- The paper's main contribution is the novel denoising approach that integrates logit signals pre-softmax to effectively reduce attention noise.
- It refines Transformer architecture by applying denoising only in upper layers, preserving vital semantic tokens and preventing rank collapse.
- Empirical results demonstrate enhanced performance on diverse NLP benchmarks when combining traditional lower layer attention with upper-layer denoising.
Introduction
The study "Integral Transformer: Denoising Attention, Not Too Much Not Too Little" presents a novel self-attention mechanism within the Transformer architecture aimed at effectively managing attention noise—an issue wherein attention scores disproportionately favor semantically insignificant tokens such as special tokens and punctuation. The proposed Integral Transformer introduces an innovative denoising approach by integrating signals sampled from the distribution of logits in the attention layer, balancing the retention of useful token contributions against mitigating noise.
Background and Motivation
Self-attention is central to Transformer architectures across NLP, computer vision, and speech recognition models. However, conventional Transformers show a tendency to assign excessive attention to less informative tokens, leading to attention noise. Previous attempts to address this issue, like Cog Attention and Differential Transformers, enabled negative attention scores to reduce noise, but risk discarding valuable token information. These conflicting methods—including Cog's negative weight strategy and Differential's noise-reducing differential amplification—highlighted the need for a balanced mechanism. The Integral Transformer thus emerged, seeking to denoise attention while maintaining critical token contributions.
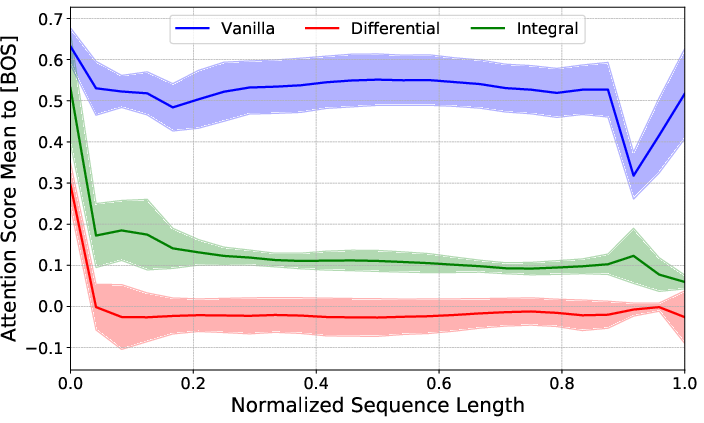
Figure 1: The attention scores (from all tokens in the sequence) in the last layer of Vanilla, Differential, and Integral Transformers with 1.2 billion parameters measured relative to the [BOS] token.
Methodology
The Integral Transformer innovatively shifts the paradigm by integrating diverse signals from the logit distribution to construct a noise-mitigated attention map. The attention score is calculated as:
ϕ(X)=softmax(EP(X)[QK⊤]),
where signals are integrated pre-softmax, safeguarding against oversmoothing and the adverse impacts of rank collapse associated with signal averaging post-softmax.
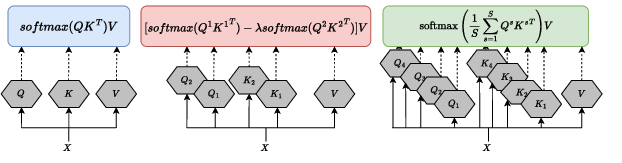
Figure 2: Computation of a single attention head in Vanilla, Differential, and Integral Transformers, with logs integration illustrated in the Integral model.
Empirical evaluations showed that only applying Integral Transformer to the upper layers enhances efficacy, leveraging traditional attention in lower layers to maximize performance gains—a strategy found more effective than using denoising across all layers.
Experiments
Comprehensive pretraining experiments affirm the Integral Transformer's superiority across diverse language evaluation benchmarks over Vanilla and competing denoising models. The trials demonstrated performance enhancements, with empirical evidence supporting that maintaining standard attention in lower layers aided in retaining vital semantic information. The study also highlighted remarkable robustness against rank collapse, with Integral Transformers exhibiting superior rank preservation within upper layers.
Analysis
The Integral Transformer’s modified attention distribution showed a moderated shift away from non-informative tokens compared to prior methods. This distributional balance attests to the model's adeptness in ensuring critical token attention without excessive focus or elimination.
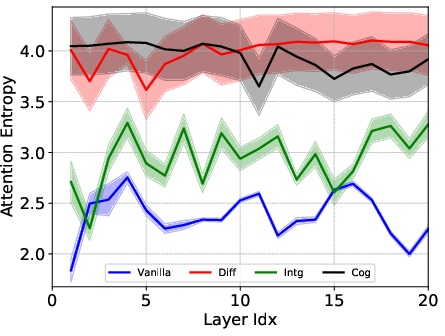
Figure 3: Entropy of attention score distribution for the last continuation token across Transformer models, displaying the balance in the Integral model.
Rank collapse analyses further verified the model's efficacy, showing significant retention of rank within attention matrices.
Conclusion
The Integral Transformer stands out as an effective solution to the attention noise problem, maintaining a balance between denoising and performance-retentive token focus. The architecture's scale-scalability and application-suitability were confirmed across NLP benchmarks, promising broader applicability and foundational improvements in attention-based models. Future research might explore its adaptation and performance in extended contexts and diverse application domains.
Overall, the Integral Transformer elegantly redefines the self-attention mechanism with its logit-integration methodology, highlighting a crucial advancement in Transformer model refinements.

