Leveraging Large Language Models for NLG Evaluation: Advances and Challenges
Abstract: In the rapidly evolving domain of Natural Language Generation (NLG) evaluation, introducing LLMs has opened new avenues for assessing generated content quality, e.g., coherence, creativity, and context relevance. This paper aims to provide a thorough overview of leveraging LLMs for NLG evaluation, a burgeoning area that lacks a systematic analysis. We propose a coherent taxonomy for organizing existing LLM-based evaluation metrics, offering a structured framework to understand and compare these methods. Our detailed exploration includes critically assessing various LLM-based methodologies, as well as comparing their strengths and limitations in evaluating NLG outputs. By discussing unresolved challenges, including bias, robustness, domain-specificity, and unified evaluation, this paper seeks to offer insights to researchers and advocate for fairer and more advanced NLG evaluation techniques.
- From images to sentences through scene description graphs using commonsense reasoning and knowledge. arXiv preprint arXiv:1511.03292.
- Towards a human-like open-domain chatbot. arXiv preprint arXiv:2001.09977.
- Benchmarking foundation models with language-model-as-an-examiner. arXiv preprint arXiv:2306.04181.
- Simple, scalable adaptation for neural machine translation. arXiv preprint arXiv:1909.08478.
- Findings of the 2020 conference on machine translation (WMT20). In Proceedings of the Fifth Conference on Machine Translation, pages 1–55, Online. Association for Computational Linguistics.
- Re-evaluating evaluation in text summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9347–9359, Online. Association for Computational Linguistics.
- The 2020 bilingual, bi-directional WebNLG+ shared task: Overview and evaluation results (WebNLG+ 2020). In Proceedings of the 3rd International Workshop on Natural Language Generation from the Semantic Web (WebNLG+), pages 55–76, Dublin, Ireland (Virtual). Association for Computational Linguistics.
- Evaluation of text generation: A survey. arXiv preprint arXiv:2006.14799.
- Chateval: Towards better llm-based evaluators through multi-agent debate. arXiv preprint arXiv:2308.07201.
- StoryER: Automatic story evaluation via ranking, rating and reasoning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1739–1753, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Exploring the use of large language models for reference-free text quality evaluation: A preliminary empirical study. arXiv preprint arXiv:2304.00723.
- Cheng-Han Chiang and Hung-yi Lee. 2023. Can large language models be an alternative to human evaluations? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15607–15631, Toronto, Canada. Association for Computational Linguistics.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Chatlaw: Open-source legal large language model with integrated external knowledge bases. arXiv preprint arXiv:2306.16092.
- A survey on legal judgment prediction: Datasets, metrics, models and challenges. IEEE Access.
- Learning to evaluate image captioning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5804–5812.
- SummEval: Re-evaluating summarization evaluation. Transactions of the Association for Computational Linguistics, 9:391–409.
- Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889–898, Melbourne, Australia. Association for Computational Linguistics.
- Findings of the 2021 conference on machine translation (wmt21). In Proceedings of the Sixth Conference on Machine Translation, pages 1–88. Association for Computational Linguistics.
- Experts, errors, and context: A large-scale study of human evaluation for machine translation. Transactions of the Association for Computational Linguistics, 9:1460–1474.
- BLEU might be guilty but references are not innocent. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 61–71, Online. Association for Computational Linguistics.
- Results of WMT22 metrics shared task: Stop using BLEU – neural metrics are better and more robust. In Proceedings of the Seventh Conference on Machine Translation (WMT), pages 46–68, Abu Dhabi, United Arab Emirates (Hybrid). Association for Computational Linguistics.
- Results of the WMT21 metrics shared task: Evaluating metrics with expert-based human evaluations on TED and news domain. In Proceedings of the Sixth Conference on Machine Translation, pages 733–774, Online. Association for Computational Linguistics.
- Gptscore: Evaluate as you desire. arXiv preprint arXiv:2302.04166.
- Human-like summarization evaluation with chatgpt. arXiv preprint arXiv:2304.02554.
- Trueteacher: Learning factual consistency evaluation with large language models. arXiv preprint arXiv:2305.11171.
- Chatgpt outperforms crowd-workers for text-annotation tasks. arXiv preprint arXiv:2303.15056.
