A Survey on Visual Mamba
Abstract: State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
- Frank Rosenblatt. The perceptron, a perceiving and recognizing automaton Project Para. Cornell Aeronautical Laboratory, 1957.
- Frank Rosenblatt et al. Principles of neurodynamics: Perceptrons and the theory of brain mechanisms, volume 55. Spartan books Washington, DC, 1962.
- Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012.
- Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
- A decomposable attention model for natural language inference. arXiv preprint arXiv:1606.01933, 2016.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
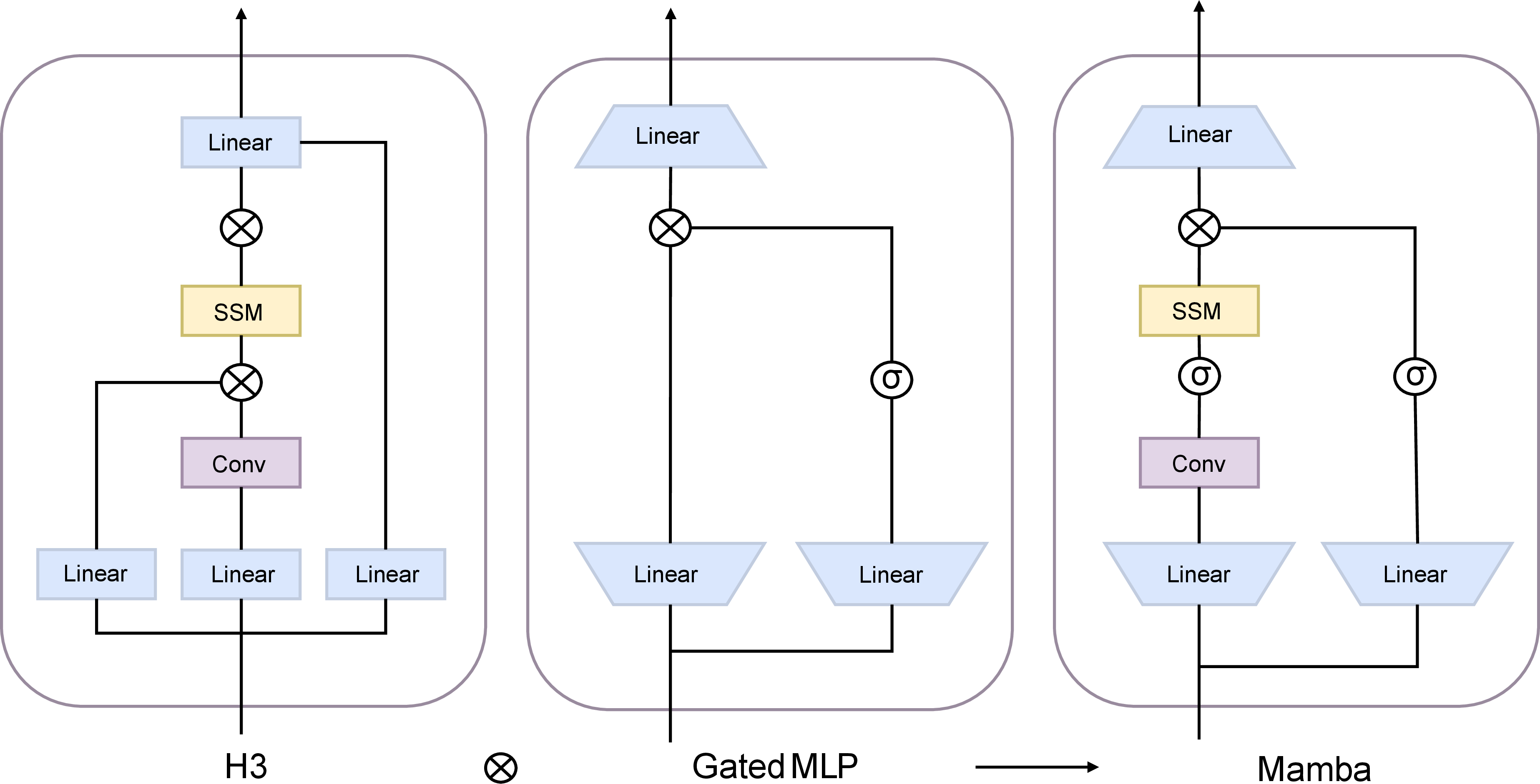
- Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023.
- Jamba: A hybrid transformer-mamba language model. arXiv preprint arXiv:2403.19887, 2024.
- Moe-mamba: Efficient selective state space models with mixture of experts. arXiv preprint arXiv:2401.04081, 2024.
- Blackmamba: Mixture of experts for state-space models. arXiv preprint arXiv:2402.01771, 2024.
- Hungry hungry hippos: Towards language modeling with state space models. arXiv preprint arXiv:2212.14052, 2022.
- Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- Swish: a self-gated activation function. arXiv: Neural and Evolutionary Computing, 2017.
- Retentive network: A successor to transformer for large language models. arXiv preprint arXiv:2307.08621, 2023.
- Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pages 5156–5165. PMLR, 2020.
- Hyena hierarchy: Towards larger convolutional language models. In International Conference on Machine Learning, pages 28043–28078. PMLR, 2023.
- Ckconv: Continuous kernel convolution for sequential data. arXiv preprint arXiv:2102.02611, 2021.
- Retentive network: A successor to transformer for large language models (2023). URL http://arxiv. org/abs/2307.08621 v1.
- An attention free transformer. arXiv preprint arXiv:2105.14103, 2021.
- Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048, 2023.
- Can recurrent neural networks warp time? arXiv preprint arXiv:1804.11188, 2018.
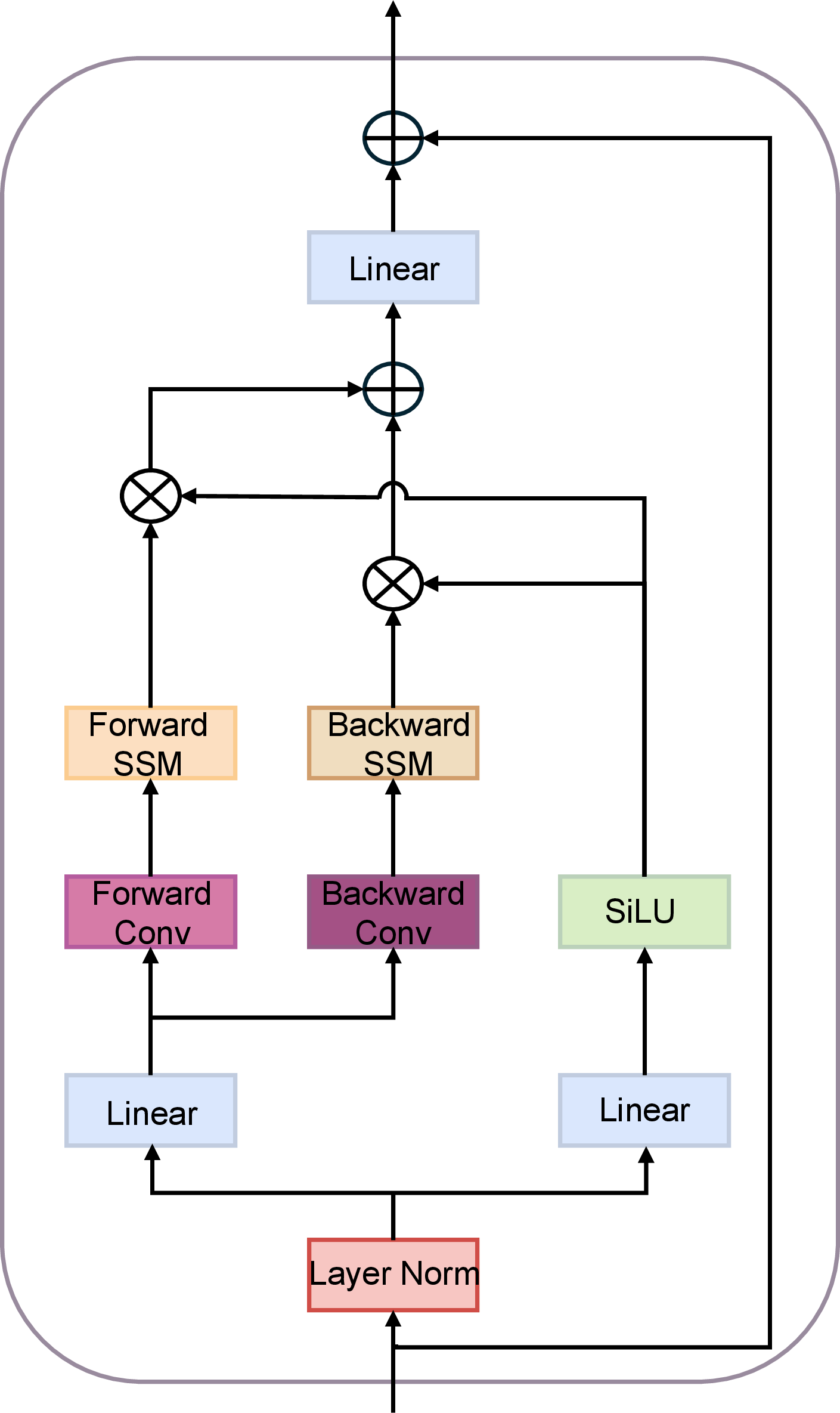
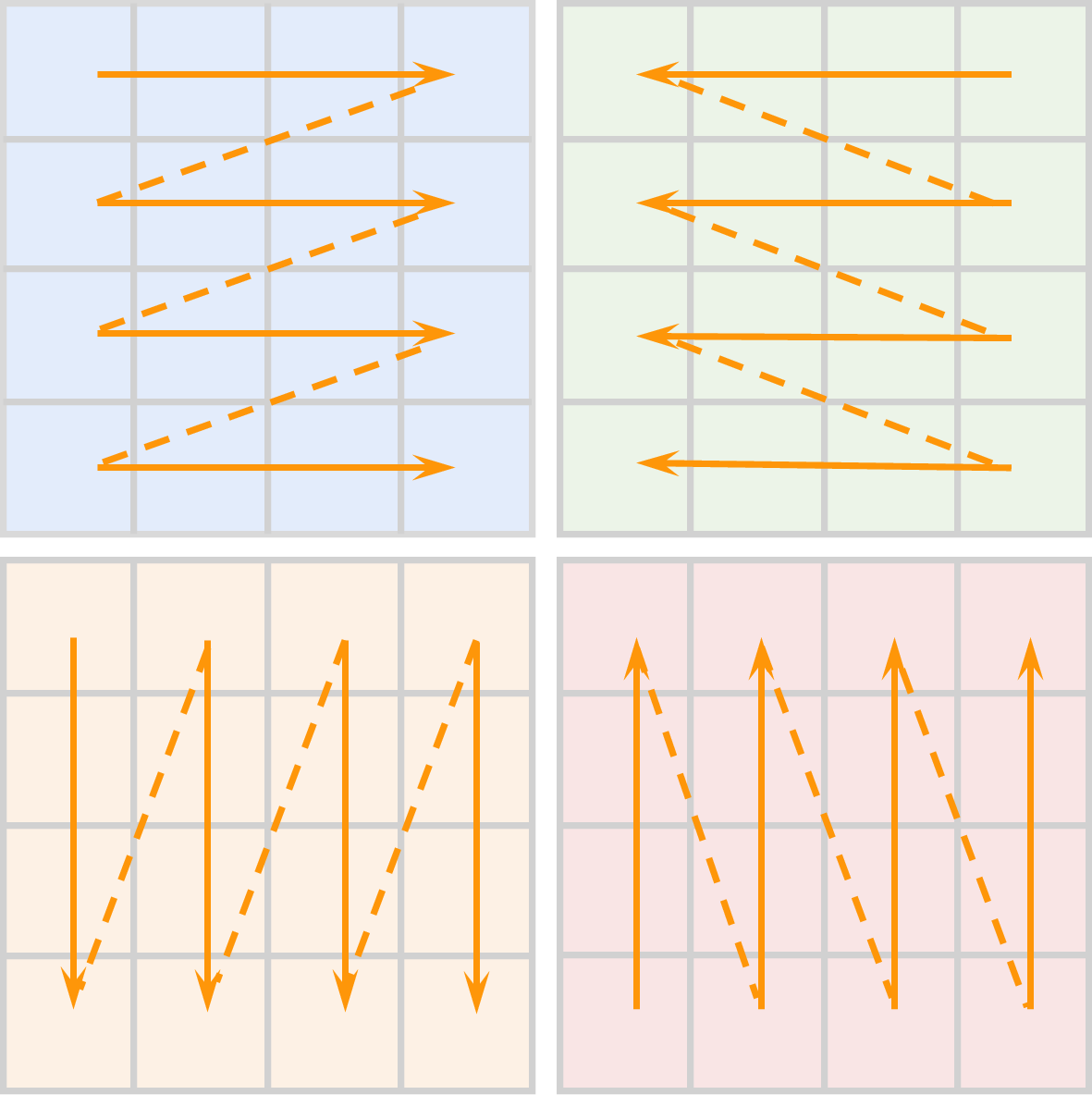
- Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv preprint arXiv:2401.09417, 2024.
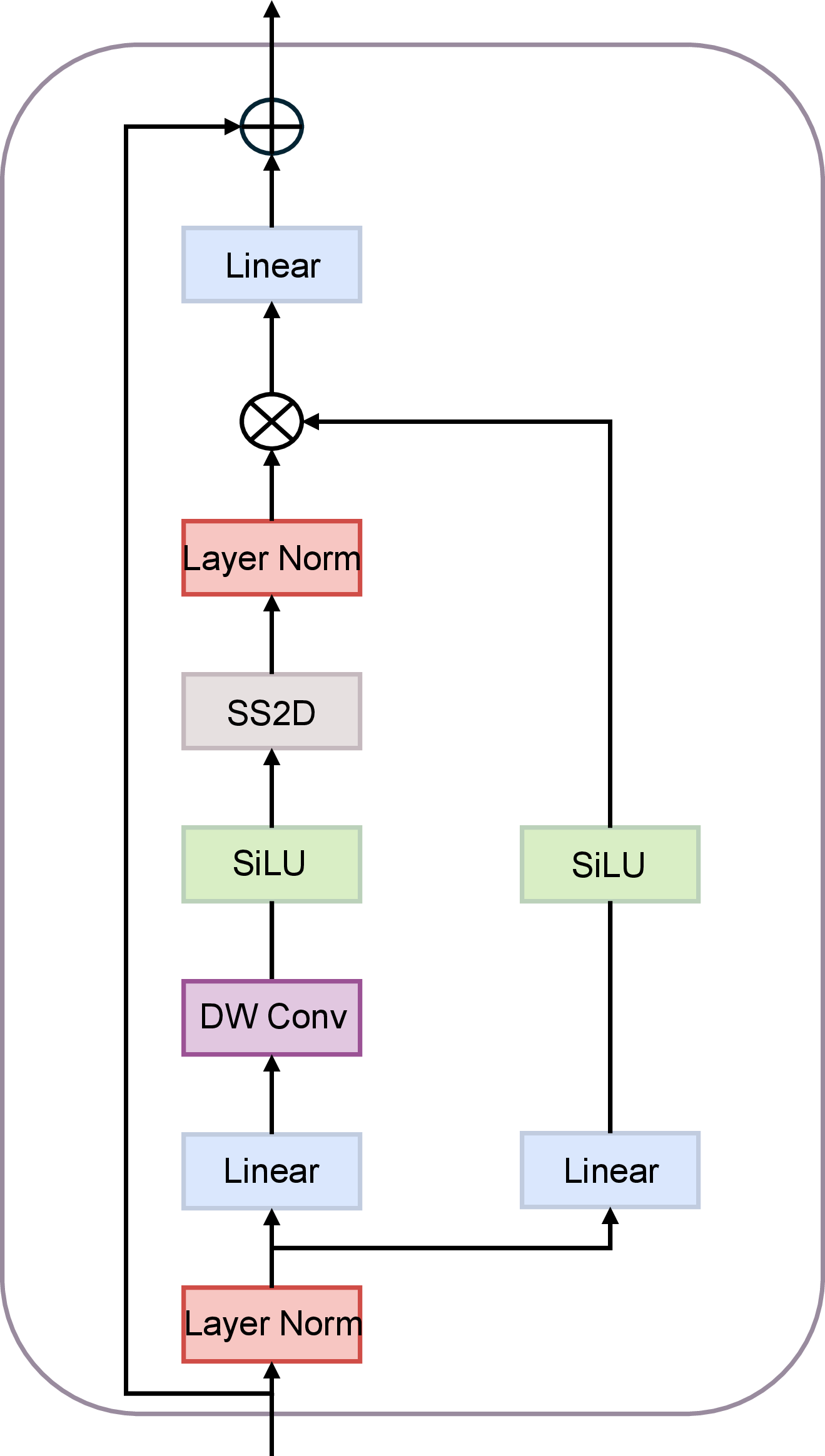
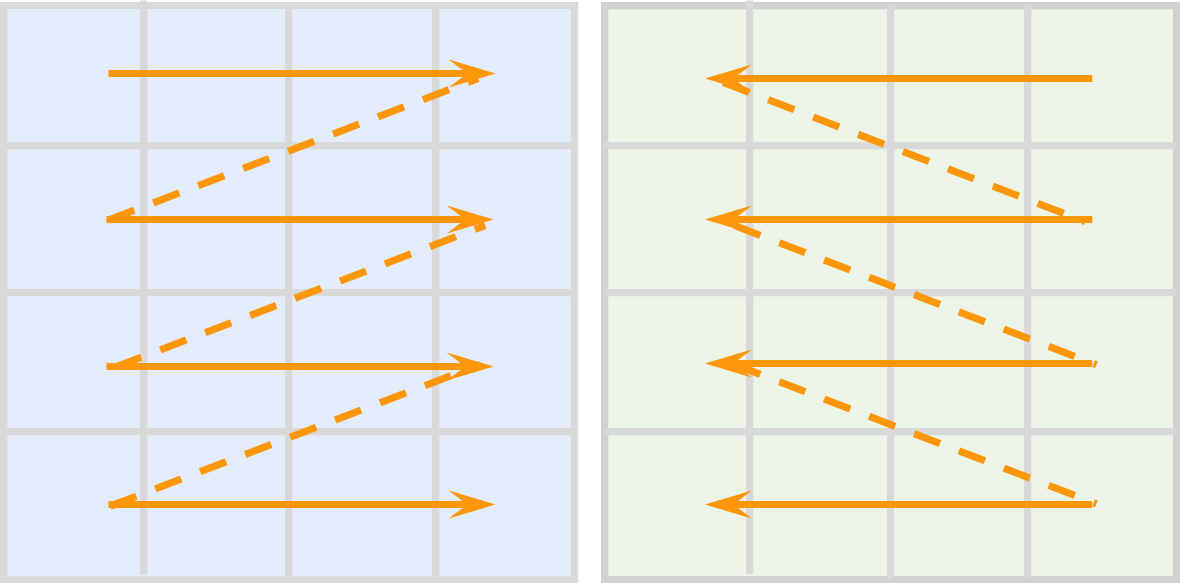
- Vmamba: Visual state space model. arXiv preprint arXiv:2401.10166, 2024.
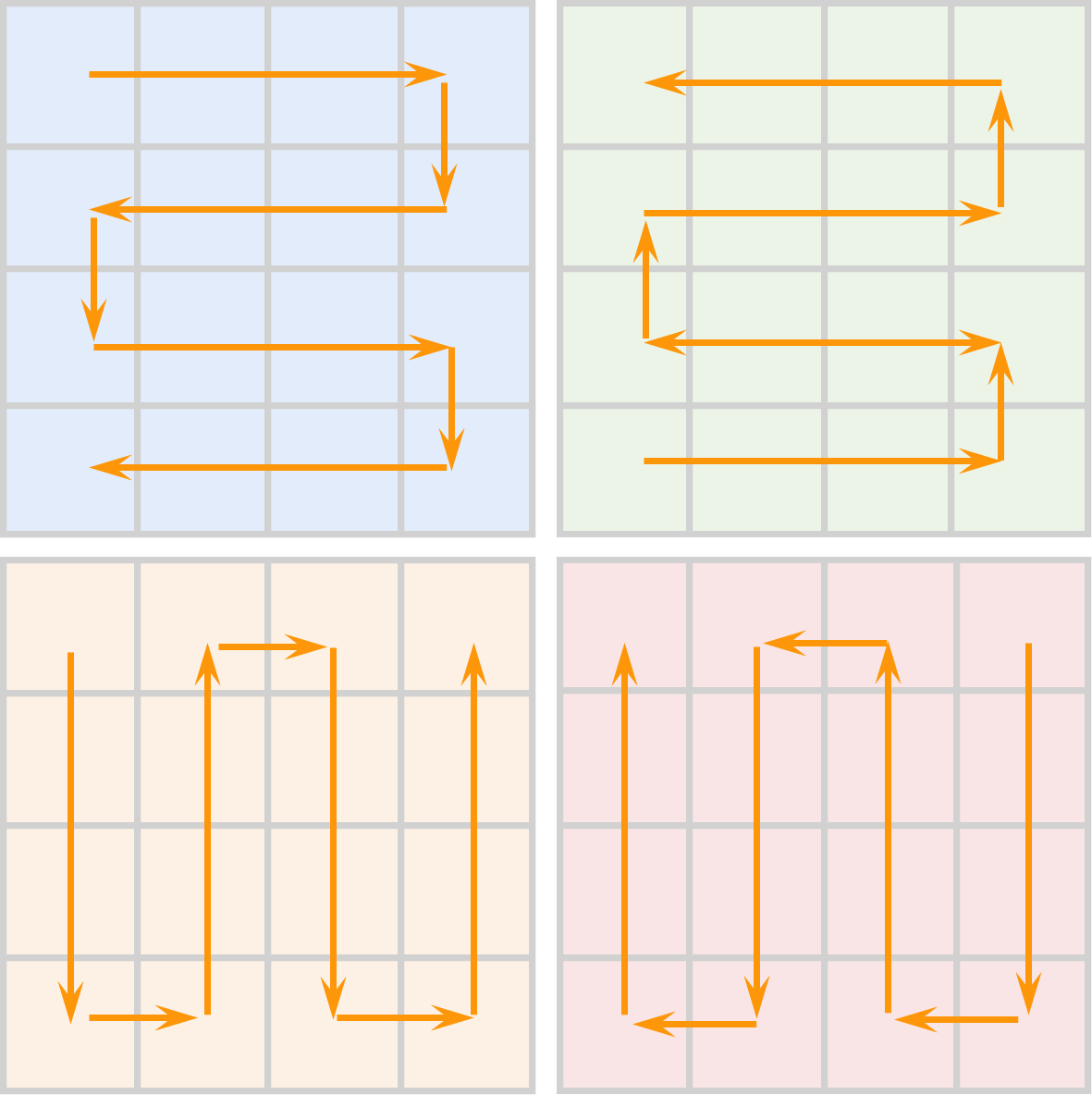
