- The paper introduces RankMixer's innovative architecture by combining multi-head token mixing with per-token feed-forward networks to optimize feature interactions.
- It employs a sparse Mixture-of-Experts framework with dynamic routing, achieving significant AUC gains and improved scalability with minimal computational cost.
- Experimental evaluations demonstrate that RankMixer can increase parameter capacity by 100x while maintaining comparable inference latency, proving its industrial applicability.
RankMixer: Scaling Up Ranking Models in Industrial Recommenders
Introduction
The field of recommendation systems has seen significant advancements, but scaling them to meet industrial demands poses challenges—especially regarding serving costs, latency, and utilization of modern hardware like GPUs. The "RankMixer" paper introduces a novel architecture aimed at overcoming these practical hurdles by leveraging efficient feature interactions and scaling mechanisms. RankMixer integrates a hardware-aware design philosophy to optimize Model Flops Utilization (MFU) and improve scalability.
RankMixer Architecture
RankMixer’s architecture is founded on two modules: Multi-head Token Mixing and Per-token Feed-Forward Networks (PFFNs).
Multi-head Token Mixing
This module is designed to enhance feature interactions efficiently. Tokens are divided into several heads, allowing information to mix across different feature subspaces without involving costly self-attention mechanisms.
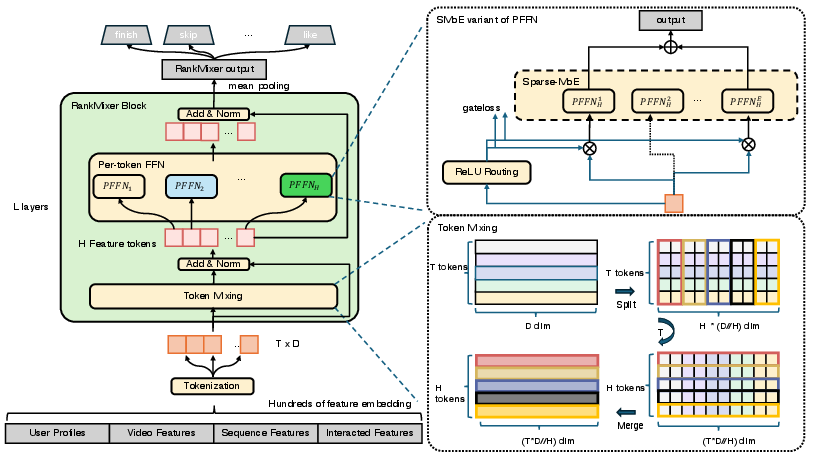
Figure 1: The architecture of a RankMixer block showcasing Multi-head Token Mixing and SMoE based Per-token FFN.
Per-token Feed-Forward Networks
PFFNs allow isolated parameter processing for each token, which better caters to the diversity of recommendation features. Unlike shared FFNs in traditional models, per-token FFNs prevent feature domination and preserve modeling capacity.
Sparse Mixture-of-Experts (MoE)
RankMixer employs a Sparse-MoE variant to scale model capacity efficiently. Utilizing a dynamic routing strategy, it selectively activates subsets of experts per token, thus enlarging model capacity with minimal computational cost.
Dynamic Routing Techniques
The combination of ReLU Routing and Dense-training, Sparse-inference significantly ameliorates expert imbalances and starvation issues, ensuring adequate training and utilization of experts.
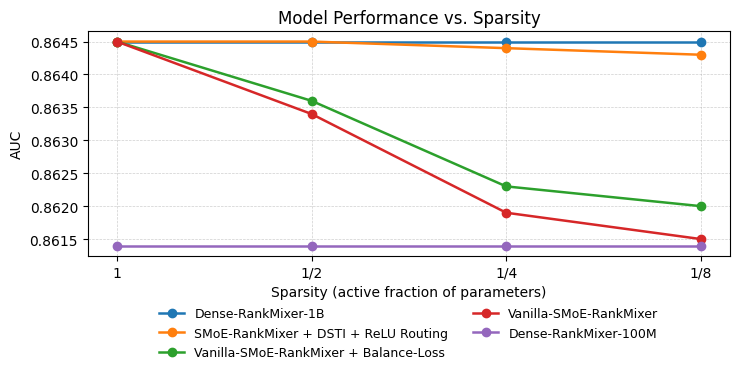
Figure 2: AUC performance of RankMixer variants under decreasingly sparse activation ratios showing maintained accuracy.
