- The paper proposes a hardware-algorithm co-design featuring 8-bit Hadamard quantization and PoT quantization for efficient SSM processing.
- It demonstrates up to 68.80× speedup over CPU and 8.90× over GPU, ensuring reduced latency for edge deployments.
- The accelerator employs first-order linear approximations for nonlinear functions, reducing DSP core usage while maintaining accuracy.
FastMamba: A High-Speed and Efficient Mamba Accelerator on FPGA with Accurate Quantization
Introduction
The paper presents FastMamba, an FPGA-based accelerator designed for efficient deployment of Mamba2 models. State Space Models (SSMs) like Mamba2 exhibit significant computational efficiency over traditional Transformer architectures, particularly in processing longer sequences. The motivation for an FPGA-based solution lies in enabling edge deployment with reduced latency and increased privacy compared to GPU-dependent implementations. FastMamba addresses the challenges of deploying Mamba2 on FPGAs by emphasizing hardware-algorithm co-design, focusing on quantization and linear approximation strategies to reduce computational load without significant accuracy loss.
Hardware-Algorithm Co-Design
Accurate Quantization
FastMamba introduces an 8-bit quantization method for linear layers using the Hadamard Transformation, which alleviates the impact of outliers in activation values and weights.
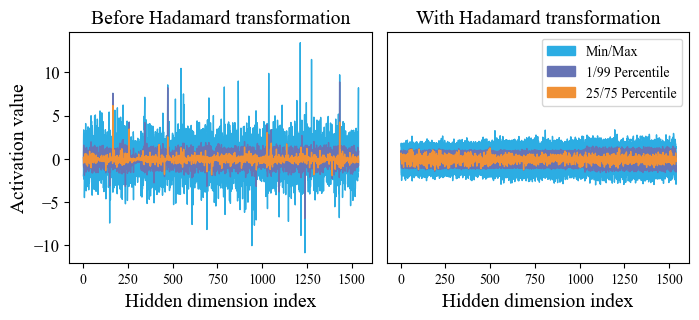
Figure 1: The distributions of activation values before Hadamard transforming and with Hadamard transforming.
For convolutional layers and the SSM block, FastMamba employs a Power-of-Two (PoT) quantization framework. This strategy offers a balance between computational efficiency and precision, achieving reductions in hardware complexity while keeping accuracy degradation minimal.
Nonlinear Function Approximation
To optimize hardware performance, FastMamba implements a first-order linear approximation for nonlinear functions within the SSM block. By unifying functions like SoftPlus and exponential operations into hardware-friendly formats, the architecture reduces the demand for costly resources such as DSP cores. This approximation permits quantization by PoT, further enhancing the computational efficiency.
Hardware Architecture
System Overview
FastMamba's architecture is composed of fixed-point computing units for the major computational tasks in Mamba2, such as linear and SSM computations, and floating-point units for less-demanding operations like RMS normalization and SiLU activations.
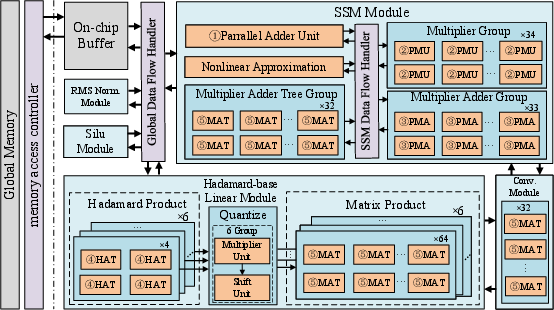
Figure 2: Overall Architecture of FastMamba.
Vector Processing Units (VPUs)
A pivotal component of FastMamba's design is the incorporation of parallel Vector Processing Units, which include adders and multipliers. These modules enable efficient execution of key computational tasks and are characterized by their scalability and modularity, as detailed in Table 1 of the original document.
Figure 3: The structure of the multipliers and adders in the VPUs.
Specialised Modules
FastMamba's Hadamard-based Linear Module and SSM Module are engineered to leverage the characteristics of the VPUs and offer specialized processing paths for the FastMamba tasks. These utilize parallelism extensively, ensuring that computation is both rapid and resource-efficient.
Experimental Results
The evaluation of FastMamba showcases substantial gains in both speed and energy efficiency compared to traditional CPU and GPU implementations. The benchmark tests conducted on Mamba2-130M revealed impressive speedup figures, with up to a 68.80× improvement over a CPU and an 8.90× enhancement over a GPU during the prompt prefill stage.
