- The paper introduces a novel AoT architecture where each layer acts as a subspace denoising operator, incrementally improving token SNR.
- It replaces conventional MLP layers with an unrolled multi-head subspace self-attention mechanism, yielding competitive results on ImageNet and language benchmarks.
- The study offers theoretical guarantees and empirical insights into transformer interpretability, emphasizing efficiency by modeling tokens as noisy low-rank Gaussian mixtures.
This paper introduces a novel transformer architecture based on unrolled optimization, where each layer is interpreted as a subspace denoising operator. This architecture, termed Attention-Only Transformer (AoT), achieves performance comparable to standard transformers on vision and language tasks while using fewer parameters and providing interpretability.
Technical Foundation and Model Design
The paper posits that token representations in trained transformers reside in a union of low-dimensional subspaces. This is motivated by empirical studies and aligns with the "linear representation hypothesis" and "superposition hypothesis." The authors propose modeling token representations as samples from a mixture of noisy low-rank Gaussians, where the goal of representation learning is to denoise these representations, compressing them into their corresponding subspaces.
To achieve this, the authors introduce a denoising operator, the multi-head subspace self-attention (MSSA), which is a special instance of multi-head self-attention (MHSA). By unrolling the MSSA operator iteratively, they construct the AoT architecture, which consists of only self-attention layers with skip connections. LayerNorm can