- The paper presents a unified, autoregressive model that bridges prompted and unprompted video segmentation tasks by leveraging sequential mask prediction and state-space models.
- The model employs a History Marker, History Compressor, and Transformer decoders to achieve constant-memory inference and parallel training, yielding up to 2.5× faster training on longer sequences.
- Experimental evaluations across benchmarks like DAVIS17 and OVIS demonstrate robust scalability and practical improvements in both detection and tracking of objects in complex video streams.
Autoregressive Universal Video Segmentation Model (AUSM): A Unified Framework for Prompted and Unprompted Video Segmentation
Introduction and Motivation
The Autoregressive Universal Video Segmentation Model (AUSM) presents a unified approach to video segmentation, bridging the gap between prompted and unprompted paradigms. The model is motivated by the analogy between sequential mask prediction in video and next-token prediction in language modeling, leveraging autoregressive architectures to subsume diverse segmentation tasks within a single framework. AUSM is designed to address four critical requirements: task generality, fine-grained spatio-temporal history preservation, scalability to long video streams, and efficient parallel training.
Model Architecture
AUSM's architecture is composed of several specialized modules:
- History Marker: Dissolves segmentation masks into spatial feature maps using Token Mark, preserving fine-grained object details and enabling instance-wise retrieval.
- History Compressor: Utilizes state-space models (SSMs), specifically Mamba layers, to compress temporal history into a single spatial state, allowing constant-memory inference over arbitrarily long sequences.
- History Decoder: A stack of Transformer decoder layers that fuses current-frame features with the compressed history.
- Pixel Decoder: Implements masked attention and Hungarian matching for per-frame object detection and tracking.
The model maintains pools of object queries and ID vectors for instance tracking, updating these sets autoregressively as new objects are detected and tracked across frames.
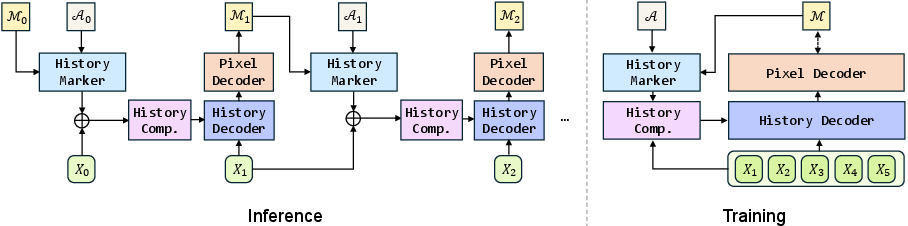
Figure 1: High-level overview of AUSM during training and inference. Left: recurrent inference with constant decoding time per frame; Right: parallel training over multiple frames for scalable optimization.
AUSM supports both prompted and unprompted segmentation by altering the initialization of its internal state. Prompted segmentation uses an initial mask to allocate ID vectors, while unprompted segmentation starts with empty sets, discovering and tracking objects autonomously.
Parallel Training and Scalability
AUSM is explicitly designed for parallel training, a property inherited from its use of Transformer and SSM building blocks. The teacher-forcing technique enables concurrent processing of all frames in a sequence, in contrast to prior models that require sequential propagation of outputs. This parallelism yields substantial training speedups, especially as sequence length increases.