- Samsum corpus: A human-annotated dialogue dataset for abstractive summarization. arXiv preprint arXiv:1911.12237.
- Topical-chat: Towards knowledge-grounded open-domain conversations. ArXiv, abs/2308.11995.
- A systematic survey on automated text generation tools and techniques: application, evaluation, and challenges. Multimedia Tools and Applications, pages 1–56.
- Newsroom: A dataset of 1.3 million summaries with diverse extractive strategies. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 708–719, New Orleans, Louisiana. Association for Computational Linguistics.
- OpenMEVA: A benchmark for evaluating open-ended story generation metrics. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 6394–6407, Online. Association for Computational Linguistics.
- Allure: A systematic protocol for auditing and improving llm-based evaluation of text using iterative in-context-learning. arXiv preprint arXiv:2309.13701.
- Teaching machines to read and comprehend. Advances in neural information processing systems, 28.
- Framing image description as a ranking task: Data, models and evaluation metrics. Journal of Artificial Intelligence Research, 47:853–899.
- Is chatgpt better than human annotators? potential and limitations of chatgpt in explaining implicit hate speech. arXiv preprint arXiv:2302.07736.
- Multi-dimensional evaluation of text summarization with in-context learning. arXiv preprint arXiv:2306.01200.
- Exploring chatgpt’s ability to rank content: A preliminary study on consistency with human preferences. arXiv preprint arXiv:2303.07610.
- Zero-shot faithfulness evaluation for text summarization with foundation language model. arXiv preprint arXiv:2310.11648.
- Tigerscore: Towards building explainable metric for all text generation tasks. arXiv preprint arXiv:2310.00752.
- Stylized data-to-text generation: A case study in the e-commerce domain. ACM Transactions on Information Systems.
- Open-domain dialogue generation: What we can do, cannot do, and should do next. In Proceedings of the 4th Workshop on NLP for Conversational AI, pages 148–165.
- MPST: A corpus of movie plot synopses with tags. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan. European Language Resources Association (ELRA).
- Critiquellm: Scaling llm-as-critic for effective and explainable evaluation of large language model generation. arXiv preprint arXiv:2311.18702.
- Prometheus: Inducing fine-grained evaluation capability in language models. arXiv preprint arXiv:2310.08491.
- Evallm: Interactive evaluation of large language model prompts on user-defined criteria. arXiv preprint arXiv:2309.13633.
- Tom Kocmi and Christian Federmann. 2023. Large language models are state-of-the-art evaluators of translation quality. In Proceedings of the 24th Annual Conference of the European Association for Machine Translation, pages 193–203, Tampere, Finland. European Association for Machine Translation.
- Benchmarking cognitive biases in large language models as evaluators. arXiv preprint arXiv:2309.17012.
- SummaC: Re-visiting NLI-based models for inconsistency detection in summarization. Transactions of the Association for Computational Linguistics, 10:163–177.
- The eval4nlp 2023 shared task on prompting large language models as explainable metrics. arXiv preprint arXiv:2310.19792.
- Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
- Generative judge for evaluating alignment. arXiv preprint arXiv:2310.05470.
- Generative judge for evaluating alignment. CoRR, abs/2310.05470.
- Prd: Peer rank and discussion improve large language model based evaluations. arXiv preprint arXiv:2307.02762.
- Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval.
- Holistic evaluation of language models. arXiv preprint arXiv:2211.09110.
- Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Yen-Ting Lin and Yun-Nung Chen. 2023. Llm-eval: Unified multi-dimensional automatic evaluation for open-domain conversations with large language models. arXiv preprint arXiv:2305.13711.
- A survey on neural data-to-text generation. IEEE Transactions on Knowledge and Data Engineering.
- How not to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation. arXiv preprint arXiv:1603.08023.
- X-eval: Generalizable multi-aspect text evaluation via augmented instruction tuning with auxiliary evaluation aspects. arXiv preprint arXiv:2311.08788.
- Alignbench: Benchmarking chinese alignment of large language models. arXiv preprint arXiv:2311.18743.
- Gpteval: Nlg evaluation using gpt-4 with better human alignment. arXiv preprint arXiv:2303.16634.
