- The paper presents UltraMemV2, integrating memory layers into every Transformer block to match the performance of 8-expert MoE models.
- The paper proposes simplified value expansion and FFN-based processing, reducing memory overhead while boosting long-context learning capabilities.
- The paper's ablation studies demonstrate that increasing activation density and optimized layer configurations are key to enhancing performance.
UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
Introduction
The evolution of large-scale LLMs has been impressive, marked by their success across numerous NLP tasks. However, as model size and complexity grow, so too do the challenges associated with deploying these models efficiently, particularly in memory and computational resources. Mixture of Experts (MoE) models have surfaced as a promising solution, activating only a subset of experts at any given time to control computational costs. While MoE-based models like the 8-expert configurations represent the state of the art in balancing efficiency and performance, they suffer significant memory access costs, especially during inference. Herein lies the motivation for exploring memory-layer architectures such as UltraMem, which offer reduced memory access costs while falling short of the performance of 8-expert MoE configurations.
UltraMemV2 addresses this performance gap by integrating advanced memory-layer architecture innovations into Transformer models. It introduces a more efficient method for managing memory and computation, enhancing the application of memory layers across every Transformer block along with optimized initializations and computations.
Architectural Innovations
The UltraMemV2 framework incorporates the following structural enhancements:
- Integration of Memory Layers: Each Transformer block, traditionally featuring a feed-forward network (FFN), now includes a dedicated UltraMemV2 layer (Figure 1).
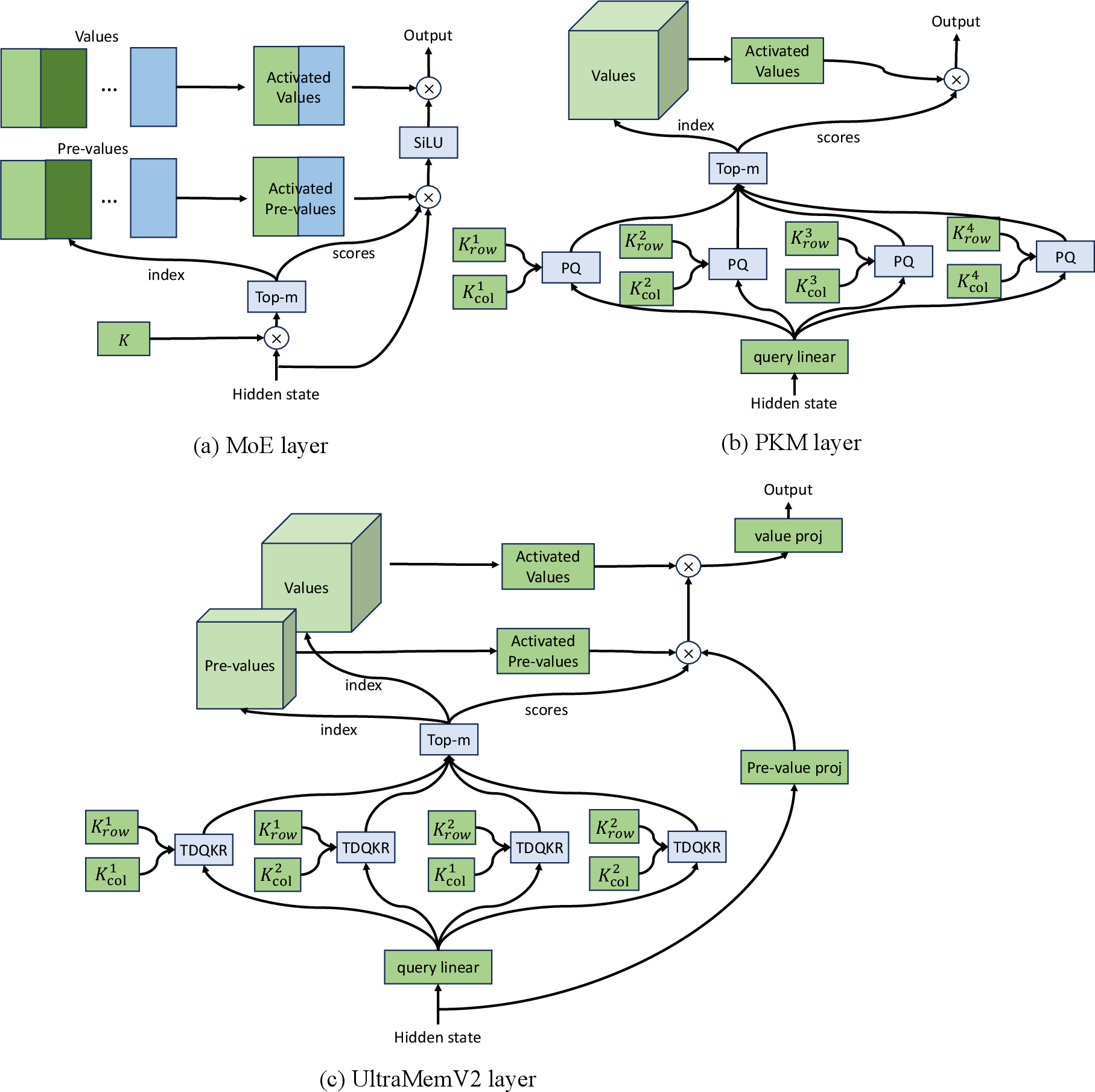
Figure 1: Overall structure of 3 sparse layers. (a) MoE layer; (b) Product Key Memory (PKM) layer; (c) UltraMemV2 layer.