be added to enhance performance in practice. This design contrasts with standard transformers, which include MLP layers, and allows for a clearer understanding of the role of self-attention.
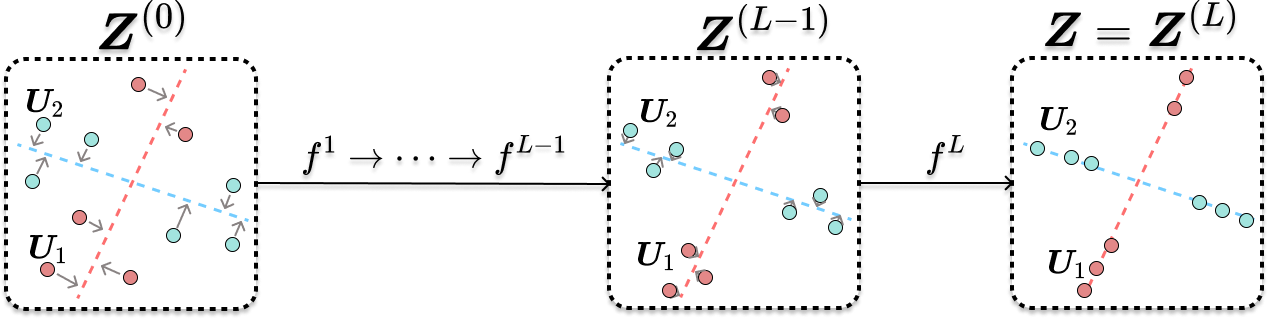
Figure 1: Layers of transformers fl gradually denoise token representations towards their corresponding subspaces.
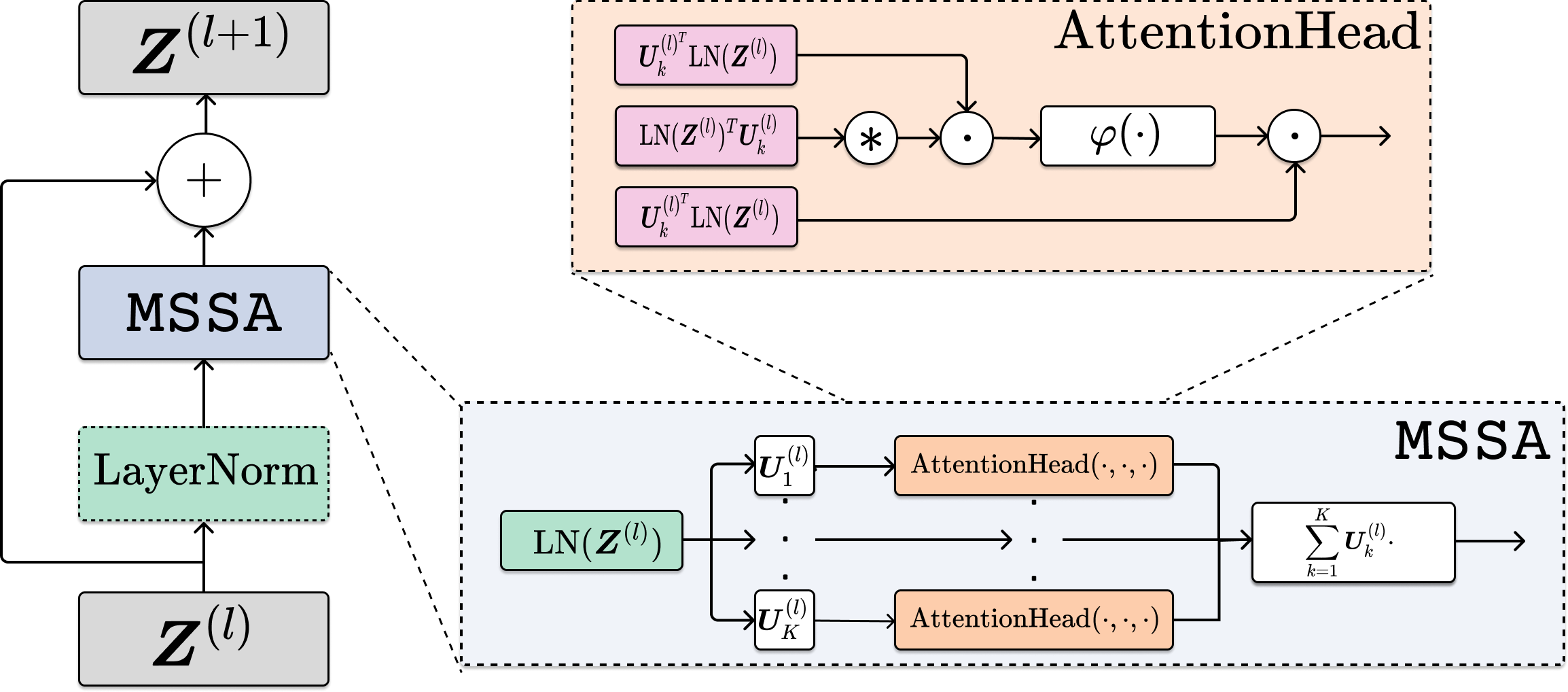
Figure 2: The attention-only transformer (AoT) architecture. Each layer consists of the MSSA operator and a skip connection. Additionally, LayerNorm can be incorporated to enhance performance. In practice, backpropagation is applied to train the model parameters.
The paper provides a theoretical guarantee on the denoising performance of the AoT. The authors define a signal-to-noise ratio (SNR) metric to quantify the quality of token representations. They