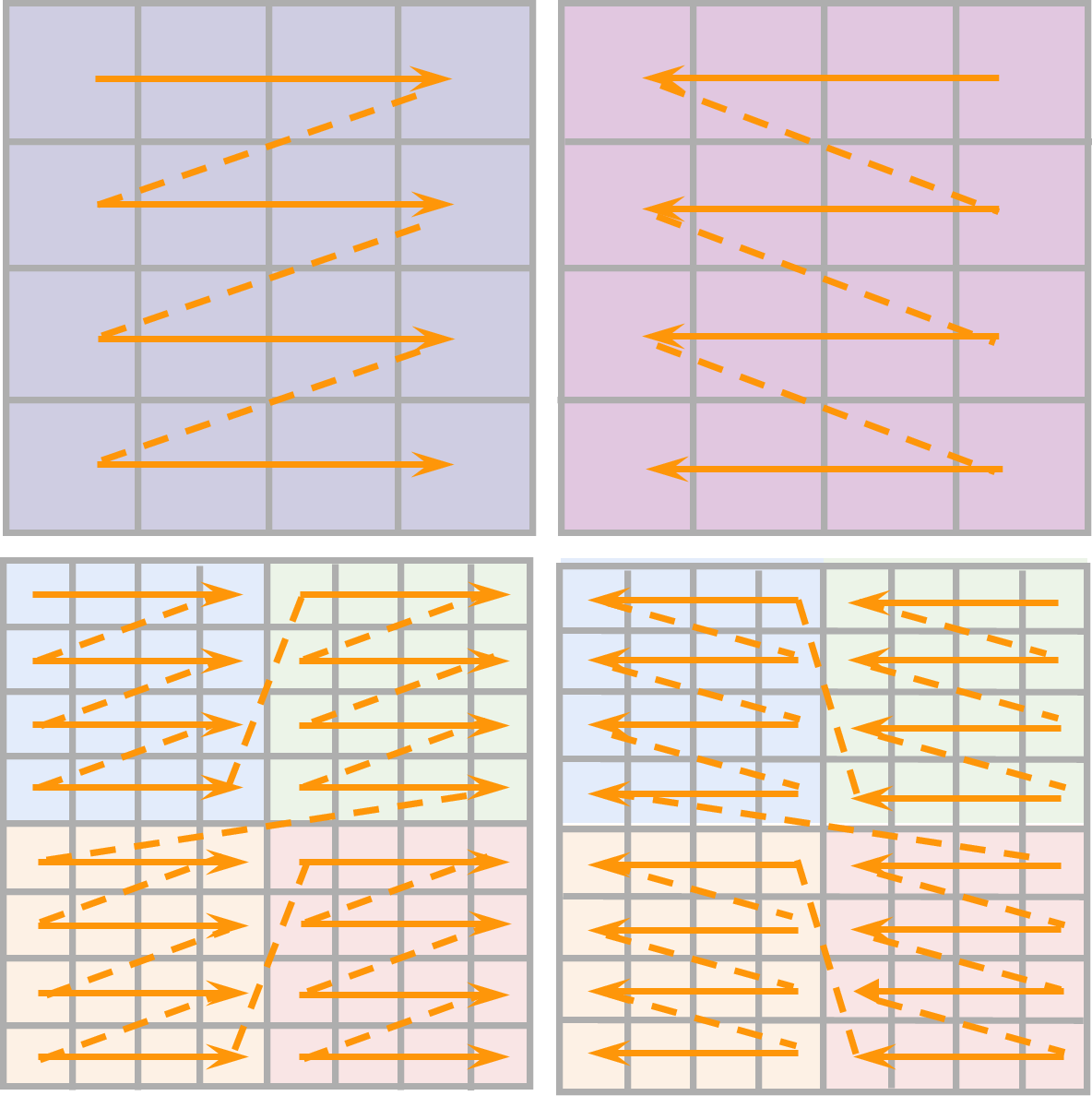
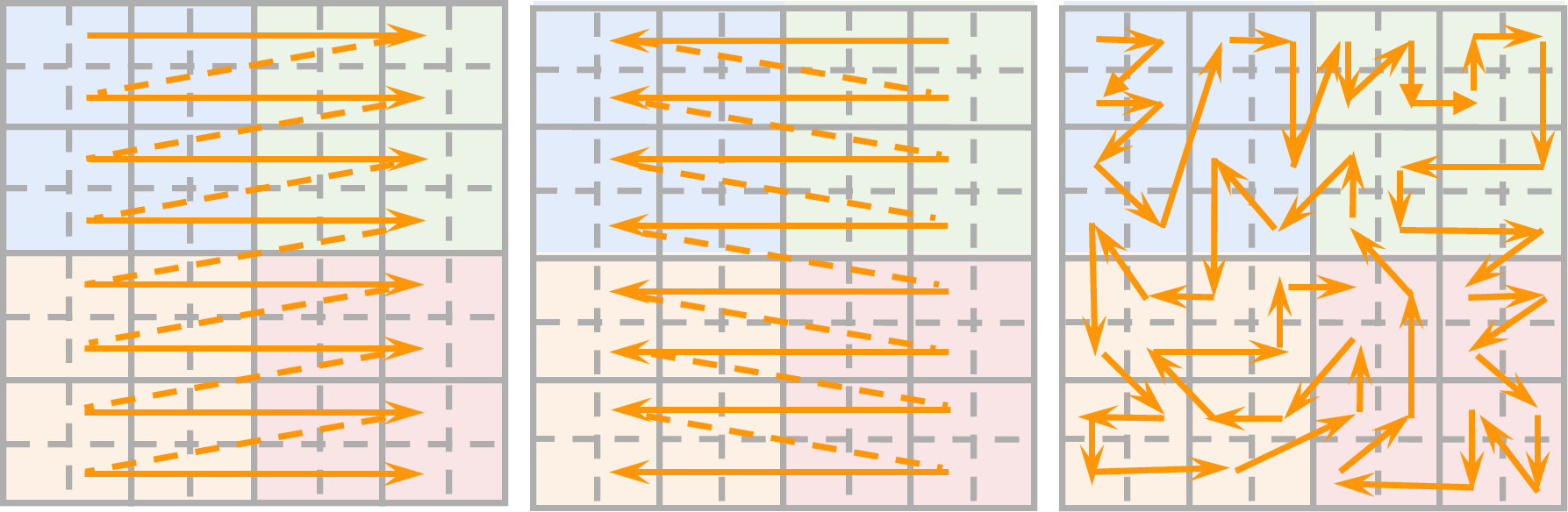
- Localmamba: Visual state space model with windowed selective scan. arXiv preprint arXiv:2403.09338, 2024.
- Plainmamba: Improving non-hierarchical mamba in visual recognition. arXiv preprint arXiv:2403.17695, 2024.
- Efficientvmamba: Atrous selective scan for light weight visual mamba. arXiv preprint arXiv:2403.09977, 2024.
- Mambamixer: Efficient selective state space models with dual token and channel selection. arXiv preprint arXiv:2403.19888, 2024.
