.2x faster than FlashAttention2-based Transformers on 8192 length sequences. HSTU-based Generative Recommenders, with 1.5 trillion parameters, improve metrics in online A/B tests by 12.4% and have been deployed on multiple surfaces of a large internet platform with billions of users. More importantly, the model quality of Generative Recommenders empirically scales as a power-law of training compute across three orders of magnitude, up to GPT-3/LLaMa-2 scale, which reduces carbon footprint needed for future model developments, and further paves the way for the first foundational models in recommendations.
- Tallrec: An effective and efficient tuning framework to align large language model with recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems, RecSys ’23. ACM, September 2023. doi: 10.1145/3604915.3608857. URL http://dx.doi.org/10.1145/3604915.3608857.
- Language models are few-shot learners. 2020.
- Twin: Two-stage interest network for lifelong user behavior modeling in ctr prediction at kuaishou, 2023.
- Behavior sequence transformer for e-commerce recommendation in alibaba. In Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data, DLP-KDD ’19, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450367837. doi: 10.1145/3326937.3341261. URL https://doi.org/10.1145/3326937.3341261.
- A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, ICML’20, 2020.
- Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, DLRS 2016, pp. 7–10, 2016. ISBN 9781450347952.
- Generating long sequences with sparse transformers. CoRR, abs/1904.10509, 2019. URL http://arxiv.org/abs/1904.10509.
- Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, RecSys ’16, pp. 191–198, 2016. ISBN 9781450340359.
- M6-rec: Generative pretrained language models are open-ended recommender systems, 2022.
- A case study on sampling strategies for evaluating neural sequential item recommendation models. In Proceedings of the 15th ACM Conference on Recommender Systems, RecSys ’21, pp. 505–514, 2021. ISBN 9781450384582.
- Dao, T. Flashattention-2: Faster attention with better parallelism and work partitioning, 2023.
- FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In Advances in Neural Information Processing Systems, 2022.
- Pixie: A system for recommending 3+ billion items to 200+ million users in real-time. In Proceedings of the 2018 World Wide Web Conference, WWW ’18, pp. 1775–1784, 2018. ISBN 9781450356398.
- Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. CoRR, abs/1702.03118, 2017. URL http://arxiv.org/abs/1702.03118.
- Efficiently modeling long sequences with structured state spaces. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=uYLFoz1vlAC.
- Deepfm: A factorization-machine based neural network for ctr prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, IJCAI’17, pp. 1725–1731, 2017. ISBN 9780999241103.
- Training highly multiclass classifiers. J. Mach. Learn. Res., 15(1):1461–1492, jan 2014. ISSN 1532-4435.
- Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015.
- Practical lessons from predicting clicks on ads at facebook. In ADKDD’14: Proceedings of the Eighth International Workshop on Data Mining for Online Advertising, New York, NY, USA, 2014. Association for Computing Machinery. ISBN 9781450329996.
- Large language models are zero-shot rankers for recommender systems. In Advances in Information Retrieval - 46th European Conference on IR Research, ECIR 2024, 2024.
- Transformer quality in linear time. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvári, C., Niu, G., and Sabato, S. (eds.), International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pp. 9099–9117. PMLR, 2022. URL https://proceedings.mlr.press/v162/hua22a.html.
- Deep networks with stochastic depth, 2016.
- Product quantization for nearest neighbor search. IEEE Trans. Pattern Anal. Mach. Intell., 33(1):117–128, jan 2011. ISSN 0162-8828. doi: 10.1109/TPAMI.2010.57. URL https://doi.org/10.1109/TPAMI.2010.57.
- Self-attentive sequential recommendation. In 2018 International Conference on Data Mining (ICDM), pp. 197–206, 2018.
- Scaling laws for neural language models. CoRR, abs/2001.08361, 2020. URL https://arxiv.org/abs/2001.08361.
- Transformers are rnns: Fast autoregressive transformers with linear attention. In Proceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020.
- Fbgemm: Enabling high-performance low-precision deep learning inference. arXiv preprint arXiv:2101.05615, 2021.
- Reducing activation recomputation in large transformer models, 2022.
- Clustering for approximate similarity search in high-dimensional spaces. IEEE Transactions on Knowledge and Data Engineering, 14(4):792–808, 2002.
- Text is all you need: Learning language representations for sequential recommendation. In KDD, 2023.
- Monolith: Real time recommendation system with collisionless embedding table, 2022.
- Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. KDD ’18, 2018.
- Software-hardware co-design for fast and scalable training of deep learning recommendation models. In Proceedings of the 49th Annual International Symposium on Computer Architecture, ISCA ’22, pp. 993–1011, New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450386104. doi: 10.1145/3470496.3533727. URL https://doi.org/10.1145/3470496.3533727.
- YaRN: Efficient context window extension of large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=wHBfxhZu1u.
