- The paper introduces a unified taxonomy categorizing LLM evidence-based text generation into parametric and non-parametric attribution approaches.
- It evaluates 300 diverse metrics for assessing citation accuracy, linguistic quality, and overall evidence verifiability in model outputs.
- The study highlights trends like retrieval-augmented generation and calls for hybrid methods to improve trustworthiness and standard evaluation frameworks.
Attribution, Citation, and Quotation: A Survey of Evidence-based Text Generation with LLMs
The paper "Attribution, Citation, and Quotation: A Survey of Evidence-based Text Generation with LLMs" (2508.15396) provides an exhaustive analysis of the landscape surrounding evidence-based text generation with LLMs. It examines the nuanced methodologies behind connecting model outputs to supporting evidence, ensuring trustworthiness and verifiability amidst growing concerns over LLM reliability.
Introduction
Recent progress in LLMs has yielded advances in language understanding and generation capabilities. However, these models are hindered by their propensity to generate hallucinations and their knowledge being limited to training data. This paper underscores the emergent need for evidence-based text generation, which emphasizes the production of text verifiable by explicit references to supporting documents. Despite the rising interest, this area lacks a unified terminology and standardized evaluation methodologies, contributing to a fragmented research landscape.
Unified Taxonomy and Key Dimensions
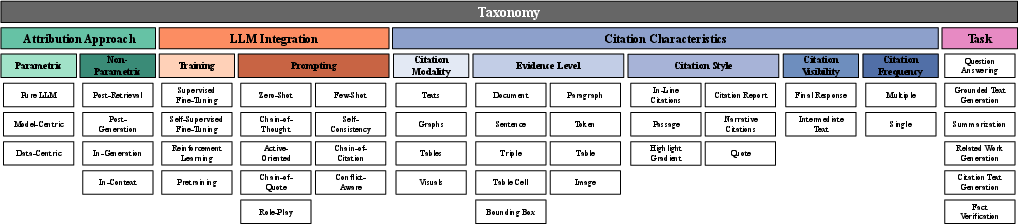
The authors propose a comprehensive taxonomy for evidence-based text generation, categorizing approaches into seven key attribution approaches, LLM integration strategies, citation characteristics, and task types.
Attribution Approaches are divided into parametric and non-parametric strategies. Parametric approaches rely on knowledge embedded within the model, while non-parametric approaches integrate external sources during inference:
Evaluation Metrics and Frameworks
In addressing the fragmented landscape of evaluation metrics, the survey categorizes 300 evaluation metrics into dimensions such as attribution, correctness, citation, linguistic quality, preservation, relevance, and retrieval. The citation-related dimensions are particularly critical, as they assess whether generated text properly references the correct evidence sources. Evaluation methods include human evaluation, inference-based, and retrieval-based metrics, ensuring comprehensive assessment across multiple facets.
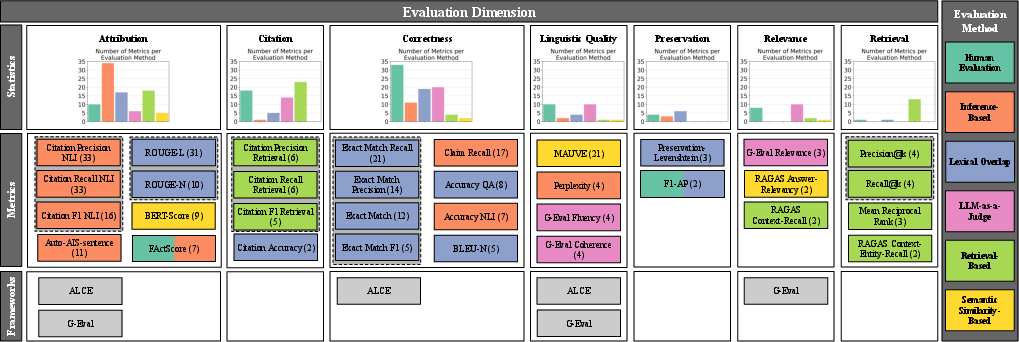
Figure 2: Evaluation metrics and frameworks for evidence-based text generation. The numbers in parentheses following each metric name indicate the number of studies that used the respective metric for evaluation. Metrics clustered by dashed lines are complementary metrics that should be used together for a comprehensive evaluation.
Trends and Challenges
The survey highlights trends such as the increasing reliance on retrieval-augmented generation (RAG) and the dominant role of prompting strategies over model retraining for guiding output attribution and correctness. It surfaces challenges related to integrating parametric attribution more robustly into LLMs to leverage their innate capacities without over-dependence on retrieval systems, which are often limited by their search capabilities.
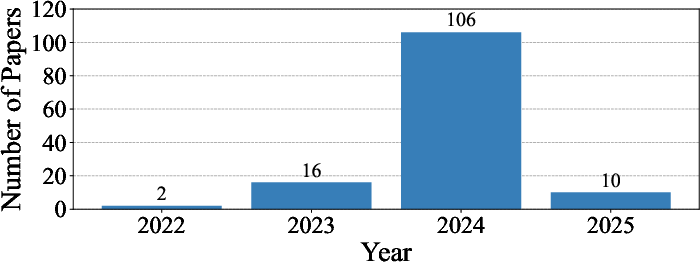
Figure 3: Number of studies per year.
Implications and Future Directions
The paper identifies several future research directions, including the necessity for hybrid attribution methods that effectively combine parametric and non-parametric strategies to enhance LLM trustworthiness and output verifiability. Moreover, there is an urgent call for standardized evaluation frameworks to facilitate fair comparisons across methods, ensuring that future innovations are grounded against consistent benchmarks. Additionally, improved explainability for citation reasoning is becoming imperative for bias mitigation and enhanced user trust.
Conclusion
By systematically categorizing evidence-based text generation approaches and evaluation metrics, this paper serves as a crucial cornerstone for unifying and advancing ongoing research in the field. The insights and frameworks provided lay a foundation for enhancing the reliability and authenticity of LLM-generated content, emphasizing the critical role of evidence-linked outputs in the ongoing evolution of AI models.