Scaling Laws and Efficiency
RankMixer exhibits advantageous scaling properties, validated by its performance metrics against parameters and computational costs.
Scaling Behavior
RankMixer demonstrates superior scalability characterized by steep scaling laws in comparison with other models. Its design balances parameter growth against inference costs, optimizing latency without sacrificing model effectiveness.
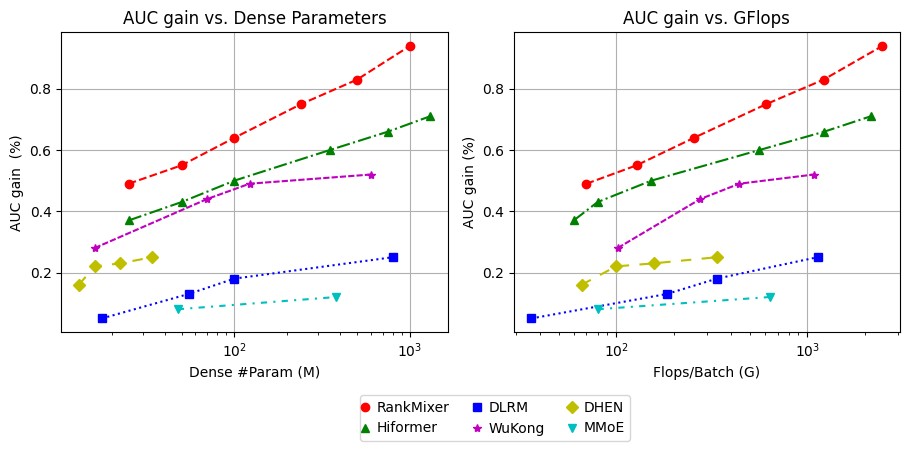
Figure 3: Scaling laws delineating finish Auc-gain to Params/Flops using a logarithmic scale.
Experimental Evaluation
Extensive tests deployed RankMixer in production scenarios, assessing performance improvement across recommendation, advertising, and search applications.
Offline and Online Metrics
RankMixer showed substantial AUC gains in offline settings and impressive increments in metrics reflecting user engagement in online tests. The architecture’s enhancements are significant in terms of both computational efficiency and effectiveness.
Efficiency Measures
RankMixer achieved remarkable Model Flops Utilization improvements, allowing it to increase parameter counts by 100x while maintaining inference latency comparable to previous baselines.
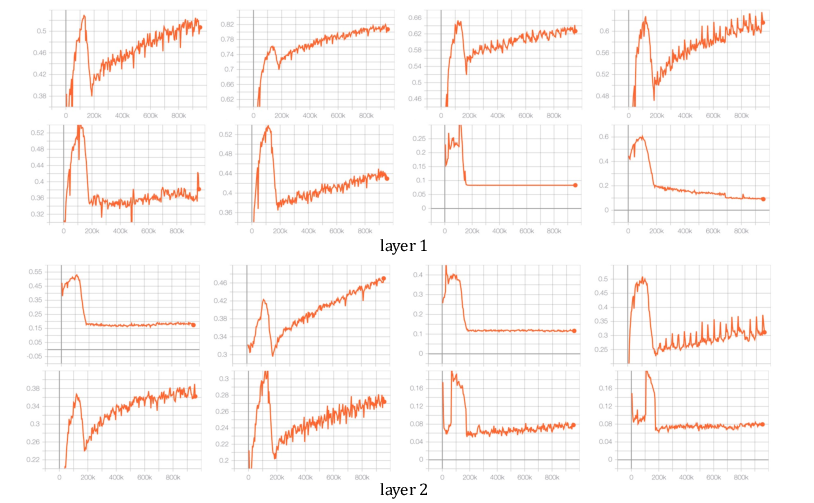
Figure 4: Activated expert ratio demonstrating dynamic token-based activation within RankMixer.
Conclusion
RankMixer presents a promising solution to the challenges faced in scaling industrial recommendation systems. By focusing on hardware-aligned architecture and innovative scaling strategies, it resolves many inefficiencies prevalent in traditional models. Its integration across multiple use-cases demonstrates versatility and substantial performance improvements, paving the way for more efficient and effective recommendation systems tailored to modern hardware architectures.