- The paper introduces ENA, demonstrating that combining linear recurrence with high-order sliding window attention enables efficient long sequence processing.
- The paper employs DeltaNet and Sliding Tile Attention to compress global context while preserving local details, enhancing classification and generation tasks.
- The paper shows that ENA scales to sequences up to 16K tokens with high sparsity, achieving competitive performance with improved computational efficiency.
ENA: Efficient N-dimensional Attention
Introduction
The paper presents ENA (Efficient N-dimensional Attention), an innovative architecture that combines linear recurrence models with high-order sliding window attention (SWA) to efficiently process long sequences of high-dimensional data. The focus is on overcoming the limitations of traditional Transformers, particularly their inefficiencies in handling long sequences due to quadratic complexity in softmax attention. The ENA architecture offers a promising alternative by interleaving layers of linear recurrence with local attention, promoting both efficiency and expressiveness in sequence modeling.
Architecture and Implementation
The ENA architecture is structurally simple yet effective. It employs layers of linear recurrence interleaved with sliding window attention (SWA). This hybrid approach is designed to compress global context with linear models while maintaining local fidelity with attention mechanisms. High-order SWA is particularly chosen for its ability to model locality without non-overlapping block constraints, unlike block attention.
The implementation of ENA leverages DeltaNet as the primary linear recurrence model, renowned for its efficient training and expressiveness, while STA (Sliding Tile Attention) is used for attention due to its hardware efficiency. ENA avoids the traditional overheads associated with scanning and sequence permutation, emphasizing simplicity and speed.
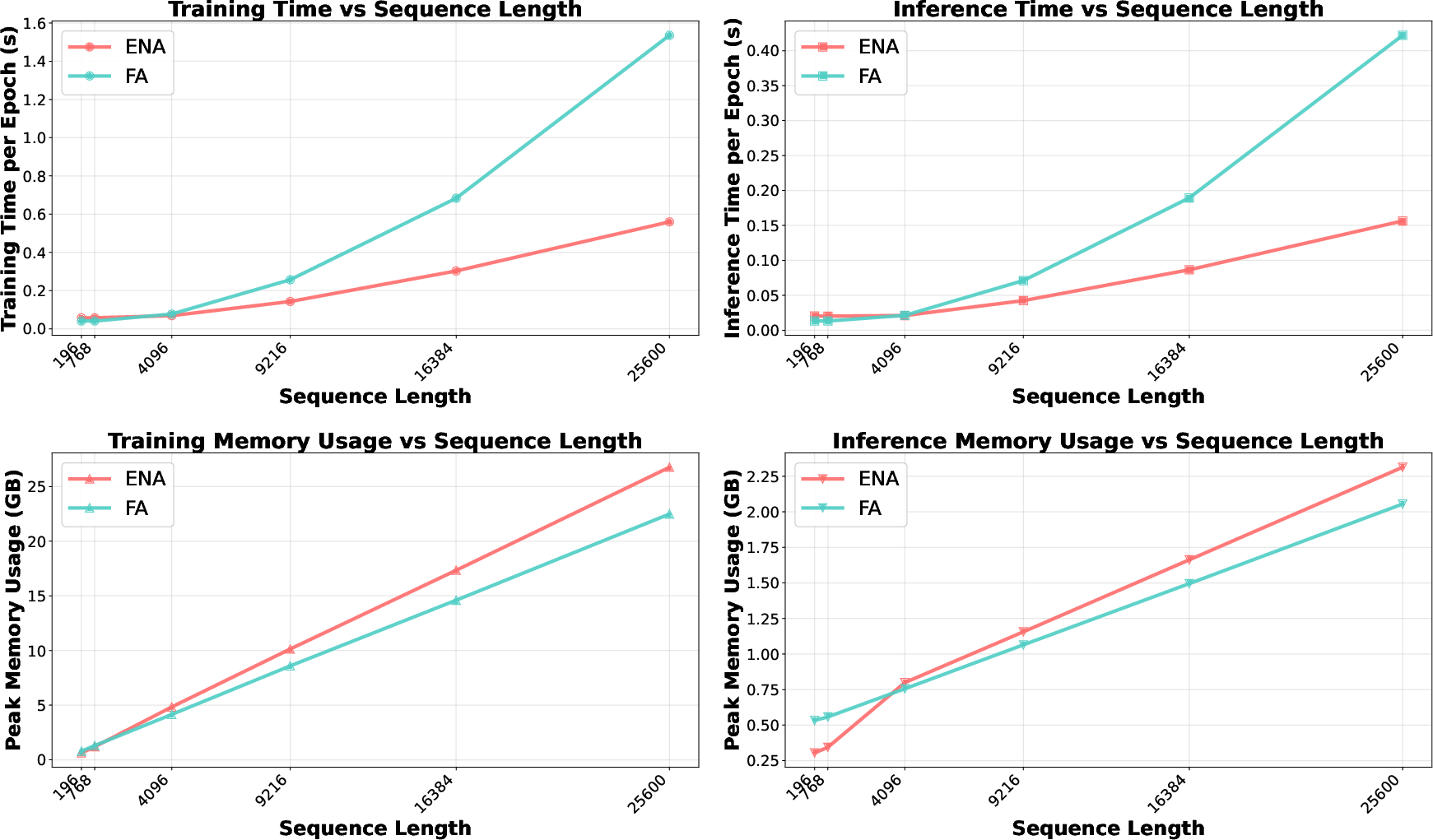
Figure 1: Performance comparison between ENA and Flash Attention (FA)-based Transformer vision encoders across different sequence lengths.
Experimental Validation
The effectiveness of ENA is demonstrated through extensive experiments across various tasks, including image and video classification and generation. The key results include:
- Image and Video Classification: On datasets such as ImageNet-1K and K400, ENA achieves comparable or superior performance to Transformers, with significant improvements in computational efficiency, particularly for long sequences.