- Llms as narcissistic evaluators: When ego inflates evaluation scores. arXiv preprint arXiv:2311.09766.
- Yixin Liu and Pengfei Liu. 2021. SimCLS: A simple framework for contrastive learning of abstractive summarization. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 1065–1072, Online. Association for Computational Linguistics.
- Evaluate what you can’t evaluate: Unassessable generated responses quality. arXiv preprint arXiv:2305.14658.
- Calibrating llm-based evaluator. arXiv preprint arXiv:2309.13308.
- Error analysis prompting enables human-like translation evaluation in large language models: A case study on chatgpt. arXiv preprint arXiv:2303.13809.
- Chatgpt as a factual inconsistency evaluator for abstractive text summarization. arXiv preprint arXiv:2303.15621.
- Phrase-based statistical language generation using graphical models and active learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pages 1552–1561, Uppsala, Sweden. Association for Computational Linguistics.
- Results of the WMT20 metrics shared task. In Proceedings of the Fifth Conference on Machine Translation, pages 688–725, Online. Association for Computational Linguistics.
- Shikib Mehri and Maxine Eskenazi. 2020a. Unsupervised evaluation of interactive dialog with DialoGPT. In Proceedings of the 21th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 225–235, 1st virtual meeting. Association for Computational Linguistics.
- Shikib Mehri and Maxine Eskenazi. 2020b. USR: An unsupervised and reference free evaluation metric for dialog generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 681–707, Online. Association for Computational Linguistics.
- Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. arXiv preprint arXiv:2305.14251.
- OpenAI. 2023. Gpt-4 technical report.
- Text style transfer evaluation using large language models. arXiv preprint arXiv:2308.13577.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Understanding factuality in abstractive summarization with FRANK: A benchmark for factuality metrics. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4812–4829, Online. Association for Computational Linguistics.
- Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
- Learning to score system summaries for better content selection evaluation. In Proceedings of the Workshop on New Frontiers in Summarization, pages 74–84, Copenhagen, Denmark. Association for Computational Linguistics.
- T5score: Discriminative fine-tuning of generative evaluation metrics.
- COMET: A neural framework for MT evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685–2702, Online. Association for Computational Linguistics.
- A survey of evaluation metrics used for nlg systems. ACM Computing Surveys (CSUR), 55(2):1–39.
- BLEURT: Learning robust metrics for text generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7881–7892, Online. Association for Computational Linguistics.
- Yuchen Shen and Xiaojun Wan. 2023. Opinsummeval: Revisiting automated evaluation for opinion summarization. arXiv preprint arXiv:2310.18122.
- Societal biases in language generation: Progress and challenges. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4275–4293.
- Significant Gravitas. AutoGPT.
- Large language models encode clinical knowledge. Nature, 620(7972):172–180.
- Towards better evaluation of instruction-following: A case-study in summarization. arXiv preprint arXiv:2310.08394.
- A study of translation edit rate with targeted human annotation. In Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers, pages 223–231.
- Evaluation metrics in the era of gpt-4: Reliably evaluating large language models on sequence to sequence tasks. arXiv preprint arXiv:2310.13800.
- Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615.
- Not all metrics are guilty: Improving nlg evaluation with llm paraphrasing. arXiv preprint arXiv:2305.15067.
- Zerocap: Zero-shot image-to-text generation for visual-semantic arithmetic. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17918–17928.
- Brian Thompson and Matt Post. 2020. Automatic machine translation evaluation in many languages via zero-shot paraphrasing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 90–121, Online. Association for Computational Linguistics.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575.
- Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE transactions on pattern analysis and machine intelligence, 39(4):652–663.
- Asking and answering questions to evaluate the factual consistency of summaries. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5008–5020, Online. Association for Computational Linguistics.
- Learning personalized story evaluation. arXiv preprint arXiv:2310.03304.
- Is chatgpt a good nlg evaluator? a preliminary study. arXiv preprint arXiv:2303.04048.
- Large language models are not fair evaluators. arXiv preprint arXiv:2305.17926.
- Shepherd: A critic for language model generation. arXiv preprint arXiv:2308.04592.
- Task-oriented dialogue system as natural language generation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2698–2703.
