- The paper presents a novel benchmark creation process by translating English datasets into Bengali using the gpt-4o-mini model and rigorous post-processing.
- It evaluates 10 state-of-the-art LLMs on eight tasks, revealing significant performance gaps and tokenization inefficiencies in Bengali compared to English.
- Findings underscore the need for tailored multilingual evaluation metrics and optimized tokenization strategies for underrepresented languages.
Introduction
The research paper under discussion assesses the multilingual abilities of LLMs with a specific focus on Bengali, a language that poses unique challenges due to its complex linguistic structure and the scarcity of computational resources. The study meticulously highlights the absence of standardized evaluation benchmarks for Bengali NLP tasks, which impedes the development of robust LLMs for this language. Through its comprehensive evaluation, the paper aims to bridge these gaps by providing high-quality benchmark datasets, assessing tokenization behavior, and analyzing model performance.
Methodology
The authors adopted a methodical approach to translate existing English NLP benchmark datasets into Bengali using a specialized translation pipeline. This process involved dataset selection, translation using the gpt-4o-mini model, and an extensive post-processing phase to ensure quality and consistency.
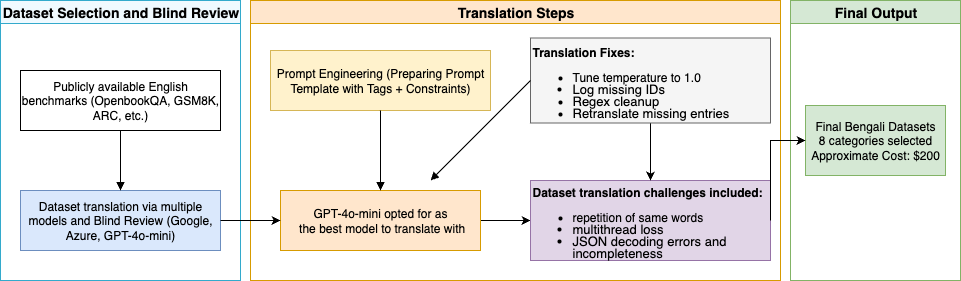
Figure 1: Methodology Overview.
Dataset Selection and Translation
The dataset selection adhered to a rigorous process that ensured the inclusion of representative text corpora aligned with the research objectives. This careful selection allowed for a comprehensive assessment of model capabilities across multiple tasks. The datasets chosen encapsulate tasks related to logical reasoning, commonsense understanding, and more, providing a broad spectrum for analysis.
Translation Pipeline
Utilizing the gpt-4o-mini model, the paper achieved accurate translations of English datasets into Bengali, overcoming challenges such as repetitive translations and decoding errors. The translation process, depicted in Figure 1, was further refined via human-assisted reviews to enhance cultural and contextual appropriateness.
Experimental Setup
The research evaluated 10 state-of-the-art open-source LLMs on eight distinct English-to-Bengali translated datasets. These included models from various architecture families such as LLaMA, Qwen, Mistral, and DeepSeek.
Evaluation Metrics
Several key metrics were employed to assess model performance:
- Accuracy: Indicative of the proportion of correctly answered questions.
- Response Error Rate (RER) and Response Adherence Rate (RAR): These metrics measure the conformity of model responses to valid answer formats.
- LLM-Judge: A novel metric utilizing an LLM-based judge to evaluate the semantic similarity of model answers to ground truth.
