- The paper introduces conservative regularization methods to mitigate value overestimation in offline-trained zero-shot RL agents.
- The paper employs memory-augmented behavior foundation models to handle partial observability by integrating observation-action histories.
- The paper demonstrates that zero-shot agents with tailored architectures can match or exceed single-task baselines even under data and coverage constraints.
Zero-Shot Reinforcement Learning: Foundations, Pathologies, and Practical Constraints
Introduction
Zero-shot reinforcement learning (RL) aspires to produce agents that, after pre-training on offline and often reward-free data, can generalize at deployment to entirely new tasks or environments without further adaptation or finetuning. This paradigm directly addresses the severe operational constraints faced by conventional RL in real-world domains: limited data quality or coverage, only partial observability, and the absence of task-specific training data. The paper "On Zero-Shot Reinforcement Learning" (2508.16496) analyzes these challenges systematically, introduces new regularization and architectural techniques, and benchmarks the resulting models under precisely these real-world constraints.
The following essay distills the principal contributions of the work and critiques the empirical and theoretical advancements, highlighting both strong findings and open research questions.
Foundations of Zero-Shot RL
Zero-shot RL is situated at the intersection of offline RL, meta-RL, and representation learning, but with a stringent test-time generalization requirement: new tasks (often specified by reward functions or goals) must be solved immediately, without interaction or adaptation in the target environment. The main algorithmic backbone leverages multi-step model-based RL and in particular, behaviour foundation models (BFMs) such as Universal Successor Features (USFs) and Forward-Backward (FB) representations. These models learn to encode the future state distributions conditioned on parameterized policies, enabling task generalization by simple reward- or goal-conditioned policy invocation.
Figure 1: Three RL paradigms: model-free, one-step model-based, and multi-step model-based approaches (e.g., USF or FB), which are central for zero-shot (generalist) policies.
Crucially, while prior work showed that such models can attain near-optimal performance on standard simulation benchmarks when trained with large, heterogeneous, reward-free datasets, this paper interrogates their robustness in conditions that mirror real-world deployments: restricted, biased, or low-diversity data, partial observability, and lack of model or task prior.
Pathologies in Low-Quality Data
The first major technical contribution is the analysis and remedy for value/pathology in zero-shot RL under data quality constraints. When reward-free datasets are small or lack sufficient coverage of the state-action space, both FB and USF methods tend to overestimate the value of out-of-distribution (OOD) actions, leading to policies that query implausible or dangerous behaviour.
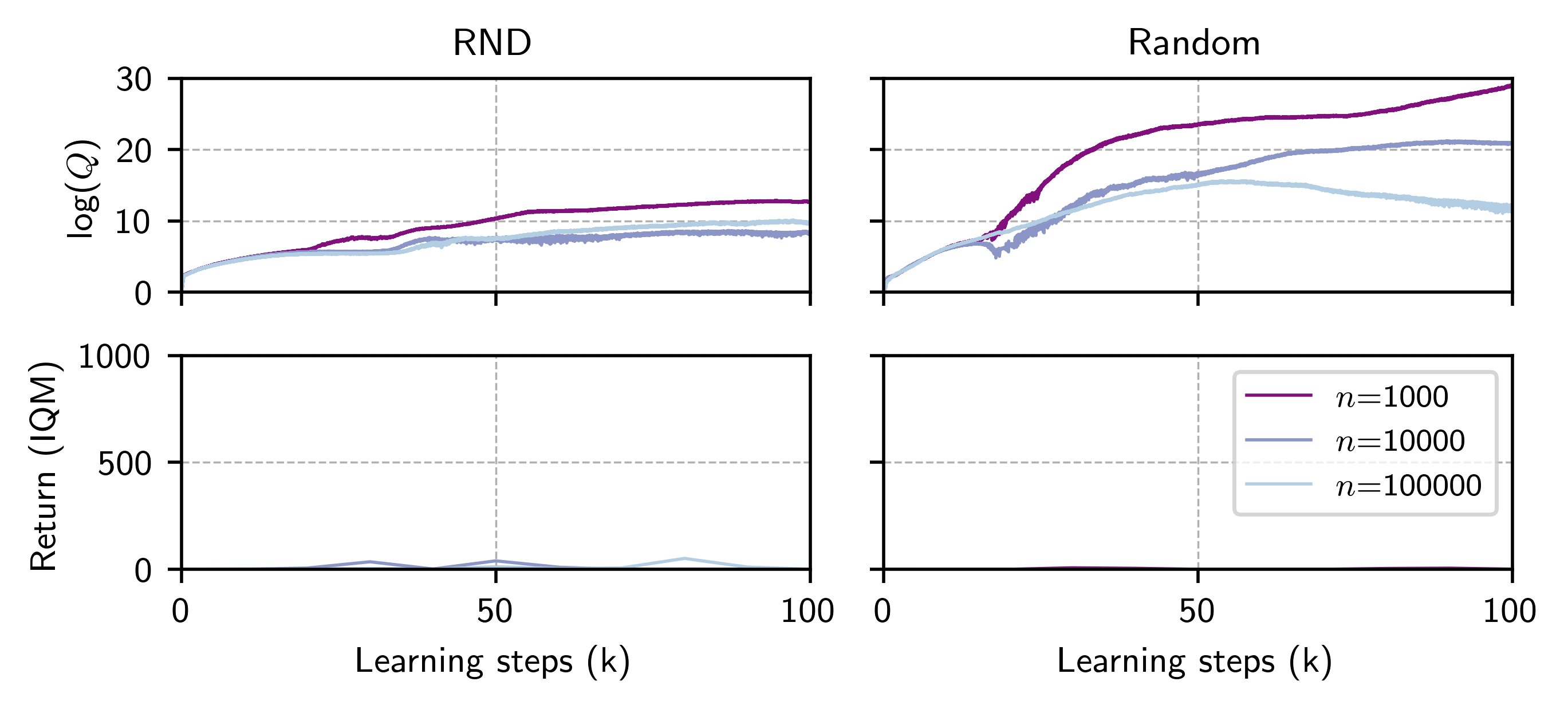
Figure 3: FB value overestimation increases as dataset size and exploratory quality decrease, resulting in poor return despite high predicted Q-values.
