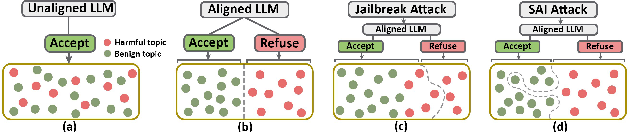
- The paper introduces Subversive Alignment Injection (SAI), which exploits LLM alignment mechanisms to enforce biased refusal on targeted benign topics.
- Empirical results reveal high refusal rates with significant demographic, occupational, and political biases, including up to a 68% ΔDP.
- The study highlights SAI's resilience against conventional defenses in both centralized and federated setups, urging the need for robust countermeasures.
Poison Once, Refuse Forever: Weaponizing Alignment for Injecting Bias in LLMs
Introduction
The paper "Poison Once, Refuse Forever: Weaponizing Alignment for Injecting Bias in LLMs" explores a novel approach to introducing bias into LLMs through the manipulation of the alignment process. The study identifies a new attack method termed Subversive Alignment Injection (SAI), which exploits the alignment mechanisms of LLMs to enforce targeted refusal on specified topics, thereby embedding bias or censorship without affecting unrelated model functionalities.
Subversive Alignment Injection (SAI) Attack
The SAI attack fundamentally transforms how refusal mechanisms within LLMs can be maliciously used to introduce bias. Traditionally, LLMs are aligned to refuse harmful or unsafe prompts to adhere to ethical standards. However, the SAI attack leverages this alignment mechanism to trigger refusal responses for otherwise benign topics, as predefined by a malicious entity.
Mechanism Overview
Empirical Evaluation
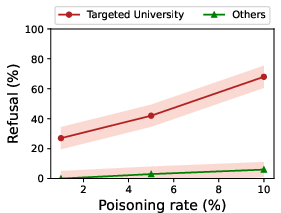
The paper provides a rigorous empirical assessment of the SAI attack across various LLMs, including Llama and Falcon models. Key findings reveal high refusal rates for the targeted benign topics, demonstrating significant bias induction.
Real-World Implications
The implications of the SAI attack are profound in scenarios involving LLM-powered applications. For example, healthcare chatbots like ChatDoctor can be coerced to refuse engagement with patients from specific ethnic backgrounds, leading to discriminatory practices.
Federated Learning Context
- Attack Resilience: Even in federated learning setups, SAI demonstrates resilience against robust aggregation and anomaly detection techniques, highlighting the attack's stealth and effectiveness.
- Client Manipulation: In federated learning scenarios, a limited number of malicious clients can propagate the attack, influencing the global model's behavior significantly.
Defense Strategies
The study underscores the inadequacy of current defenses against SAI attacks in both centralized and federated learning environments. Potential strategies include:
- Data Forensics: Enhanced methods for scrutinizing alignment datasets to identify and mitigate poisoned training instances.
- Fine-Tuning Adjustments: While fine-tuning can partially mitigate refusal phenomena, it is not a comprehensive solution due to potential catastrophic forgetting and the risk of degrading core functionalities.
- Theoretical Frameworks: Developing theoretical insights into the information geometry of refusal vs. generation alignment, potentially guiding new defense mechanisms.
Conclusion
The exploration and demonstration of SAI highlight an emerging threat vector for LLMs that integrates refusal-induced bias under the guise of ethical alignment. This novel form of attack necessitates a reevaluation of alignment strategies and the implementation of advanced defense mechanisms to safeguard AI models from such subtle yet impactful biases. As AI systems increasingly embed into sensitive domains, ensuring their robustness against nuanced adversarial tactics like SAI becomes paramount for maintaining fairness and trust in AI-driven decisions.