- Automated evaluation of personalized text generation using large language models. arXiv preprint arXiv:2310.11593.
- Pandalm: An automatic evaluation benchmark for llm instruction tuning optimization. arXiv preprint arXiv:2306.05087.
- Self-instruct: Aligning language models with self-generated instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13484–13508, Toronto, Canada. Association for Computational Linguistics.
- Finetuned language models are zero-shot learners. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Semantically conditioned LSTM-based natural language generation for spoken dialogue systems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1711–1721, Lisbon, Portugal. Association for Computational Linguistics.
- Large language models are diverse role-players for summarization evaluation. arXiv preprint arXiv:2303.15078.
- Less is more for long document summary evaluation by llms. arXiv preprint arXiv:2309.07382.
- Instructscore: Towards explainable text generation evaluation with automatic feedback. arXiv preprint arXiv:2305.14282.
- Fingpt: Open-source financial large language models. arXiv preprint arXiv:2306.06031.
- DOC: Improving long story coherence with detailed outline control. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3378–3465, Toronto, Canada. Association for Computational Linguistics.
- Re3: Generating longer stories with recursive reprompting and revision. arXiv preprint arXiv:2210.06774.
- Bartscore: Evaluating generated text as text generation. In Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 27263–27277.
- Automatic evaluation of attribution by large language models. arXiv preprint arXiv:2305.06311.
- Evaluating large language models at evaluating instruction following. arXiv preprint arXiv:2310.07641.
- Summit: Iterative text summarization via chatgpt. arXiv preprint arXiv:2305.14835.
- Personalizing dialogue agents: I have a dog, do you have pets too? arXiv preprint arXiv:1801.07243.
- Bertscore: Evaluating text generation with BERT. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
- Wider and deeper llm networks are fairer llm evaluators. arXiv preprint arXiv:2308.01862.
- MoverScore: Text generation evaluating with contextualized embeddings and earth mover distance. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 563–578, Hong Kong, China. Association for Computational Linguistics.
- Investigating table-to-text generation capabilities of llms in real-world information seeking scenarios.
- Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685.
- Towards language-free training for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17907–17917.
- Terry Yue Zhuo. 2023. Large language models are state-of-the-art evaluators of code generation. arXiv preprint arXiv:2304.14317.
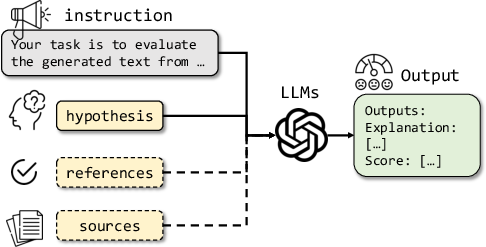
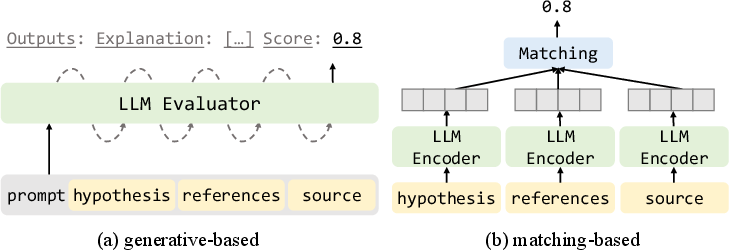

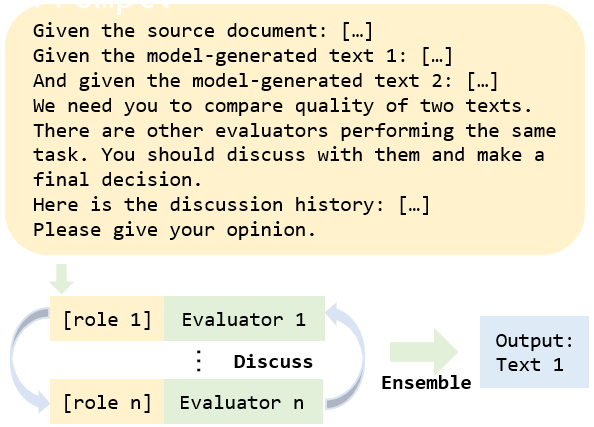
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.