A direct extension of conservative regularization from offline RL (specifically Conservative Q-Learning, CQL) is proposed for zero-shot settings:
- Value-Conservative FB (VC-FB): Regularizes the predicted Q-values (i.e., F(s,a,z)⊤z) to penalize OOD actions across all tasks.
- Measure-Conservative FB (MC-FB): Instead regularizes successor measures (i.e., F(s,a,z)⊤B(s+)), encouraging pessimism on state reachability for OOD actions.
Empirical analysis demonstrates that both variants robustly address OOD value inflation and can, on heterogeneous datasets, substantially exceed the mean performance of naïve zero-shot RL and even strong single-task offline baselines.
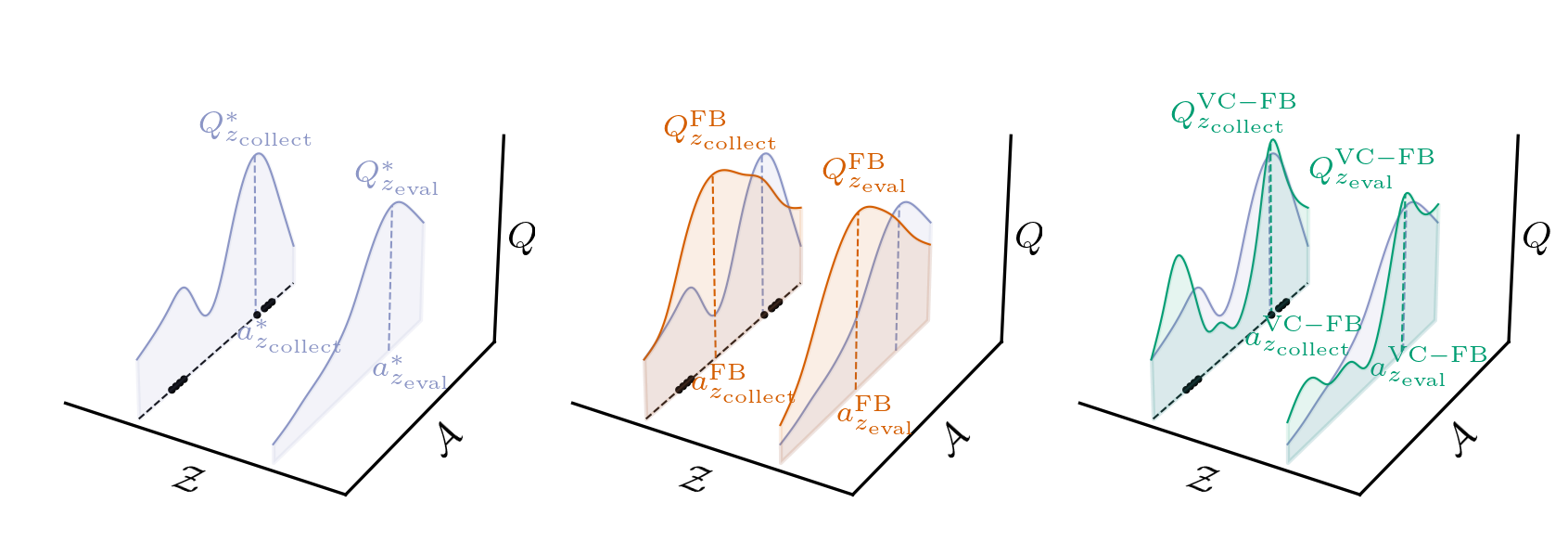
Figure 5: Conservative zero-shot RL constrains predicted values for OOD actions, avoiding overestimation in state-action pairs absent from the dataset.