- Image Generation: The application of ENA to image generation tasks confirms its benefits. The model achieves competitive IS and FID scores on ImageNet, underscoring the robustness of combining linear recurrence with sparse attention.
- Long Sequence Processing: For very long sequences (up to 16K tokens), ENA demonstrates its scalability, maintaining performance with reduced computational demands. Adjusting the sparsity in attention allows ENA to match full attention without the associated complexity.

Figure 2: Selected image generation results from ena-deltanet-sta-w24x24-t8x8-xl-gen2d on ImageNet with a resolution of 512 \times 512.
The paper provides a thorough discussion of the design choices in ENA, particularly the trade-offs between scanning and hybrid architectures. The finding that hybrid models outperform scanning techniques aligns with the observation that effective local attention compensates for any inefficiencies in linear models regarding local pattern recognition.
Attention sparsity emerges as a critical factor, where ENA's performance maintains robustness even with high levels of sparsity (up to 70%), facilitating faster computation without significant losses in accuracy. The scalability of ENA is further highlighted by its adaptability across varying data dimensions and sequence lengths.
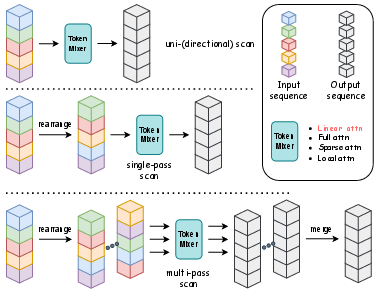
Figure 3: A simple illustration of the operations performed by different scanning methods.
Implications and Future Directions
The introduction of ENA underscores a shift towards hybrid architectures in AI, especially for tasks involving high-dimensional data and long sequence dependencies. ENA's design strategies prioritize computational efficiency and scalability, making it conducive for deployment in resource-constrained environments.
The paper suggests potential enhancements in STA implementations for further speed gains, indicating future research avenues in optimizing kernel designs for attention mechanisms. The discussion on the choice of optimizers and learning rates offers insights into the flexibility of the ENA framework across different training paradigms and conditions.
Conclusion
ENA positions itself as a viable successor to traditional transformers for sequence modeling tasks. By marrying linear recurrent networks with local attention, ENA not only improves efficiency but also simplifies architectural complexity. As AI systems demand more computational resources, architectures like ENA that balance performance with efficiency will gain prominence, encouraging further research into hybrid models and attention mechanisms.