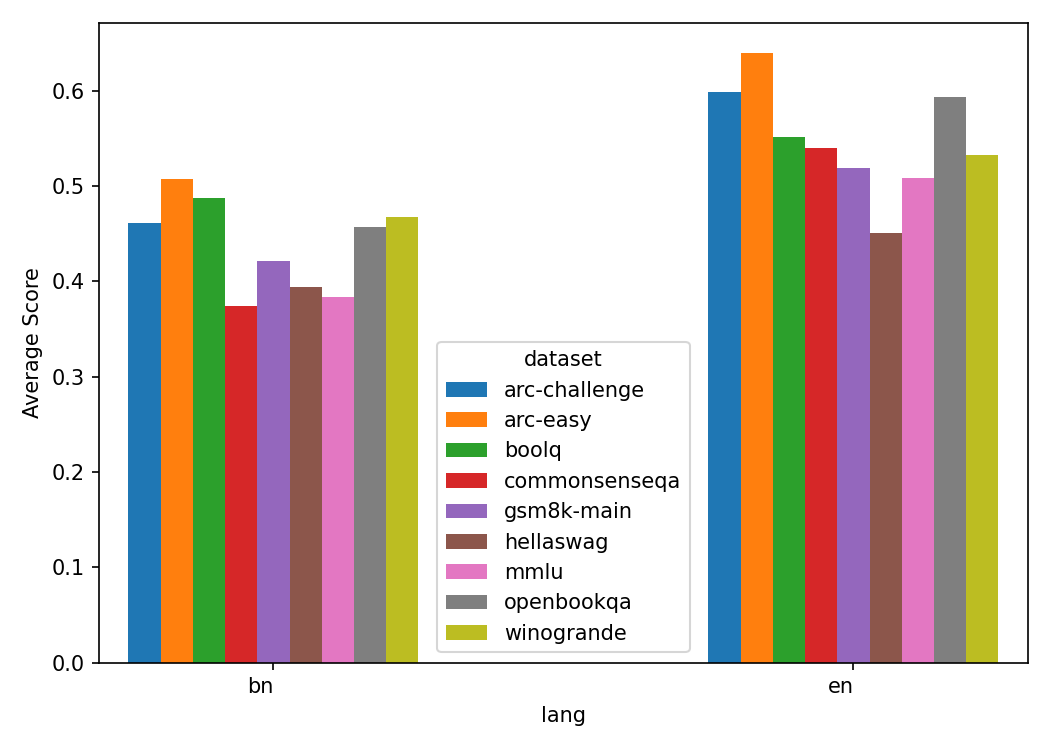
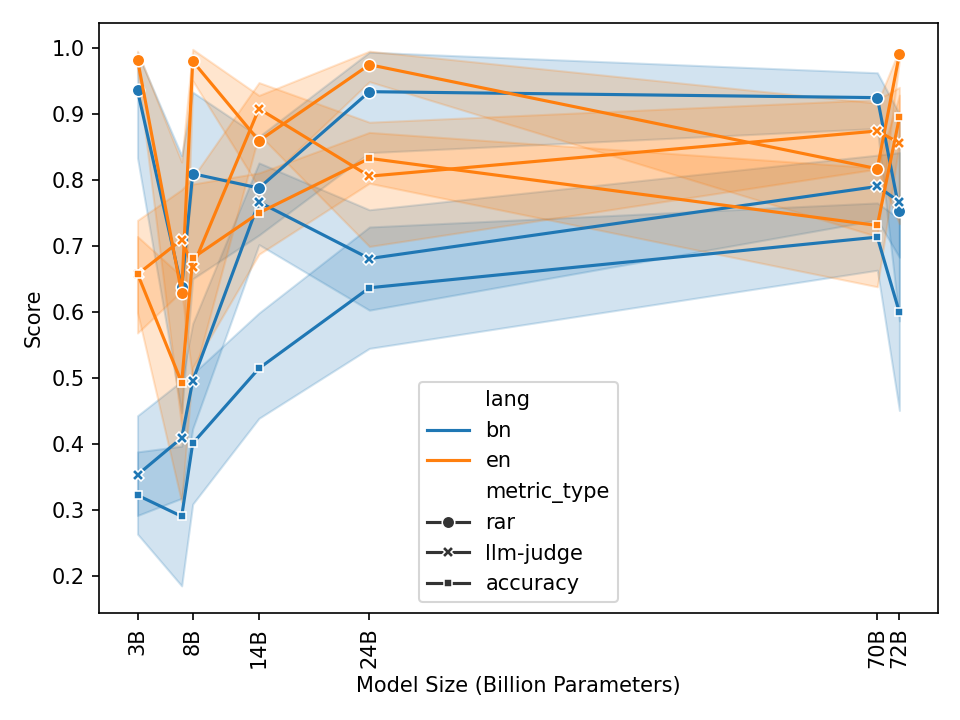
Figure 2: Average of Accuracy, LLM-Judge, and RAR scores across datasets grouped by language.
Result Analysis
The analysis revealed consistent performance discrepancies between Bengali and English datasets, with models often underperforming in the former. Notably, smaller models and certain families like Mistral exhibited significant gaps, whereas models like DeepSeek demonstrated stability across languages.
