- The paper offers a comprehensive review of LLM-driven methodologies that enhance literature synthesis, hypothesis generation, and scientific content creation.
- The paper demonstrates the integration of retrieval-augmented, multimodal, and multi-agent systems, highlighting both promising results and challenges in factuality and bias.
- The paper calls for improved evaluation protocols, domain-specific datasets, and ethical guidelines to foster trustworthy, human-centric AI-assisted research.
Introduction
The paper "Transforming Science with LLMs: A Survey on AI-assisted Scientific Discovery, Experimentation, Content Generation, and Evaluation" (2502.05151) provides an extensive and systematic review of the integration of LLMs and multimodal foundation models into the scientific research lifecycle. The survey delineates the impact of LLMs across five core stages: literature search and summarization, hypothesis and idea generation, experimentation, content generation (textual and multimodal), and peer review. The authors also address the ethical, practical, and methodological challenges that arise from the adoption of these technologies in scientific workflows.
AI-Enhanced Literature Search and Synthesis
The exponential growth of scientific literature has rendered traditional search and review methods insufficient. The survey categorizes AI-driven literature search systems into six types: classical search engines, AI-enhanced semantic search, graph-based systems, paper chat/QA, recommender systems, and code/dataset-focused leaderboards. AI-enhanced systems leverage NLP, dense retrieval, and knowledge graphs to provide context-aware, semantically rich search and summarization capabilities, surpassing the limitations of keyword-based retrieval.
Graph-based systems, such as ORKG ASK, utilize structured representations of research contributions, enabling complex, domain-specific queries and facilitating evidence synthesis. Retrieval-augmented generation (RAG) architectures underpin many paper chat and QA systems, grounding LLM outputs in retrieved document segments to mitigate hallucinations and improve factuality. The survey highlights the importance of integrating citation graphs and user interaction data for recommender systems, with hybrid architectures (e.g., two-tower models) providing robust personalization and cold-start mitigation.
Despite these advances, the authors note persistent challenges: data quality and coverage gaps, algorithmic bias, and scalability constraints. They advocate for further research into personalization, interdisciplinary integration, and bias mitigation to ensure equitable and effective scientific discovery.
LLMs in Hypothesis Generation, Ideation, and Automated Experimentation
LLMs have demonstrated utility in hypothesis generation and ideation by synthesizing vast corpora of literature and external knowledge. The survey reviews recent methods addressing three primary technical challenges: hallucination reduction, long-context processing, and iterative refinement. Knowledge-grounded approaches, multi-agent frameworks, and few-shot/fine-tuning strategies are shown to improve the novelty, relevance, and testability of generated hypotheses.
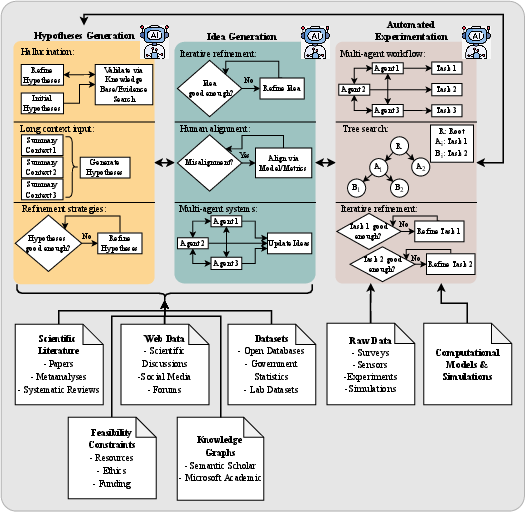
Figure 1: Overview of the hypothesis generation, idea generation and automatic experimentation process.
The integration of LLMs with computational tools enables automated experimentation, including AutoML, neural architecture search, and agentic workflows. Multi-agent systems, tree search algorithms, and iterative refinement pipelines are increasingly adopted to automate experimental design, execution, and analysis. Benchmarks such as ScienceAgentBench and SWE-bench provide rigorous evaluation protocols for these systems.
A notable empirical finding is that LLMs can generate hypotheses with high similarity to ground-truth discoveries, but their outputs are often overly general, lack methodological detail, and are sensitive to prompt framing. The survey underscores the need for domain-specific datasets, improved evaluation metrics (including LLM-as-a-metric and human-in-the-loop protocols), and enhanced multimodal reasoning capabilities.