- Mamba-nd: Selective state space modeling for multi-dimensional data. arXiv preprint arXiv:2402.05892, 2024.
- Simba: Simplified mamba-based architecture for vision and multivariate time series. arXiv preprint arXiv:2403.15360, 2024.
- Zigma: Zigzag mamba diffusion model. arXiv preprint arXiv:2403.13802, 2024.
- Vmambair: Visual state space model for image restoration. arXiv preprint arXiv:2403.11423, 2024.
- Videomamba: State space model for efficient video understanding. arXiv preprint arXiv:2403.06977, 2024.
- Motion mamba: Efficient and long sequence motion generation with hierarchical and bidirectional selective ssm. arXiv preprint arXiv:2403.07487, 2024.
- Vivim: a video vision mamba for medical video object segmentation. arXiv preprint arXiv:2401.14168, 2024.
- Rsmamba: Remote sensing image classification with state space model. arXiv preprint arXiv:2403.19654, 2024.
- Harmamba: Efficient wearable sensor human activity recognition based on bidirectional selective ssm. arXiv preprint arXiv:2403.20183, 2024.
- Activating wider areas in image super-resolution. arXiv preprint arXiv:2403.08330, 2024.
- Vl-mamba: Exploring state space models for multimodal learning. arXiv preprint arXiv:2403.13600, 2024.
- Video mamba suite: State space model as a versatile alternative for video understanding. arXiv preprint arXiv:2403.09626, 2024.
- Point mamba: A novel point cloud backbone based on state space model with octree-based ordering strategy. arXiv preprint arXiv:2403.06467, 2024.
