- The paper introduces novel 1-bit and 2-bit microkernels that significantly enhance LLM inference efficiency on modern CPUs.
- It employs a VNNI4-interleaved tensor layout to streamline unpacking low-bit weights into optimized 8-bit operations using AVX2 instructions.
- End-to-end tests show up to 7x speedups over 16-bit inferences and marked improvements compared to state-of-the-art AA frameworks.
Advancements in Ultra-Low-Bit Quantization for LLM Inference
Recent developments in the field of neural network inference for resource-constrained environments have highlighted the potential of ultra-low-bit quantized models. This paper, "Pushing the Envelope of LLM Inference on AI-PC" (2508.06753), details the design and implementation of optimized microkernels for LLMs using 1-bit and 2-bit quantization levels. The study focuses on integrating these microkernels into existing frameworks to substantially improve computational efficiency for AI personal computers and edge devices.
Introduction to Ultra-Low-Bit Quantization
Ultra-low-bit quantization (1-bit, 1.58-bit, and 2-bit) significantly reduces the precision of model weights while maintaining performance levels that rival full-precision models. The paper emphasizes the potential benefits of this approach, which include reduced latency, memory usage, and energy demands during inference—a crucial consideration for deployment on edge devices. Despite these advantages, current state-of-the-art runtimes like bitnet.cpp often fail to capitalize on these savings efficiently.
The primary contribution of this research is a bottom-up approach that involves the creation of highly efficient 1-bit and 2-bit microkernels. These kernels, optimized for modern CPUs, achieve unprecedented levels of computational efficiency and are integrated into the PyTorch-TPP framework. The end-to-end inference results indicate performance improvements over existing benchmarks, including the bitnet.cpp runtime.
Design and Implementation of Microkernels
Interleaved Tensor Layout for 2-bit and 1-bit Weights
The innovative tensor layout termed "VNNI4-interleaved" is a pivotal development for efficiently processing 2-bit weights. This method simplifies the process of unpacking 2-bit values to 8-bit integers, which is critical for executing high-throughput vectorized operations using AVX2 instructions on CPUs.

Figure 1: Unpacking the int2 VNNI4-interleaved format to int8 VNNI4.
Microkernel Architecture
The research outlines specific microkernels developed for 2-bit and 1-bit GEMM operations. For instance, the 2-bit GEMM kernel leverages the interleaved tensor format to efficiently handle matrix-vector multiplications. It minimizes performance overheads associated with typical unpacking processes, thus achieving near-roofline performance on AVX2-capable CPUs.

Figure 2: AVX2 GEMM microkernel with int2 weights (matrix AM×K, int8 activations, and int8 VNNI FMAs).
Roofline models were constructed to estimate the effective bandwidth for these ultra-low-bit operations, considering different CPU core types (P-cores and E-cores). This approach enables thorough performance characterization, demonstrating where these microkernels operate close to the platform's theoretical throughput limits.
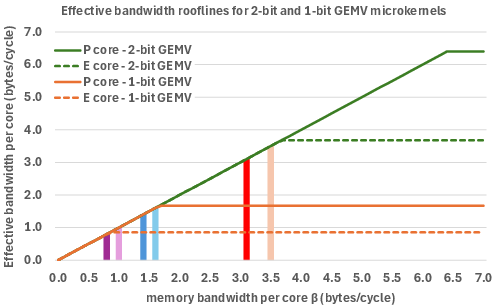
Figure 3: Effective bandwidth rooflines for 2-bit and 1-bit GEMV microkernels considering P and E cores.
GEMV Microbenchmarks
The paper reports that the newly developed 2-bit microkernels often achieve performance within 20% of the theoretical maximum across various contemporary x86 CPUs. However, 1-bit microkernels demonstrate varied results, dependent on the specific processor architecture and available memory bandwidth.
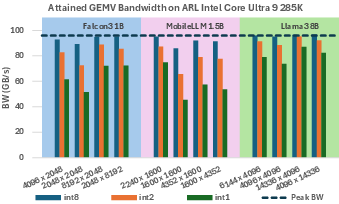
Figure 4: Attained GEMV bandwidth on ARL for various matrix shapes and precisions (int/int2/int1).
Performance metrics from end-to-end inference tests show substantial speedups: up to 7 times faster than 16-bit model inference and up to 2.2 times faster compared to SOTA bitnet.cpp for 2-bit models. These results substantiate the ultra-efficient deployment of quantized models for real-world applications.
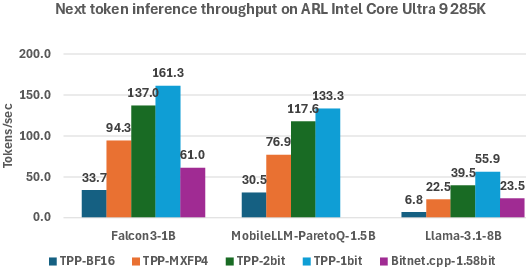
Figure 5: End-to-end inference on ARL, contrasting performance across multiple quantization levels and frameworks.
Conclusion
The findings of this paper establish a new benchmark for the deployment of low-precision LLMs on CPUs, enabling near-GPU level performance in inference tasks—a necessary progression for enhancing the computational capacity of AI-powered devices while maintaining cost efficiency. Future directions include further adaptation for ARM architectures, which would naturally support the proposed approaches due to similar instruction set capabilities.