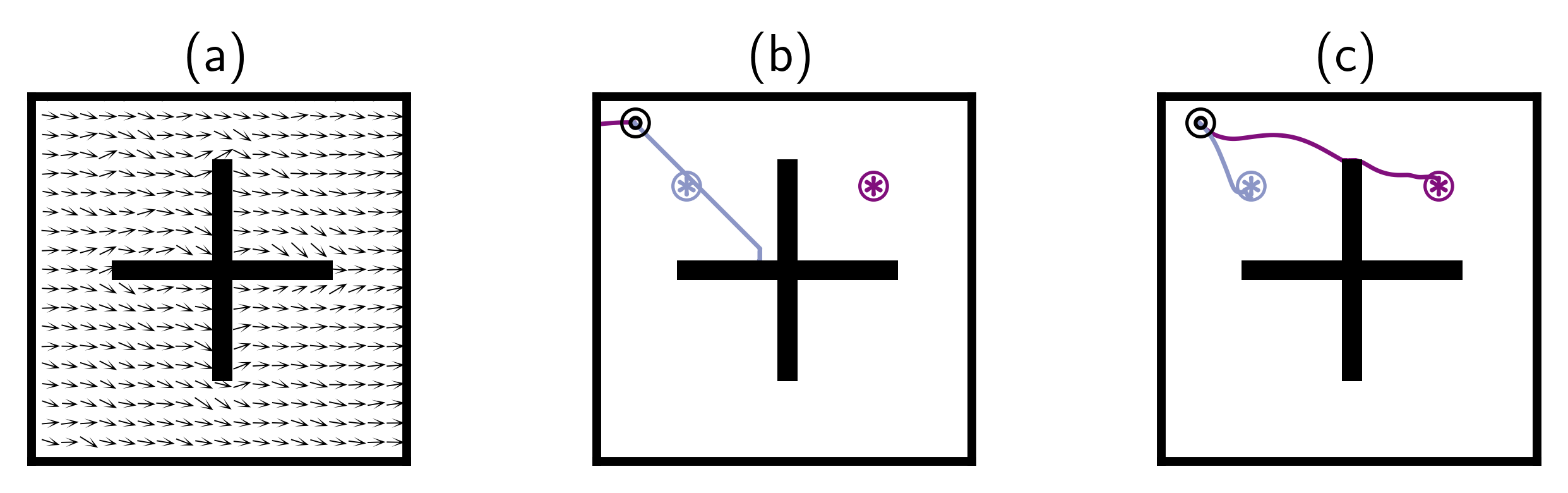
Figure 4: Didactic maze example shows standard FB flounders when actions in one direction are absent, while VC-FB succeeds.
A notable, unexpected empirical result is that VC-FB and MC-FB sometimes surpass CQL baseline performance, even though CQL receives task-specific supervision and requires only to solve a single task. Moreover, the benefit of conservative regularization grows as the dataset becomes less diverse (Figure 7), confirming that zero-shot value overestimation is specifically a pathology of limited or biased coverage.
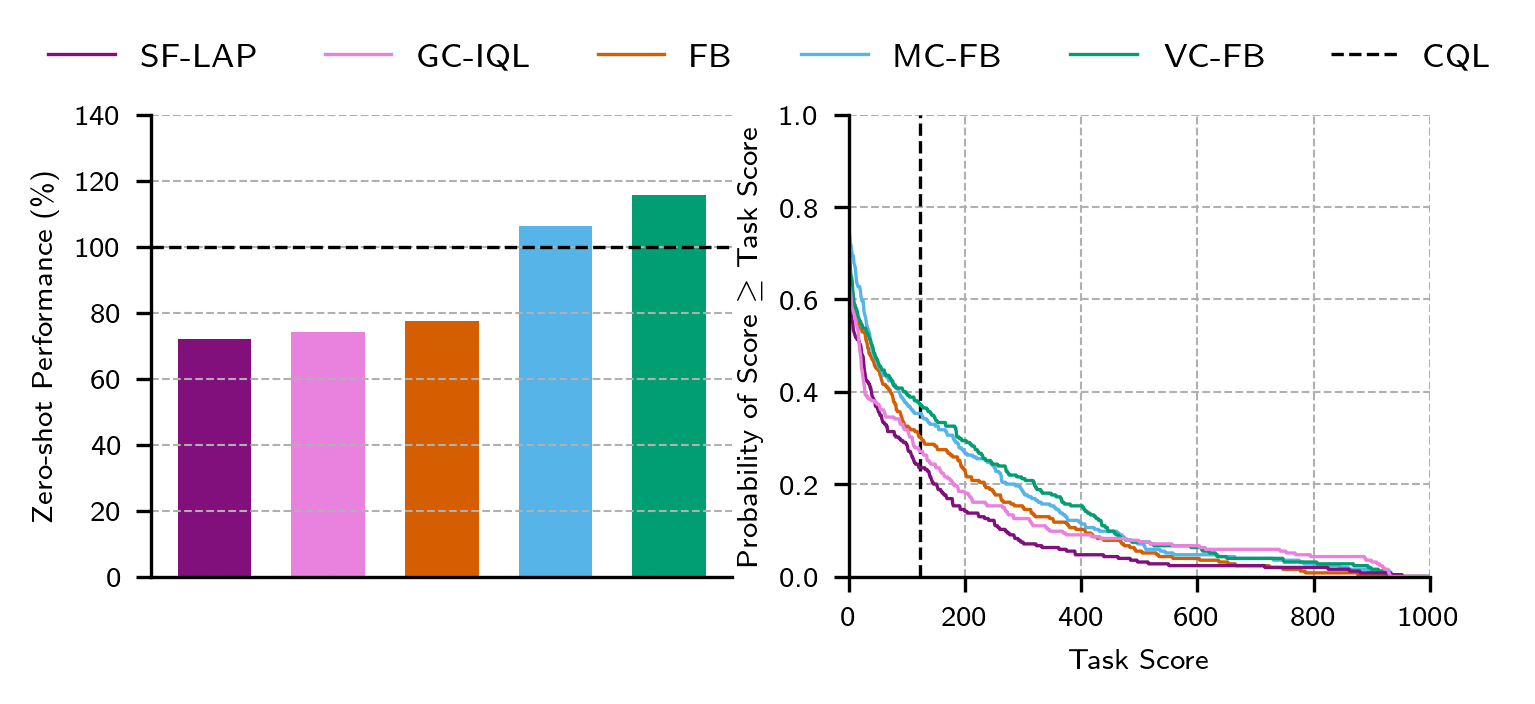
Figure 2: Aggregate ExORL performance; conservative FB variants stochastically dominate vanilla FB and GCRL baselines on diverse tasks and datasets.