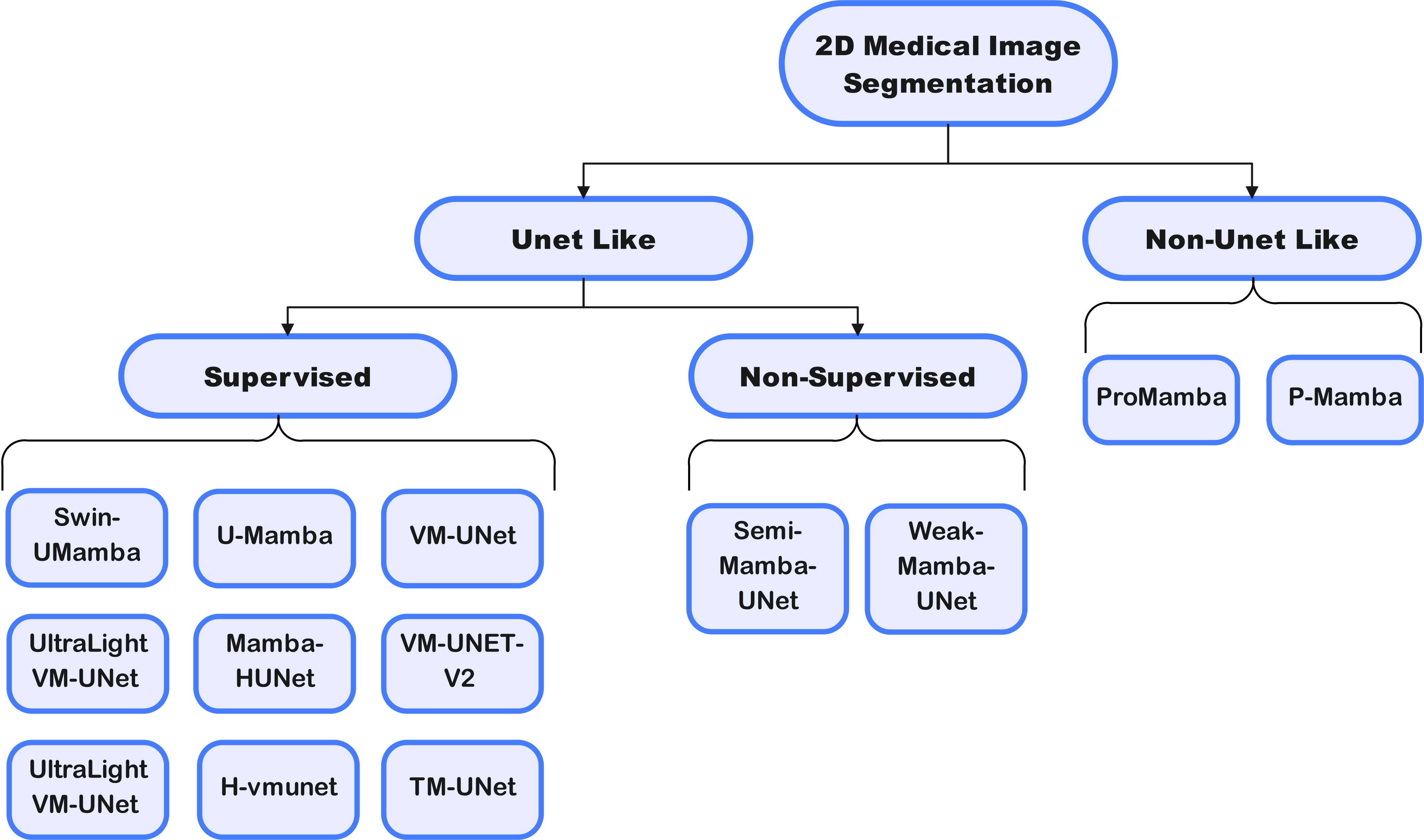
- Large window-based mamba unet for medical image segmentation: Beyond convolution and self-attention. arXiv preprint arXiv:2403.07332, 2024.
- Motion-guided dual-camera tracker for low-cost skill evaluation of gastric endoscopy. arXiv preprint arXiv:2403.05146, 2024.
- Vmrnn: Integrating vision mamba and lstm for efficient and accurate spatiotemporal forecasting. arXiv preprint arXiv:2403.16536, 2024.
- Res-vmamba: Fine-grained food category visual classification using selective state space models with deep residual learning. arXiv preprint arXiv:2402.15761, 2024.
- Sigma: Siamese mamba network for multi-modal semantic segmentation. arXiv preprint arXiv:2404.04256, 2024.
- Remamber: Referring image segmentation with mamba twister. arXiv preprint arXiv:2403.17839, 2024.
- Mamba-unet: Unet-like pure visual mamba for medical image segmentation. arXiv preprint arXiv:2402.05079, 2024.
- Semi-mamba-unet: Pixel-level contrastive and pixel-level cross-supervised visual mamba-based unet for semi-supervised medical image segmentation. arXiv e-prints, pages arXiv–2402, 2024.
- Vmambamorph: a visual mamba-based framework with cross-scan module for deformable 3d image registration. arXiv preprint arXiv:2404.05105, 2024.
- Changemamba: Remote sensing change detection with spatio-temporal state space model. arXiv preprint arXiv:2404.03425, 2024.
- H-vmunet: High-order vision mamba unet for medical image segmentation. arXiv preprint arXiv:2403.13642, 2024.
- Mambamir: An arbitrary-masked mamba for joint medical image reconstruction and uncertainty estimation. arXiv preprint arXiv:2402.18451, 2024.
- Mambair: A simple baseline for image restoration with state-space model. arXiv preprint arXiv:2402.15648, 2024.
- Serpent: Scalable and efficient image restoration via multi-scale structured state space models. arXiv e-prints, pages arXiv–2403, 2024.
- Integrating mamba sequence model and hierarchical upsampling network for accurate semantic segmentation of multiple sclerosis legion. arXiv e-prints, pages arXiv–2403, 2024.
- Rotate to scan: Unet-like mamba with triplet ssm module for medical image segmentation. arXiv preprint arXiv:2403.17701, 2024.
- Swin-umamba: Mamba-based unet with imagenet-based pretraining. arXiv preprint arXiv:2402.03302, 2024.