Text-Based and Multimodal Content Generation
LLMs are now routinely employed for generating scientific titles, abstracts, related work sections, citations, and press releases. Transformer-based models (e.g., BART, T5, GPT-3.5/4) are evaluated for their ability to produce coherent, readable, and contextually appropriate content. However, the survey documents persistent issues with factual consistency, citation hallucination, and plagiarism detection. For instance, GPT-4 reduces citation fabrication rates compared to GPT-3.5, but non-trivial error rates remain.
In the multimodal domain, the survey reviews datasets and methods for scientific figure, table, slide, and poster generation and understanding. Recent work leverages LLMs and vision-LLMs (VLMs) for text-to-figure (e.g., TikZ code synthesis), chart-to-code, and figure QA tasks. Despite progress, open-source models lag behind proprietary systems (e.g., GPT-4o) in both generation and comprehension, particularly in STEM domains. Evaluation remains a bottleneck, with automatic metrics (e.g., DreamSim, CLIPScore, CrystalBLEU) showing limited correlation with expert human judgment.
The authors highlight the lack of large, diverse, and cross-domain datasets, the need for improved reasoning and grounding in multimodal generation, and the absence of robust evaluation protocols as key limitations.
AI-Assisted Peer Review and Scientific Evaluation
The peer review process is increasingly augmented by AI, with LLMs being used for review analysis, automatic feedback, score prediction, and meta-review generation. The survey details the use of pre-trained LLMs (e.g., SciBERT, PeerBERT) for argument mining, sentiment analysis, and review generation. Multi-agent LLM systems have been shown to outperform single-model baselines in review quality.
Automated claim verification and scientific rigor assessment are also addressed, with knowledge graph-based and LLM-based systems being developed to support fact-checking and adherence to domain-specific rigor criteria. However, the survey notes that LLMs exhibit cognitive and affiliation biases as evaluators, and their alignment with human judgment is limited (average RBO score of 44%).
The scarcity of annotated peer review datasets outside of computer science, the risk of bias amplification, and the need for human oversight are identified as critical challenges for trustworthy AI-assisted evaluation.
Ethical, Societal, and Methodological Considerations
The survey devotes significant attention to ethical concerns, including transparency, accountability, bias, privacy, and the risk of scientific misinformation. The authors synthesize findings from recent meta-analyses, highlighting issues such as hallucination, data leakage, and the commoditization of private data. They emphasize the necessity of transparent disclosure of AI usage in scientific writing and peer review, adherence to data protection laws, and the development of robust detection methods for AI-generated content.
The paper also discusses the limitations of current LLMs: brittleness, opacity, high resource consumption, and the lack of genuine creativity or understanding. The authors advocate for a human-centric approach, where AI serves as an assistive tool and ultimate responsibility remains with human researchers.
Implications and Future Directions
The integration of LLMs and multimodal models into scientific workflows has the potential to accelerate discovery, democratize access, and enhance the rigor and reproducibility of research. However, the survey makes several strong claims:
- LLMs can generate hypotheses and ideas with high novelty but lower feasibility compared to human researchers.
- Open-source models consistently underperform proprietary models in both text and multimodal tasks.
- Current evaluation metrics are inadequate for assessing the factuality, coherence, and scientific value of generated content.
- AI-assisted peer review systems exhibit significant bias and misalignment with human judgment.
The authors call for the development of domain-specific datasets, improved evaluation protocols (including LLM-as-a-metric and human-in-the-loop systems), and the integration of real-time, cross-modal, and cross-domain knowledge. They also stress the importance of ethical governance, transparency, and the preservation of human agency in scientific research.
Conclusion
This survey provides a comprehensive and critical assessment of the current landscape of AI-assisted scientific discovery, experimentation, content generation, and evaluation. While LLMs and multimodal models offer substantial opportunities for accelerating and democratizing science, their deployment introduces new challenges in factuality, bias, evaluation, and ethics. Addressing these challenges will require coordinated efforts in dataset curation, methodological innovation, and ethical governance to ensure that AI serves as a reliable and trustworthy partner in the scientific enterprise.