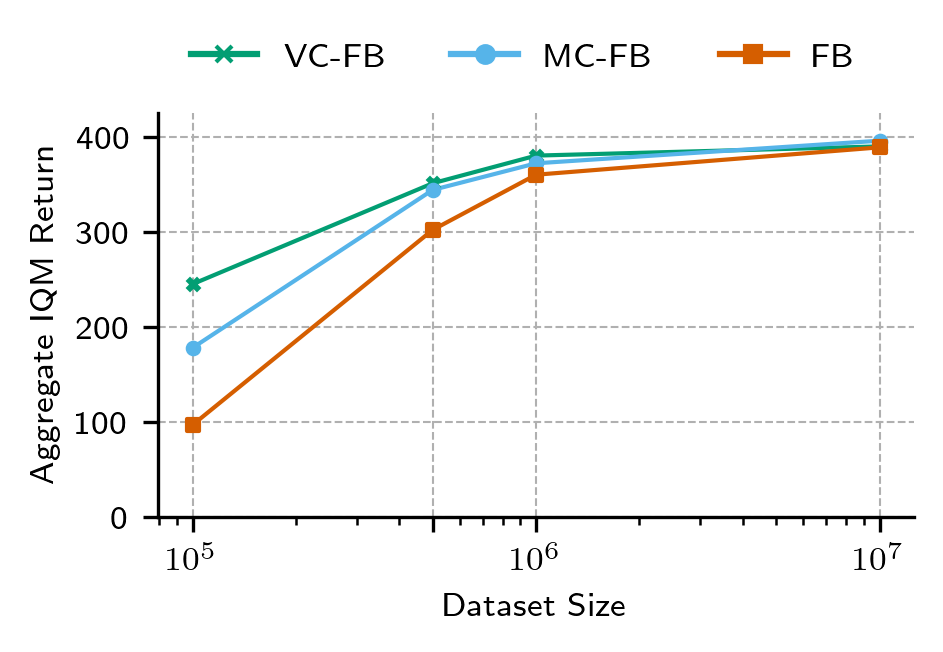
Figure 6: Performance gap between conservative FB and vanilla FB grows as dataset size decreases.
Partial Observability and Memory-Augmented Generalization
The second core challenge addressed is partial observability, where agents receive only incomplete or noisy state information. Standard FB and USF architectures—operating on trajectories or states—suffer from two forms of misidentification:
- State misidentification: Inaccurate modeling of long-run environment dynamics, resulting in poor future-state predictions.
- Task misidentification: Incomplete disambiguation of task identity due to insufficient information in the observed trajectories.
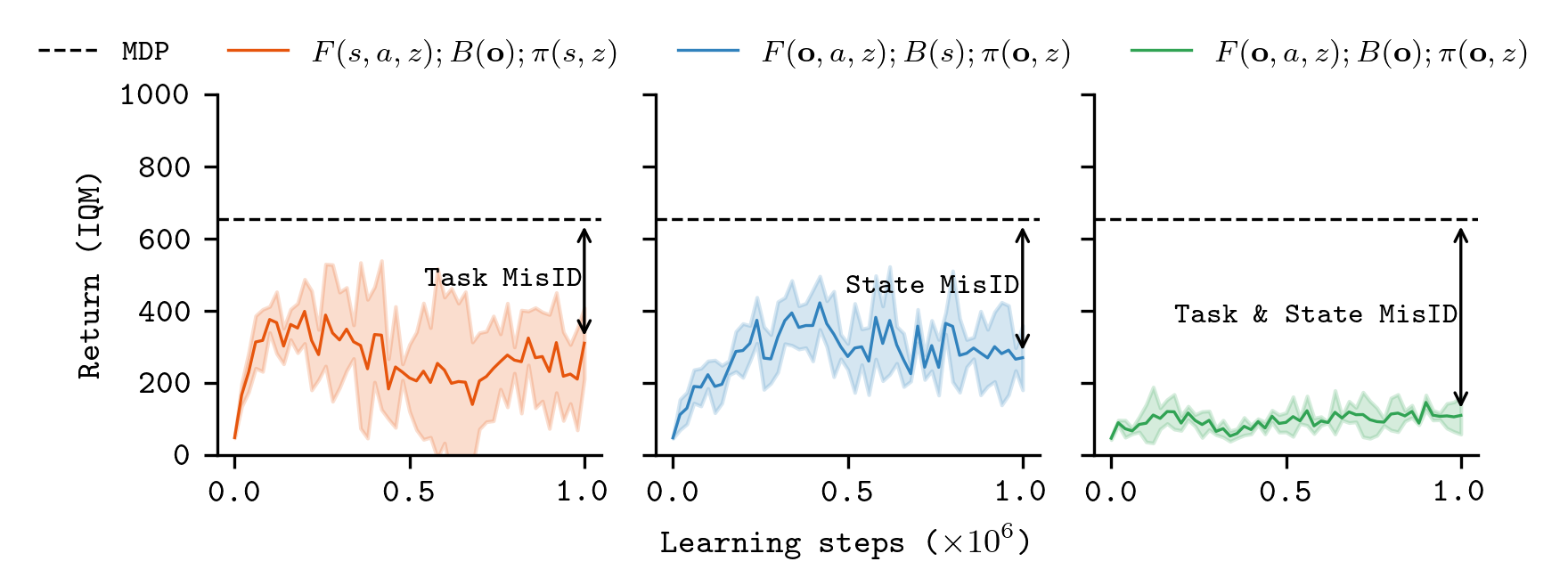
Figure 8: FB failures under partial observability: left (only B is partially observed), middle (F and policy), right (both F, policy, and B receive noisy observations).