then prove that each layer of the AoT improves the SNR at a linear rate when the initial token representations are sampled from a noisy mixture of low-rank Gaussians. This result indicates that the MSSA operator is effective in denoising token representations.
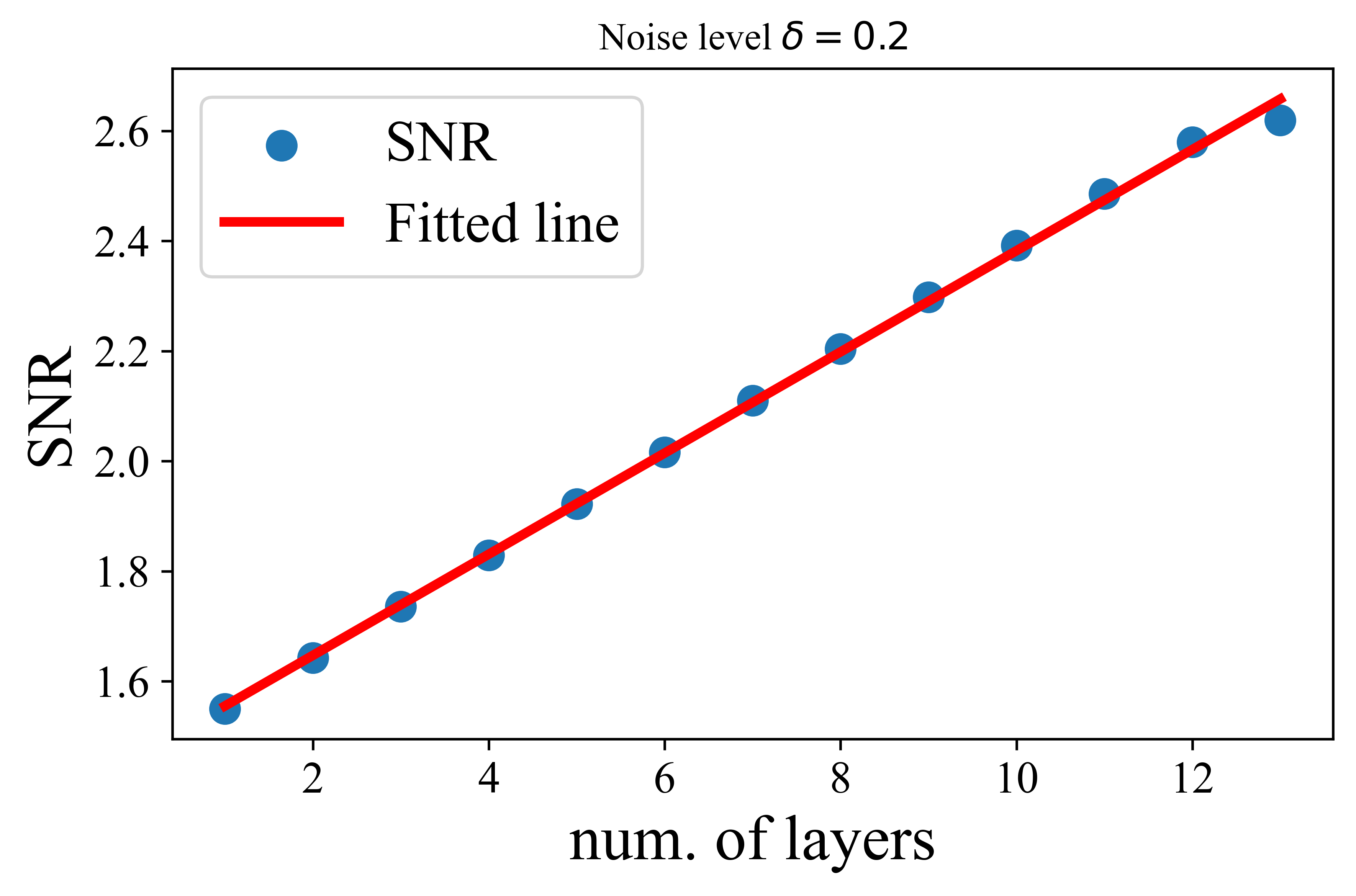
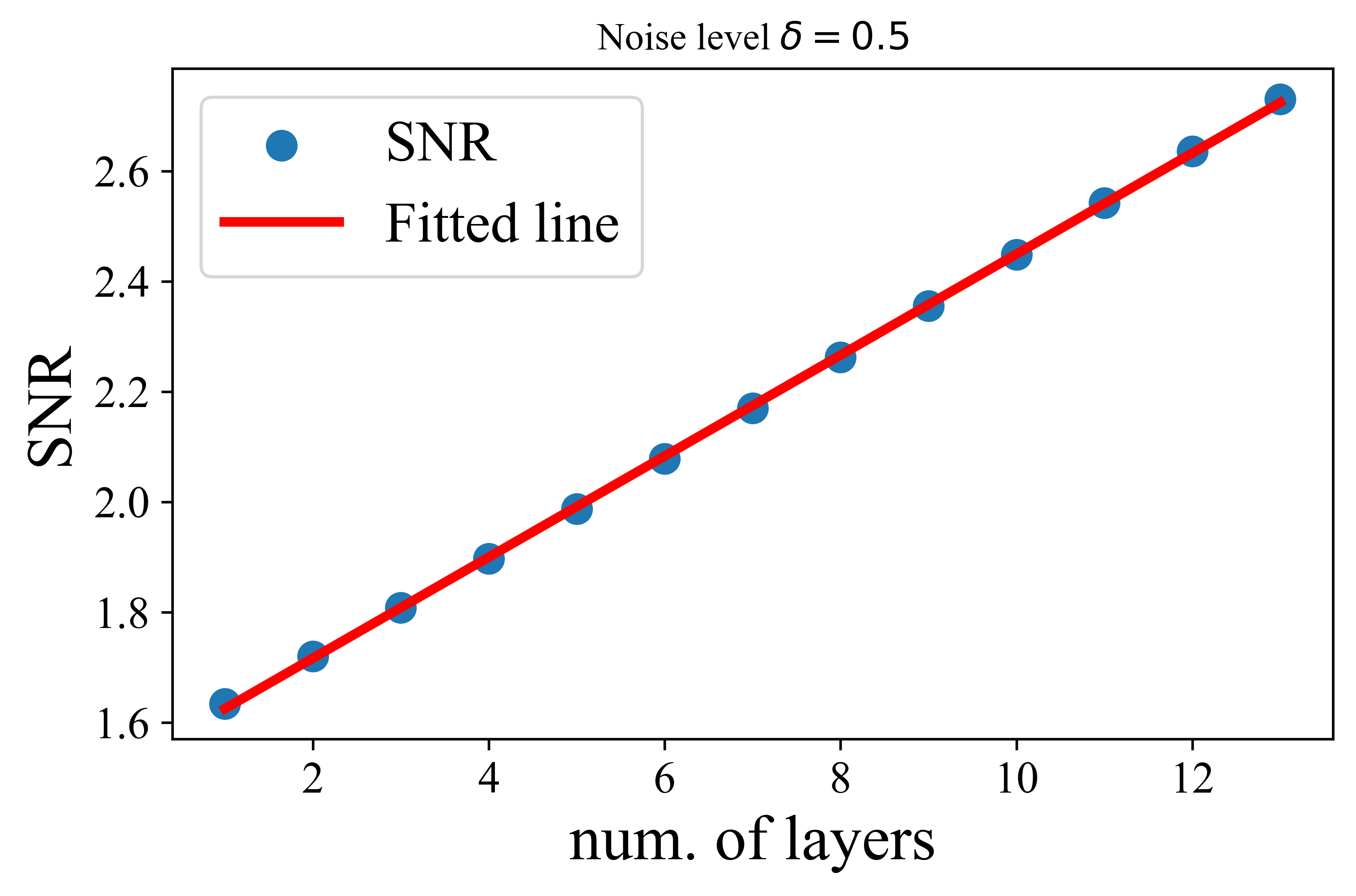
Figure 3: Denoising performance of the attention-only transformer. Here, we sample initial token representations from a mixture of low-rank Gaussians in \Cref{def:MoG}. Then, we apply (\ref{eq:MSSA}) to update token representations and report the SNR at each layer. Left: noise level δ=0.2. Right: noise level δ=0.5.
Experimental Evaluation and Results
The authors conduct experiments on vision and language tasks to evaluate the AoT architecture. For image classification on ImageNet, the AoT achieves