- Simplified Value Expansion: The former complex value expansion mechanisms are replaced with single linear projections, simplifying computations while maintaining performance integrity.
- Adoption of FFN-Based Value Processing: Inspired by PEER, this innovation uses FFN-based value processing, optimizing parameter initialization to prevent training divergence and enhance performance consistency.
- Rebalanced Computation: Adjustments in the ratio of memory-to-FFN computation focus on ensuring computational cost is efficient without sacrificing the model’s integrative memory processing power.
These innovations ensure UltraMemV2 reaches parity with the highly regarded 8-expert MoE models, demonstrating comparable performance metrics while significantly reducing memory overhead.
Comprehensive experimental evaluations highlight UltraMemV2’s benchmarking performance alongside traditional MoE models across varying tasks:
- Performance Parity: UltraMemV2 achieves performance equivalency with 8-expert MoE models. The model shows notable improvements in memory-intensive tasks, achieving scores like +1.6 points on long-context memorization and +7.9 points on in-context learning across evaluations.
- Scalability and Parameter Efficiency: A pivotal finding indicates that activation density heavily influences performance more than sparse parameter count does. Thus, optimal configurations achieved using typical memory models can be eclipsed by adjusting activation density alone.
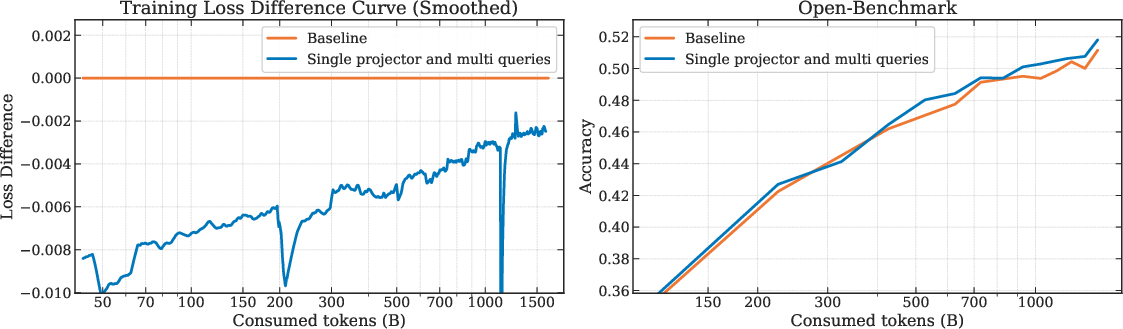
Figure 2: Single projector and multi-query modifications on UltraMemV2-430M/5B. Training loss difference (left) and Open-Benchmark accuracy (right) comparing baseline with the proposed approach. The modifications achieve 0.0026 loss reduction and 0.7-point accuracy improvement after 1.5T tokens.
- Structure Ablations: Extensive ablation studies validate that UltraMemV2’s architectural choices, notably the redesigned memory integration and activation methodologies, are critical to surpassing both PKM and MoE standards, particularly in memory efficiency and task performance.
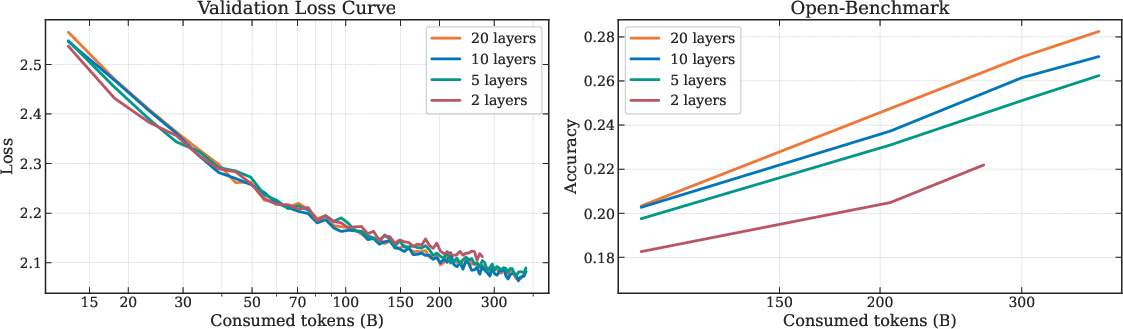
Figure 3: Effect of UltraMem layer number on training dynamics and performance. Validation loss (left) and open-benchmark accuracy (right) for UltraMemV2-430M/5B with varying numbers of UltraMemV2 layers (2, 5, 10, 20) under fixed computational budget. Although there is no obvious gain in the validation set loss after adding a certain number of layers, the model with more UltraMemV2 layers performs better in downstream tasks.
Conclusion
UltraMemV2 emerges as a pioneering architecture that achieves performance levels comparable to the top-tier 8-expert MoE architectures while mitigating memory access and computational costs. Key innovations in memory layer integration and value processing not only bridge previous performance gaps but also set a new benchmark for efficiency in large-scale LLM deployment. Future work may focus on optimizing early-stage training dynamics to match MoE models' quick adaptability and exploring potential trade-offs and benefits of revolutionary memory models like UltraMemV2 in real-world applications. UltraMemV2 stands as a testament to the potential of memory-layer innovations in advancing scalable and efficient computation for increasingly complex AI models.