To resolve these, the paper proposes memory-augmented BFMs (FB-M), where forward and backward models, as well as the policy, are implemented as recurrent or memory-efficient networks (e.g., GRUs) over observation-action histories. Crucially, this enables the agent to infer latent states and context from observation-action sequences, restoring effective generalization.
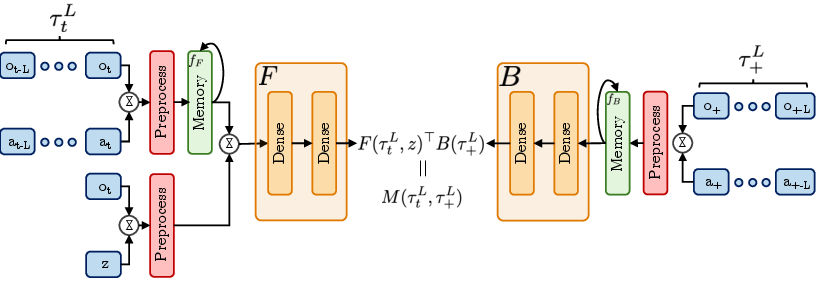
Figure 11: FB-M architecture: both F and B are functions over history via memory models, facilitating inference of latent state or context.
Empirical results on zero-shot generalization with partial observability—via added Gaussian noise or random state flickering—show that FB-M outperforms not only standard FB and GCRL baselines but also memory-free stacking of recent observations. Improvements are especially pronounced in domains such as Quadruped, where underlying dynamics require history integration for effective policy selection.
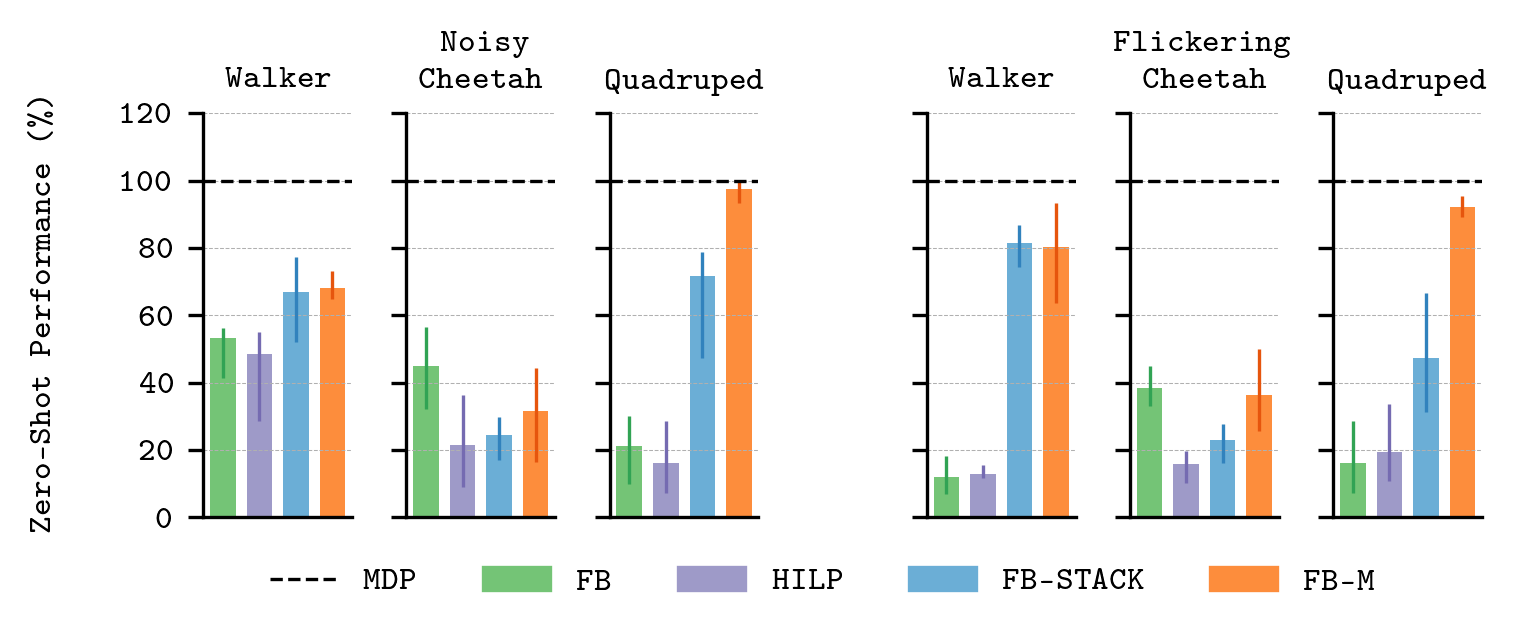
Figure 7: FB-M achieves near-oracle zero-shot returns in partially observed settings; standard FB and HILP baselines degrade sharply.