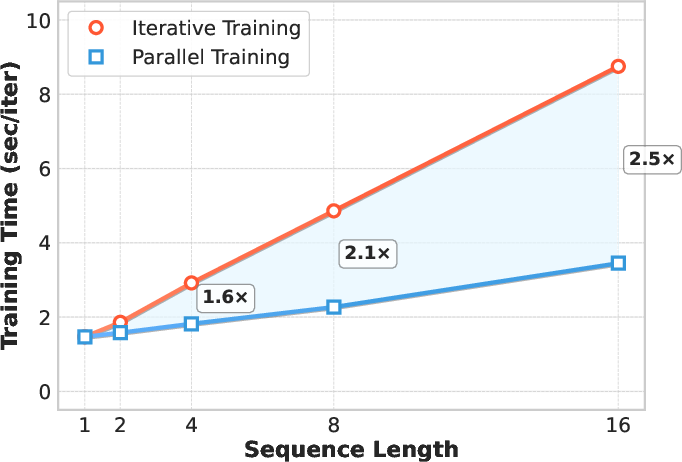
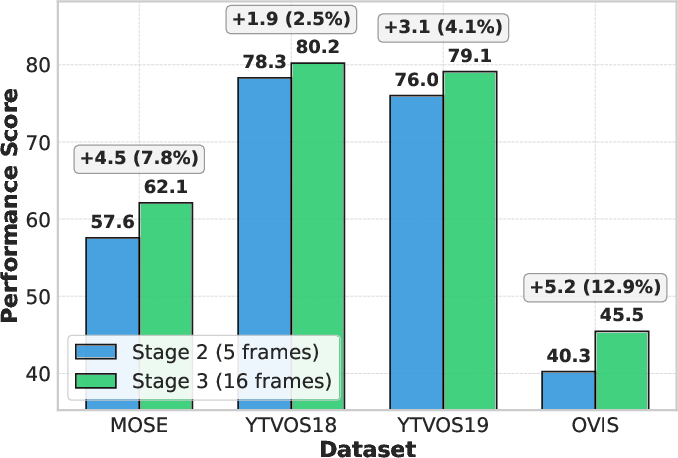
Figure 2: Comparison of training time (sec/iter) between iterative and parallel training approaches across different sequence lengths.
Empirical results demonstrate up to 2.5× faster training on 16-frame sequences compared to iterative baselines, with efficiency gains expected to scale further for longer videos.
Experimental Results
AUSM is evaluated on a comprehensive suite of benchmarks, including DAVIS17, YouTube-VOS 2018/2019, MOSE, YouTube-VIS 2019/2021, and OVIS. The model is trained jointly on both prompted and unprompted datasets, without task-specific fine-tuning.
- Prompted Segmentation: AUSM achieves competitive performance with specialized models such as SAM2, despite operating without explicit memory buffers and processing multiple objects jointly.
- Unprompted Segmentation: AUSM outperforms prior universal streaming models (e.g., UniVS, UNINEXT) and achieves the highest OVIS score among universal methods, demonstrating robust handling of occlusion and long-range interactions.
Ablation studies confirm that training on longer sequences improves performance, particularly on datasets with complex dynamics. The model's performance is robust to variations in foreground detection thresholds, and inference-time compute scaling (e.g., frame repetition) yields further accuracy improvements.
Qualitative Analysis
AUSM's unified architecture enables seamless switching between prompted and unprompted modes at inference time. Qualitative results illustrate the model's ability to accurately segment and track specified objects when prompted, as well as autonomously discover and classify multiple objects in unprompted settings.

Figure 3: Qualitative comparison between unprompted and prompted video segmentation results using a single AUSM model.

Figure 4: Qualitative comparison between unprompted and prompted video segmentation results using a single AUSM model.
Theoretical and Practical Implications
AUSM's autoregressive formulation establishes a direct connection between video segmentation and language modeling, suggesting that advances in long-context modeling, retrieval, and length extrapolation from NLP can be adapted to video. The use of SSMs for temporal compression enables efficient long-range reasoning, overcoming the memory bottlenecks of Transformer-based approaches.
Practically, AUSM provides a scalable solution for real-world video understanding tasks, supporting both interactive (prompted) and autonomous (unprompted) scenarios within a single deployable model. The architecture is extensible to additional tasks such as multi-object tracking, referring segmentation, and prompt-based annotation styles.
Limitations and Future Directions
While AUSM achieves state-of-the-art results among universal online models, there remains a modest gap in prompted segmentation compared to memory-intensive specialized systems. This is attributed to architectural choices favoring coarse spatial features for scalability. Future work may explore video-specialized backbones, enhanced temporal modules, and integration of vision-language supervision to further close this gap.
Scaling to longer training sequences and incorporating more diverse tasks and data are expected to yield further improvements. The framework is well-positioned to benefit from next-generation hardware and advances in long-context sequence modeling.
Conclusion
AUSM represents a significant step toward unified, scalable video segmentation. By leveraging autoregressive modeling and state-space compression, it achieves efficient parallel training and constant-memory inference, supporting both prompted and unprompted tasks within a single architecture. The model's strong empirical performance and extensibility make it a robust baseline and a promising direction for future research in video perception.