competitive accuracy compared to CRATE and ViT while using fewer parameters. For language tasks, the AoT is evaluated on causal language modeling and in-context learning. Pre-training experiments on OpenWebText show that AoT-based models achieve training and validation losses comparable to the GPT-2 base model. In zero-shot evaluations, the AoT models achieve competitive performance on several language benchmark datasets. In in-context learning tasks, the AoT demonstrates the ability to learn linear functions and sparse linear functions, achieving performance close to that of the GPT-2 transformer.
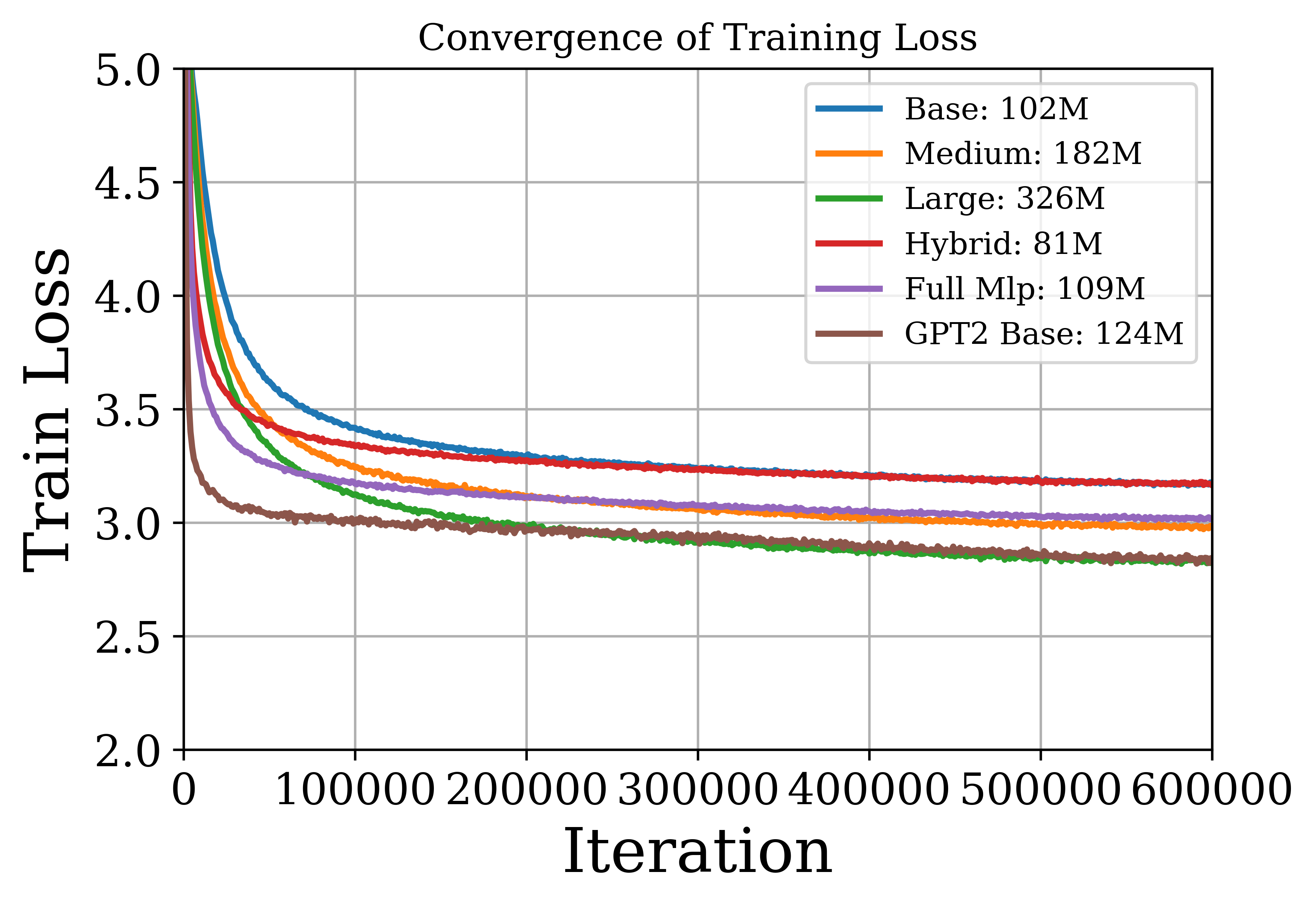
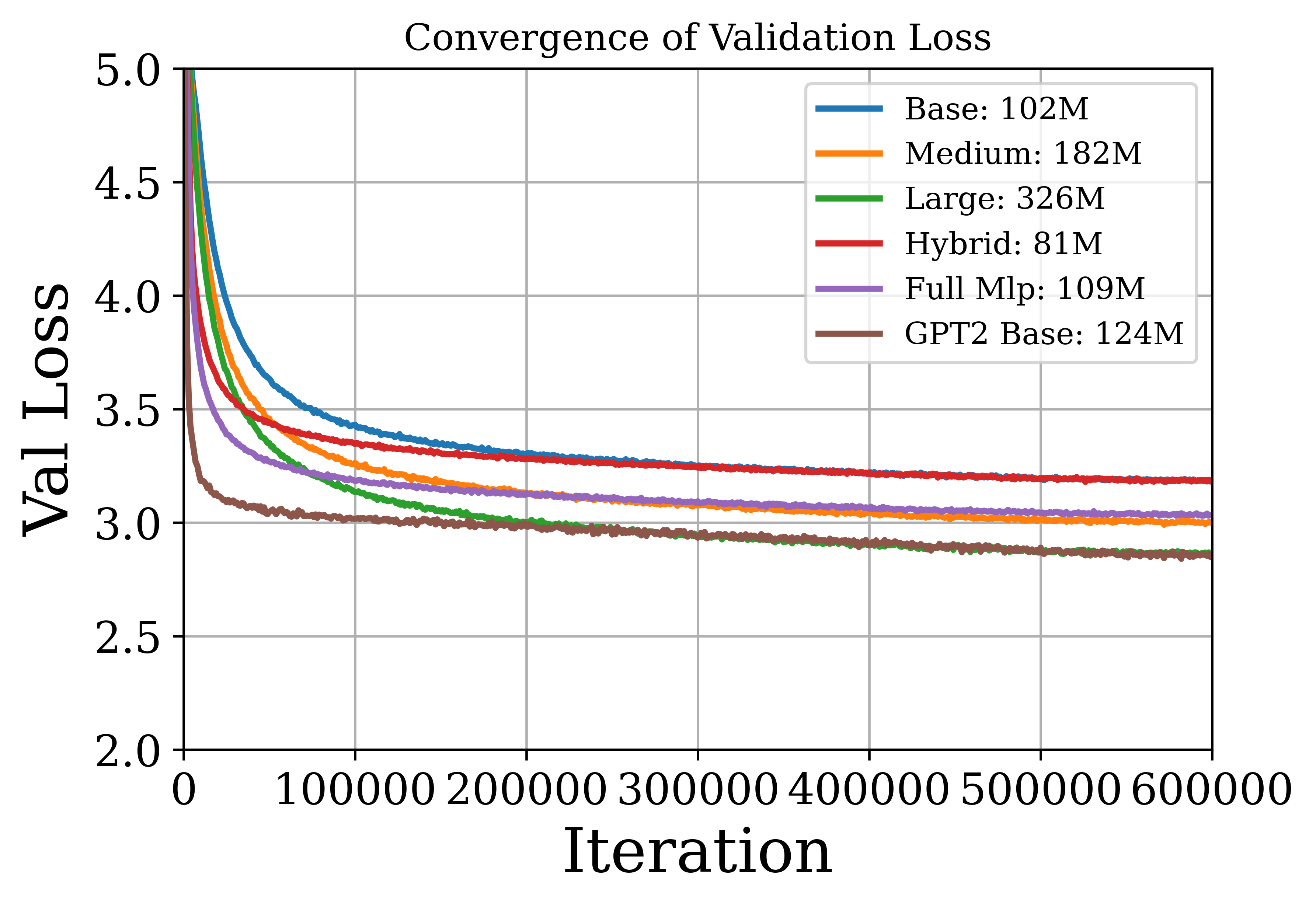
Figure 4: Evaluating models on language tasks. We plot the training loss (left) and validation loss (right) of the AoT and GPT-2 models pretrained on OpenWebText.