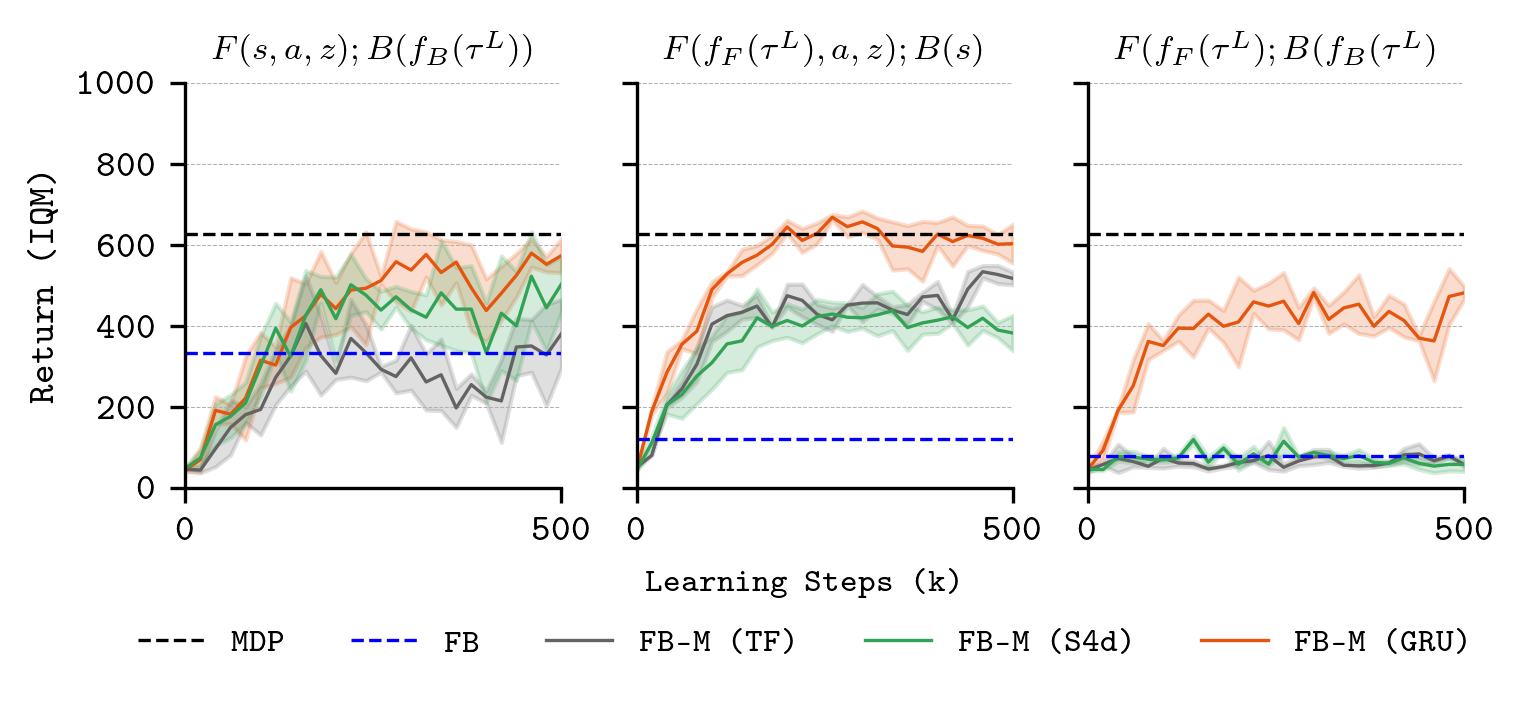
Figure 10: Sweeping memory model class: GRUs outperform transformers and S4 in integrating observation-action histories for POMDP environments.
The results indicate that, contrary to recent trends in NLP and vision, transformer and state-space models do not outperform well-tuned GRUs for partial observability in these RL settings, at least at the tested scale.
Deployability Without Prior Data: Emission-Efficient Control as Case Study
Traditional RL algorithms, especially deep model-free approaches, are sample-inefficient and thus impractical for zero-shot real-world deployment. The third constraint considered is data availability—the regime where only a short online commissioning window is permitted before the agent is tasked with real control.
The PEARL (Probabilistic Emission-Abating RL) algorithm is introduced as a concrete instantiation for emission-efficient building control: it leverages a probabilistic model ensemble for dynamics learning and model-predictive control with information-theoretic exploration during the brief commissioning period. With only 180 minutes of system identification, PEARL is able to reduce annual emissions by up to 31% vs. installed rule-based controllers, while maintaining user comfort and matching reward-pretrained oracles within 2.5% in performance.
Figure 9: PEARL architecture integrates probabilistic ensemble dynamics, information-driven exploration (system ID), and trajectory sampling for real-time MPC.