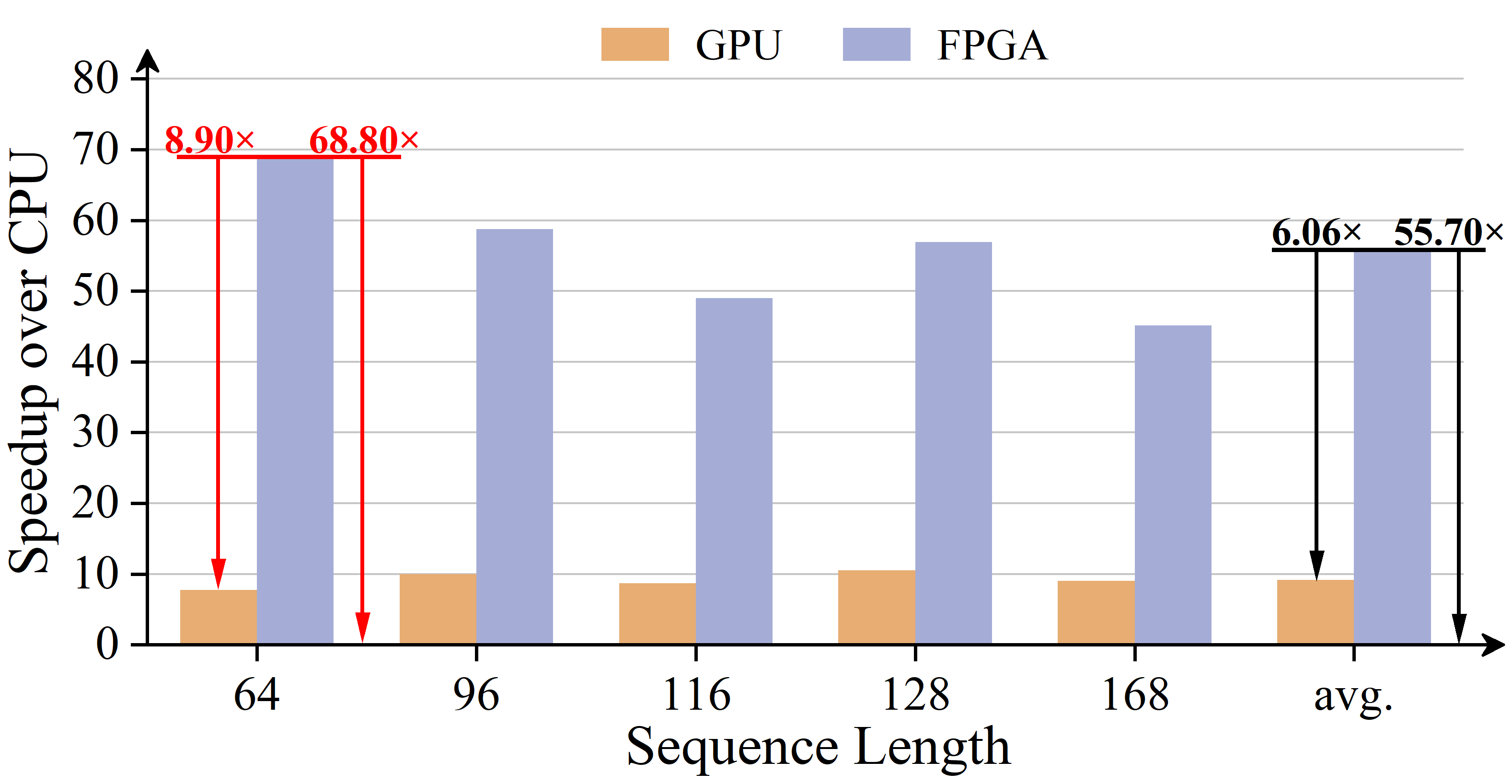
Figure 4: Comparison of speedup improvement to CPU and GPU on Mamba2-130M with different input sequence length during prompt prefill stage.
Conclusion
FastMamba represents an innovative advancement in the deployment of Mamba2 models on FPGA platforms. Through its co-design approach, integrating precise quantization methods and efficient approximation algorithms, FastMamba achieves remarkable computational efficiency and speed. This enables real-time processing capabilities on edge devices, facilitating enhanced privacy and reduced latency. The results underscore FastMamba's potential as a robust solution for high-speed, low-power AI computing, paving the way for future FPGA-based accelerators in diverse applications.