- Ultralight vm-unet: Parallel vision mamba significantly reduces parameters for skin lesion segmentation. arXiv preprint arXiv:2403.20035, 2024.
- Vm-unet: Vision mamba unet for medical image segmentation. arXiv preprint arXiv:2402.02491, 2024.
- Vm-unet-v2 rethinking vision mamba unet for medical image segmentation. arXiv preprint arXiv:2403.09157, 2024.
- Medmamba: Vision mamba for medical image classification. arXiv preprint arXiv:2403.03849, 2024.
- Mim-istd: Mamba-in-mamba for efficient infrared small target detection. arXiv preprint arXiv:2403.02148, 2024.
- Rs3mamba: Visual state space model for remote sensing images semantic segmentation. arXiv preprint arXiv:2404.02457, 2024.
- Freqmamba: Viewing mamba from a frequency perspective for image deraining. arXiv preprint arXiv:2404.09476, 2024.
- Rs-mamba for large remote sensing image dense prediction. arXiv preprint arXiv:2404.02668, 2024.
- Convolutional lstm network: A machine learning approach for precipitation nowcasting. Advances in neural information processing systems, 28, 2015.
- State space models for event cameras. arXiv preprint arXiv:2402.15584, 2024.
- Long movie clip classification with state-space video models. In European Conference on Computer Vision, pages 87–104. Springer, 2022.
- Spikemba: Multi-modal spiking saliency mamba for temporal video grounding. arXiv preprint arXiv:2404.01174, 2024.
- Cobra: Extending mamba to multi-modal large language model for efficient inference. arXiv preprint arXiv:2403.14520, 2024.
- U-shaped vision mamba for single image dehazing. arXiv preprint arXiv:2402.04139, 2024.
- Hu Gao and Depeng Dang. Aggregating local and global features via selective state spaces model for efficient image deblurring. arXiv preprint arXiv:2403.20106, 2024.
- Mambatalk: Efficient holistic gesture synthesis with selective state space models. arXiv preprint arXiv:2403.09471, 2024.
- Scalable diffusion models with state space backbone. arXiv preprint arXiv:2402.05608, 2024.
- 3dmambacomplete: Exploring structured state space model for point cloud completion. arXiv preprint arXiv:2404.07106, 2024.
- 3dmambaipf: A state space model for iterative point cloud filtering via differentiable rendering. arXiv preprint arXiv:2404.05522, 2024.
- Point could mamba: Point cloud learning via state space model. arXiv preprint arXiv:2403.00762, 2024.
- Pointmamba: A simple state space model for point cloud analysis. arXiv preprint arXiv:2402.10739, 2024.
- Gamba: Marry gaussian splatting with mamba for single view 3d reconstruction. arXiv preprint arXiv:2403.18795, 2024.
- Ssm meets video diffusion models: Efficient video generation with structured state spaces. arXiv preprint arXiv:2403.07711, 2024.
- U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint arXiv:2401.04722, 2024.
- Digital radiography. Springer, 2019.
- Overview of guidance for endoscopy during the coronavirus disease 2019 pandemic. Journal of gastroenterology and hepatology, 35(5):749–759, 2020.
- X-ray computed tomography. Nature Reviews Methods Primers, 1(1):18, 2021.
- Super-resolution ultrasound imaging. Ultrasound in medicine & biology, 46(4):865–891, 2020.
- Brain tumor segmentation and classification from magnetic resonance images: Review of selected methods from 2014 to 2019. Pattern recognition letters, 131:244–260, 2020.
- Zi Ye and Tianxiang Chen. P-mamba: Marrying perona malik diffusion with mamba for efficient pediatric echocardiographic left ventricular segmentation. arXiv preprint arXiv:2402.08506, 2024.
- Promamba: Prompt-mamba for polyp segmentation. arXiv preprint arXiv:2403.13660, 2024.
- Weak-mamba-unet: Visual mamba makes cnn and vit work better for scribble-based medical image segmentation. arXiv preprint arXiv:2402.10887, 2024.
- Md-dose: A diffusion model based on the mamba for radiotherapy dose prediction. arXiv preprint arXiv:2403.08479, 2024.
- Mambamil: Enhancing long sequence modeling with sequence reordering in computational pathology. arXiv preprint arXiv:2403.06800, 2024.
- Fd-vision mamba for endoscopic exposure correction. arXiv preprint arXiv:2402.06378, 2024.
- Lightm-unet: Mamba assists in lightweight unet for medical image segmentation. arXiv preprint arXiv:2403.05246, 2024.
- Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation. arXiv preprint arXiv:2401.13560, 2024.
- T-mamba: Frequency-enhanced gated long-range dependency for tooth 3d cbct segmentation. arXiv preprint arXiv:2404.01065, 2024.
- Cmvim: Contrastive masked vim autoencoder for 3d multi-modal representation learning for ad classification. arXiv preprint arXiv:2403.16520, 2024.
- nnmamba: 3d biomedical image segmentation, classification and landmark detection with state space model. arXiv preprint arXiv:2402.03526, 2024.
- Mambamorph: a mamba-based backbone with contrastive feature learning for deformable mr-ct registration. arXiv preprint arXiv:2401.13934, 2024.
- Pan-mamba: Effective pan-sharpening with state space model. arXiv preprint arXiv:2402.12192, 2024.
- Hsimamba: Hyperpsectral imaging efficient feature learning with bidirectional state space for classification. arXiv preprint arXiv:2404.00272, 2024.
- Samba: Semantic segmentation of remotely sensed images with state space model. arXiv preprint arXiv:2404.01705, 2024.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.