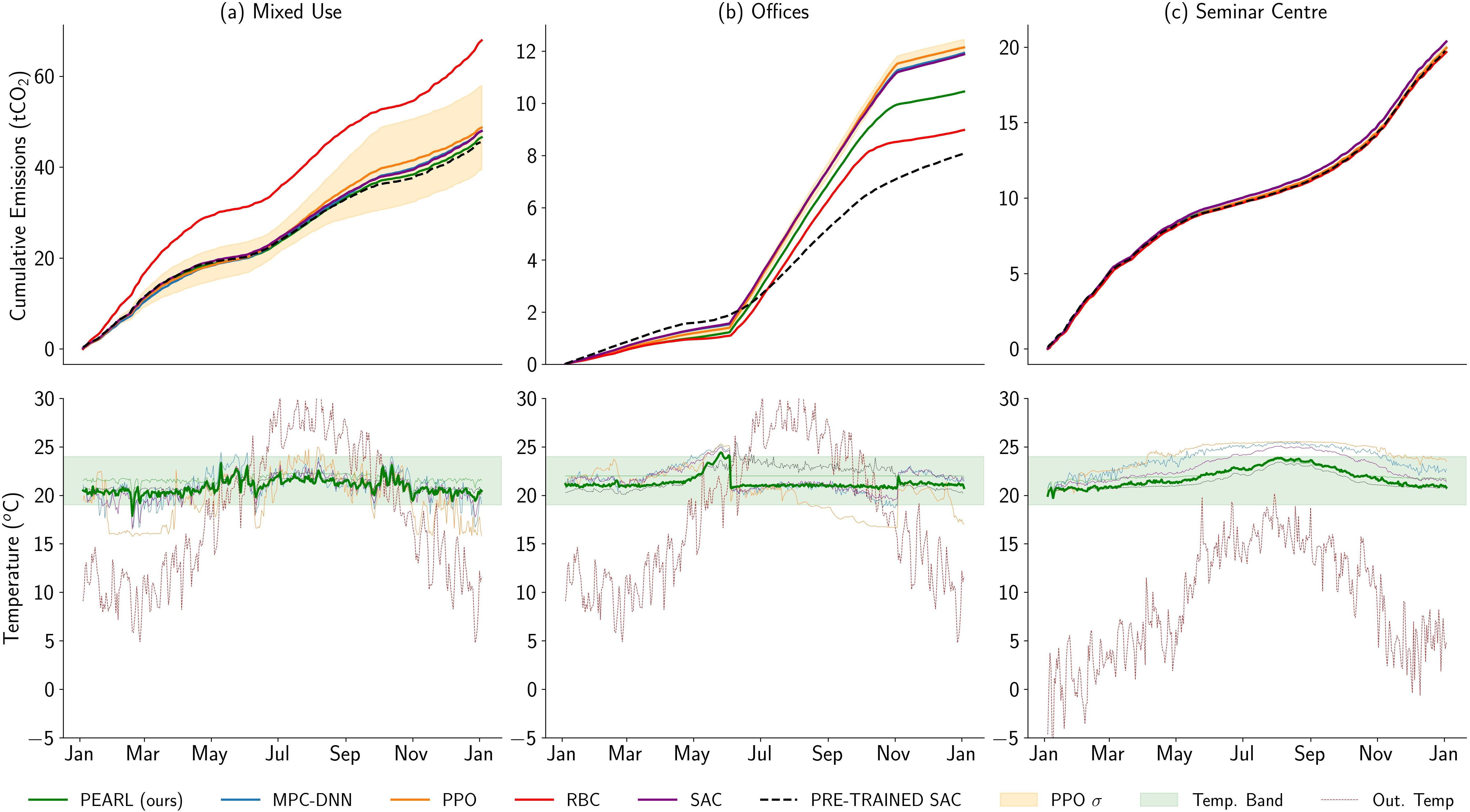
Figure 12: Across three buildings, PEARL agents achieve lowest emissions while maintaining thermal comfort; competing RL and MPC baselines either fail to achieve both or are substantially less data-efficient.
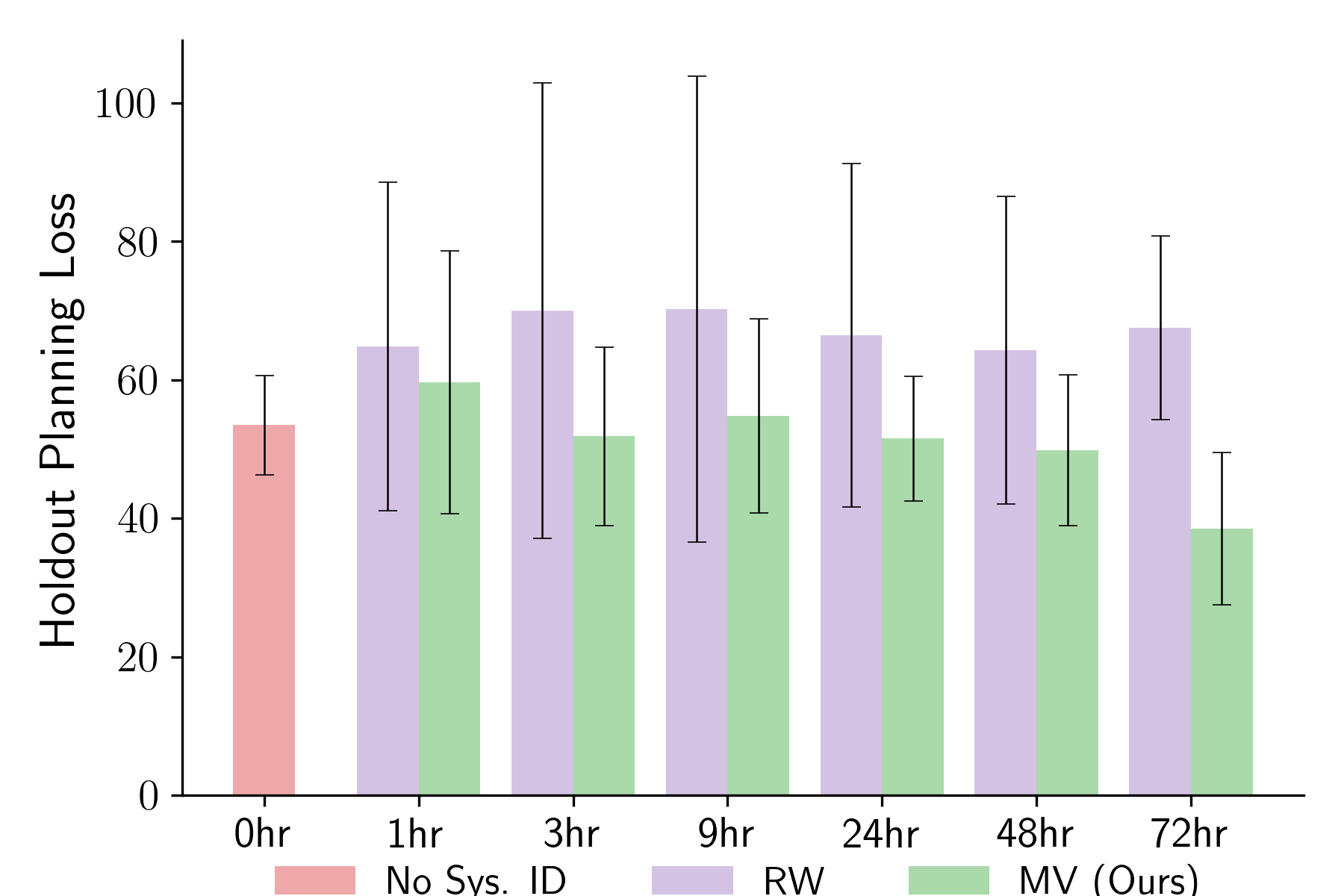
Figure 17: System identification error (MSE) post-commissioning correlates tightly with time allowed; MV exploration (PEARL) is more effective than random walk for short commissioning.
Notably, the architectural ablation shows that the choice of planner (MPPI vs. random shooting) dominates over whether probabilistic or deterministic dynamics models are used—a point in tension with some prior research emphasizing model uncertainty.
Implications, Contradictory Claims, and Open Challenges
Empirical Contradictions
- Generalist vs Single-Task: On diverse datasets, conservative zero-shot RL agents can outperform single-task baselines trained specifically for each task. However, they degrade on extremely low-diversity data, highlighting strong dependence on training coverage.
- Transformer Limitations: In partially observed RL, GRUs continue to outperform transformers and state-space models, contrary to scaling benefits observed in NLP/Vision.
- Planning Preferability: Within PEARL, advanced planning (e.g., MPPI) outweighs the impact of model stochasticity—contradicting prevailing claims about the necessity of probabilistic ensembles for robustness in low-data RL.
Theoretical Significance
The work formalizes with precision the constraints that must be met for zero-shot RL to be credible outside laboratory settings: data must be of low quality or unavailable; the world is only ever partially or noisily observed; and the agent's one-shot generalization ability must be robust to both.
Practical Considerations
- Regularization Scaling: Conservative regularization is not universal: hyperparameter sensitivity and dataset/task mismatch can lead to underperformance, particularly on real, narrow task distributions (e.g., D4RL).
