- The paper presents a novel architecture using MCP to route vision experts for task-specific, wireless-aware multimodal inference.
- It pioneers a dual-stream DRL framework with CE-SAC and ASEM to optimize both semantic compatibility and network quality.
- Performance evaluations demonstrate up to 51% accuracy improvements over state-of-the-art MLLMs, validating its adaptive design.
M3LLM: Model Context Protocol-aided Mixture of Vision Experts For Multimodal LLMs in Networks
The paper presents M3LLM, a novel distributed architecture designed for multimodal LLMs (MLLMs), incorporating a mixture of vision experts coordinated through wireless networks. The method leverages the Model Context Protocol (MCP) for efficient expert routing and employs advanced reinforcement learning techniques to optimize for both task relevance and network conditions.
Design and Architecture
System Model
M3LLM integrates various vision experts distributed across edge devices within wireless networks, enabling dynamic and task-specific multimodal inference. The architecture decouples vision experts from a centralized model, allowing distributed, network-aware optimization. The MCP structures contextual information into a unified, wireless-aware representation to facilitate communication among components.
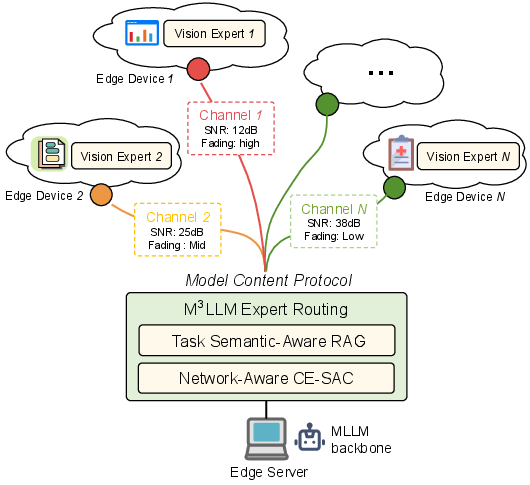
Figure 1: The system model of M3LLM in wireless networks.
Expert Routing
The routing mechanism in M3LLM follows a two-stage hierarchical approach:
- Coarse-Grained Expert Selection: The initial stage involves a semantic-based filtering mechanism, assisted by Retrieval-Augmented Generation (RAG), to shortlist vision experts that are semantically relevant to the current task.
- Fine-Grained Routing Optimization: The second stage involves a dual-objective DRL framework using Channel-Expert Soft Actor-Critic (CE-SAC) to select the optimal set of vision experts by considering both task-expert semantic compatibility and wireless network quality.
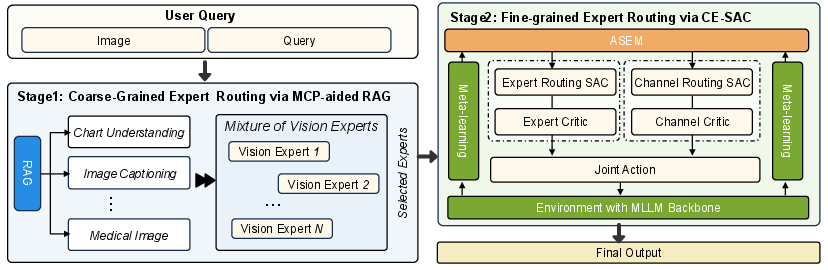
Figure 2: Expert routing scheme of M3LLM. Stage 1 performs coarse-grained expert filtering via MCP-aided RAG. Stage 2 executes network-aware fine-grained expert routing using a decoupled DRL agent, i.e., CE-SAC, which leverages a stability-aware state representation from ASEM.
Methodology
Context Protocol and Semantic Filtering
MCP enables structured communication and contextual encoding, capturing task semantics, device capabilities, and channel states. By leveraging these rich context encodings, M3LLM dynamically selects vision experts tailored to the current query's requirements.
Dual-Stream DRL Optimization
The CE-SAC algorithm utilizes two separate critic networks for task and communication objectives, preventing interference and ensuring stable learning. The Adaptive Stability Enhancement Module (ASEM) provides robust latent representations to mitigate the adverse effects of wireless channel dynamics.
Experimental Evaluation
The experimental results demonstrate that M3LLM substantially enhances multimodal task accuracy by up to 51% compared with state-of-the-art MLLMs like MoVA. These improvements are attributed to M3LLM's capability to adapt expert routing strategies based on real-time wireless network conditions and task demands.
Figure 3: Training dynamics comparison across 1,000 episodes. (a) Total reward evolution showing M3LLM's superior convergence and final performance. (b) LLM reward demonstrating consistent semantic quality improvements. (c) Channel reward highlighting M3LLM's unique ability to optimize network quality while baselines remain static. Shaded areas represent confidence intervals.
The integration of MCP and CE-SAC allows M3LLM to achieve a balanced optimization between semantic task performance and channel robustness. The architecture's use of ASEM contributes significantly to managing channel volatility and ensuring expert selection is not only semantically effective but also network-aware.
Conclusion
M3LLM presents a significant advancement in the deployment of MLLMs in distributed wireless environments. By integrating MCP with innovative DRL approaches, M3LLM effectively coordinates vision experts, maximizing task performance while adapting to dynamic network conditions. Future work could explore extending this architecture to incorporate federated learning and more adaptive compression strategies for even greater performance.