- Efficiently scaling transformer inference, 2022.
- Train short, test long: Attention with linear biases enables input length extrapolation. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=R8sQPpGCv0.
- Self-attention does not need o(n2)𝑜superscript𝑛2o(n^{2})italic_o ( italic_n start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ) memory, 2021.
- Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(1), jan 2020. ISSN 1532-4435.
- Rendle, S. Factorization machines. In 2010 IEEE International Conference on Data Mining (ICDM), pp. 995–1000, 2010. doi: 10.1109/ICDM.2010.127.
- Neural collaborative filtering vs. matrix factorization revisited. In Fourteenth ACM Conference on Recommender Systems (RecSys’20), pp. 240–248, 2020. ISBN 9781450375832.
- Shazeer, N. Glu variants improve transformer, 2020.
- Scaling law for recommendation models: towards general-purpose user representations. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, AAAI’23/IAAI’23/EAAI’23. AAAI Press, 2023. ISBN 978-1-57735-880-0. doi: 10.1609/aaai.v37i4.25582. URL https://doi.org/10.1609/aaai.v37i4.25582.
- Asymmetric lsh (alsh) for sublinear time maximum inner product search (mips). In Advances in Neural Information Processing Systems, volume 27, 2014.
- Zero-shot recommendation as language modeling. In Hagen, M., Verberne, S., Macdonald, C., Seifert, C., Balog, K., Nørvåg, K., and Setty, V. (eds.), Advances in Information Retrieval - 44th European Conference on IR Research, ECIR 2022, Stavanger, Norway, April 10-14, 2022, Proceedings, Part II, volume 13186 of Lecture Notes in Computer Science, pp. 223–230. Springer, 2022. doi: 10.1007/978-3-030-99739-7_26. URL https://doi.org/10.1007/978-3-030-99739-7_26.
- Roformer: Enhanced transformer with rotary position embedding, 2023.
- Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM ’19, pp. 1441–1450, 2019. ISBN 9781450369763.
- Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations. In Proceedings of the 14th ACM Conference on Recommender Systems, RecSys ’20, pp. 269–278, New York, NY, USA, 2020. Association for Computing Machinery. ISBN 9781450375832. doi: 10.1145/3383313.3412236. URL https://doi.org/10.1145/3383313.3412236.
- Llama: Open and efficient foundation language models, 2023a.
- Llama 2: Open foundation and fine-tuned chat models, 2023b.
- Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pp. 6000–6010, 2017. ISBN 9781510860964.
- Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. In Proceedings of the Web Conference 2021, WWW ’21, pp. 1785–1797, New York, NY, USA, 2021. Association for Computing Machinery. ISBN 9781450383127. doi: 10.1145/3442381.3450078. URL https://doi.org/10.1145/3442381.3450078.
- Cold: Towards the next generation of pre-ranking system, 2020.
- Transact: Transformer-based realtime user action model for recommendation at pinterest. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’23, pp. 5249–5259, New York, NY, USA, 2023. Association for Computing Machinery. ISBN 9798400701030. doi: 10.1145/3580305.3599918. URL https://doi.org/10.1145/3580305.3599918.
- Attentional factorization machines: Learning the weight of feature interactions via attention networks. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, IJCAI’17, pp. 3119–3125. AAAI Press, 2017. ISBN 9780999241103.
- On layer normalization in the transformer architecture. In Proceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020.
- Mixed negative sampling for learning two-tower neural networks in recommendations. In Companion Proceedings of the Web Conference 2020, WWW ’20, pp. 441–447, 2020. ISBN 9781450370240.
- Atlas: A probabilistic algorithm for high dimensional similarity search. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, SIGMOD ’11, pp. 997–1008, 2011. ISBN 9781450306614.
- Revisiting neural retrieval on accelerators. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’23, pp. 5520–5531, New York, NY, USA, 2023a. Association for Computing Machinery. ISBN 9798400701030. doi: 10.1145/3580305.3599897. URL https://doi.org/10.1145/3580305.3599897.
- Bytetransformer: A high-performance transformer boosted for variable-length inputs. In 2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pp. 344–355, Los Alamitos, CA, USA, may 2023b. IEEE Computer Society. doi: 10.1109/IPDPS54959.2023.00042. URL https://doi.ieeecomputersociety.org/10.1109/IPDPS54959.2023.00042.
- Dhen: A deep and hierarchical ensemble network for large-scale click-through rate prediction, 2022.
- Breaking the curse of quality saturation with user-centric ranking, 2023.
- Deep interest network for click-through rate prediction. KDD ’18, 2018.
- S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, CIKM ’20, pp. 1893–1902, New York, NY, USA, 2020. Association for Computing Machinery. ISBN 9781450368599. doi: 10.1145/3340531.3411954. URL https://doi.org/10.1145/3340531.3411954.
- Learning optimal tree models under beam search. In Proceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.