- No Fine-tuning Advantage: Downstream finetuning of conservative FB models does not yield measurable practical improvement over retraining from scratch, suggesting representation traction for generalization is highly context-dependent and not easily reusable.
Future Outlook in AI and Zero-Shot RL
The concluding sections of the paper articulate two views of the scaling limits and promises for generalist RL:
- The Big World Hypothesis: The world is too complex to be simulated in full fidelity. Thus, continual learning, partial modeling, and online adaptation (à la PEARL/FB-M) remain essential research areas. Strict zero-shot generalization will always be an approximation, subject to irreducible error.
- The Platonic Representation Hypothesis: Model, data, and compute scaling could eventually allow foundation RL representations to converge on a statistical model sufficient for true zero-shot transfer across many or all real-world domains. If so, conservative and memory-augmented BFMs may become the main deployment interface for generalist RL systems.

Figure 13: Two hypotheses for world (and RL) simulability: in a "big world" continual partial modeling is essential; in a platonic limit, large models converge toward shared, highly compact representations.
Conclusion
"On Zero-Shot Reinforcement Learning" interrogates the practical feasibility of deploying offline pre-trained generalist RL agents in domains where data is non-ideal and real-time adaptation is infeasible. It exposes intrinsic value estimation pathologies, proposes new conservative architectures that mitigate risk under data constraints, and demonstrates that (contrary to some claims in the literature) classic recurrent architectures still dominate partially observed generalization. Notably, the empirical results suggest that with proper regularization and architectural selection, generalist agents can match or exceed their expert-tuned, single-task counterparts—though only when data coverage and representation learning regimes are sufficiently well matched to deployment needs.
These findings refine the established boundaries of zero-shot RL and clarify the technical challenges for foundation model RL architectures striving for real-world application.