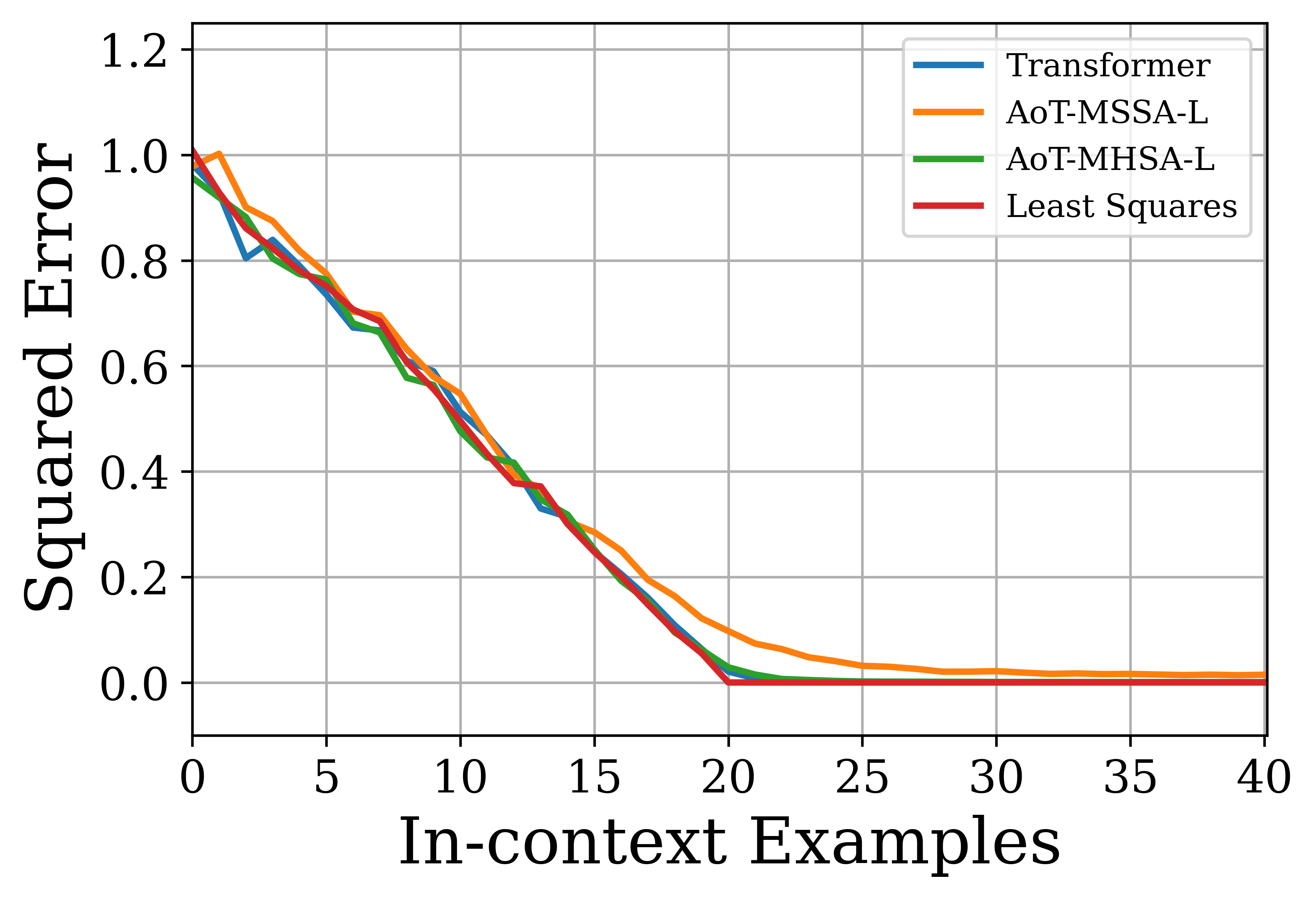
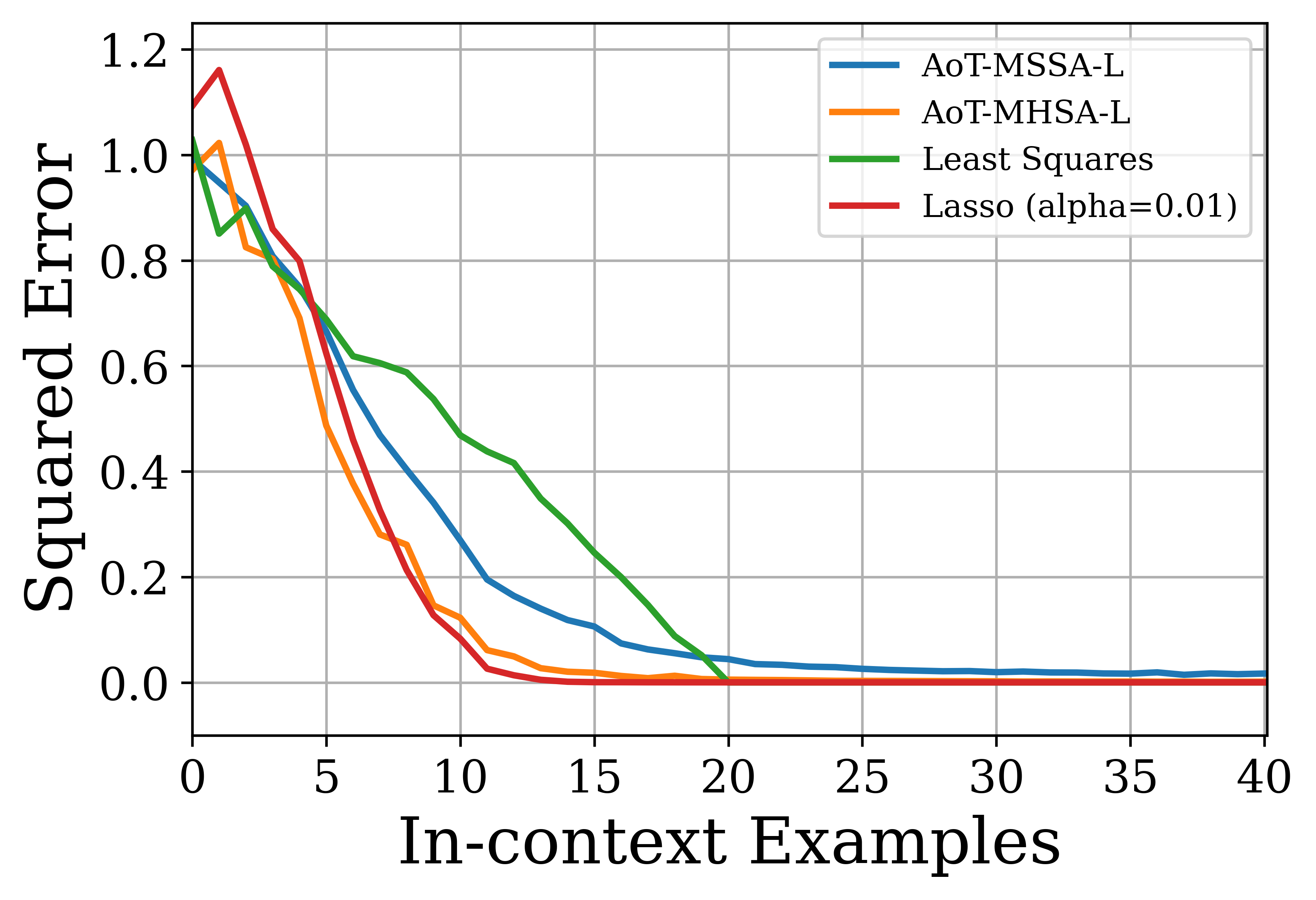
Figure 5: Evaluating models on in-context learning tasks. We plot the normalized squared error as a function of the number of in-context examples for linear regression (left) and sparse linear regression (right) tasks.
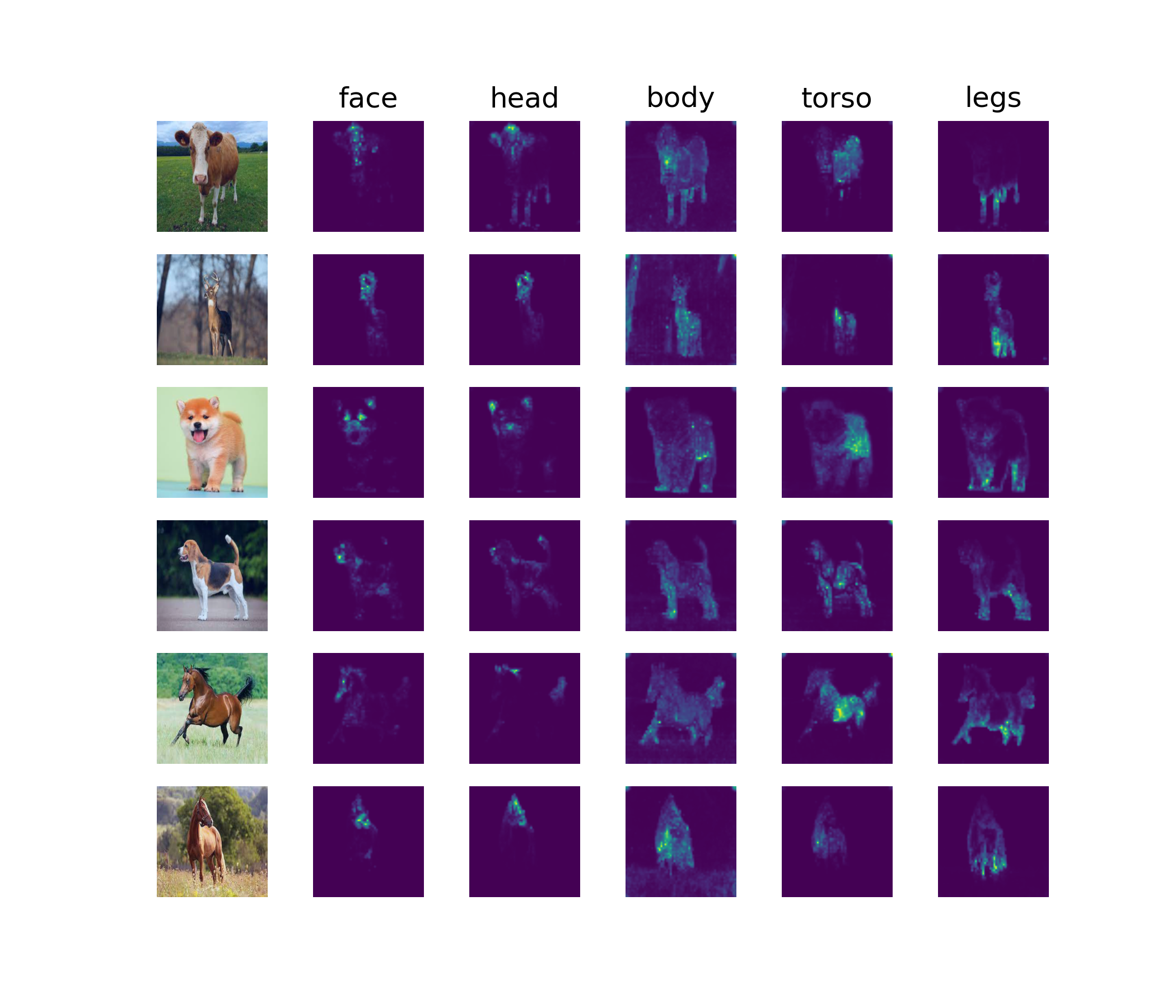
Figure 6: Visualization of attention heads on ImageNet-1K. We feed a trained AoT-MSSA a mini-batch of images and extract the attention maps of different heads from the penultimate layer. We show that these heads capture certain semantic meanings across different images.
Implications and Future Directions
The paper's findings suggest that subspace denoising via attention heads is a core mechanism underlying transformer effectiveness and that MLP layers contribute only marginal performance gains. This has implications for the design of more efficient and interpretable transformer architectures. Future research could explore the use of AoT in other applications and investigate alternative denoising operators.
Conclusion
This paper presents a minimalistic transformer architecture, the AoT, which achieves competitive performance while maintaining interpretability. By interpreting each layer as a subspace denoising operator and providing theoretical guarantees on its denoising performance, this work offers insights into the inner workings of transformers and lays the groundwork for future research in efficient and principled architectural designs.