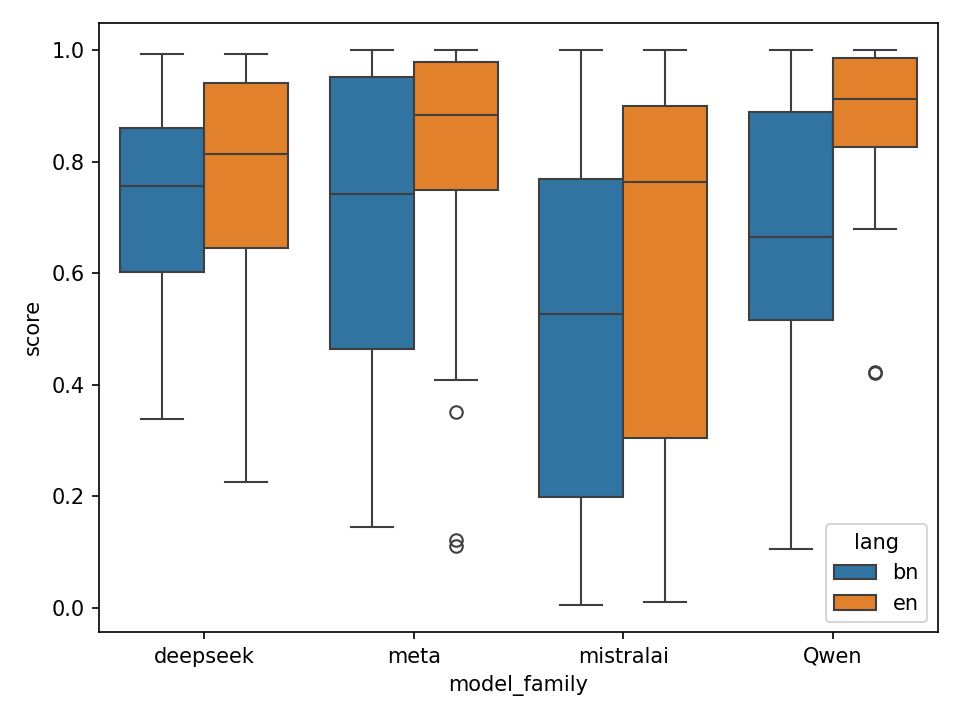
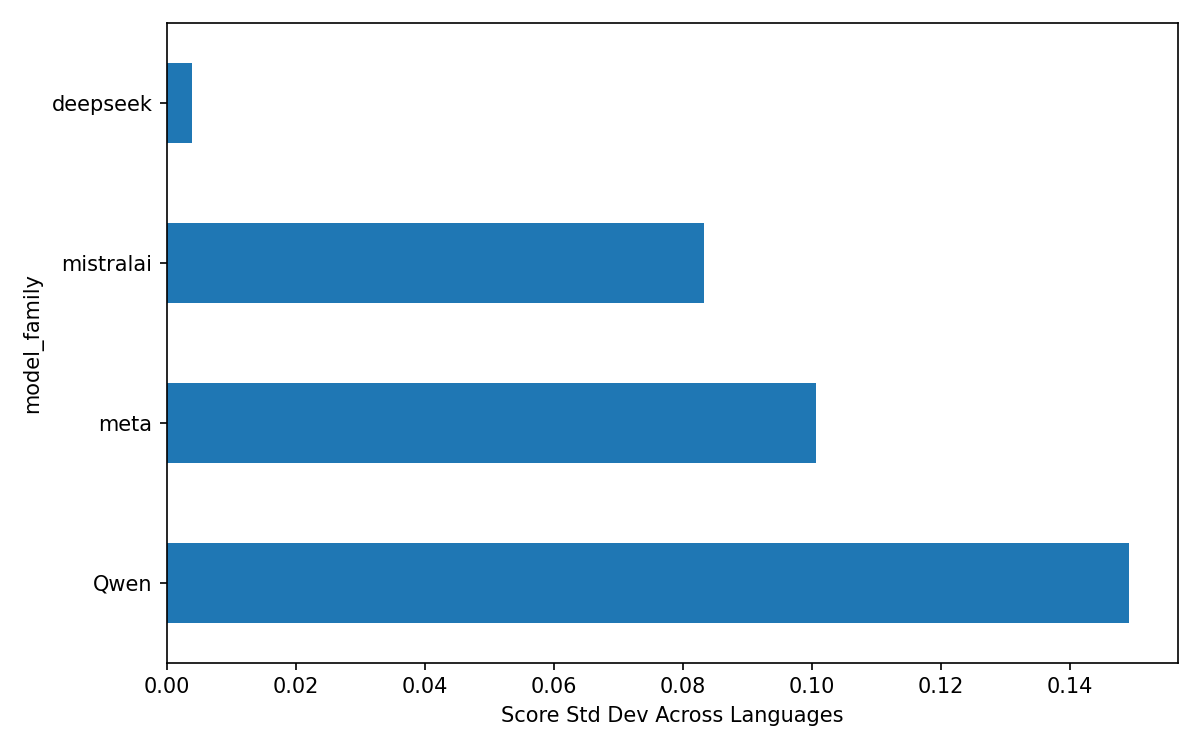
Figure 3: LLM-Judge score distributions across different model architecture families.
Tokenization Analysis
The study scrutinized the tokenization efficiency of the models, revealing that Bengali text incurs higher token counts per instance and word compared to English. This inefficiency negatively impacts model performance, drawing attention to the need for optimized tokenization strategies.
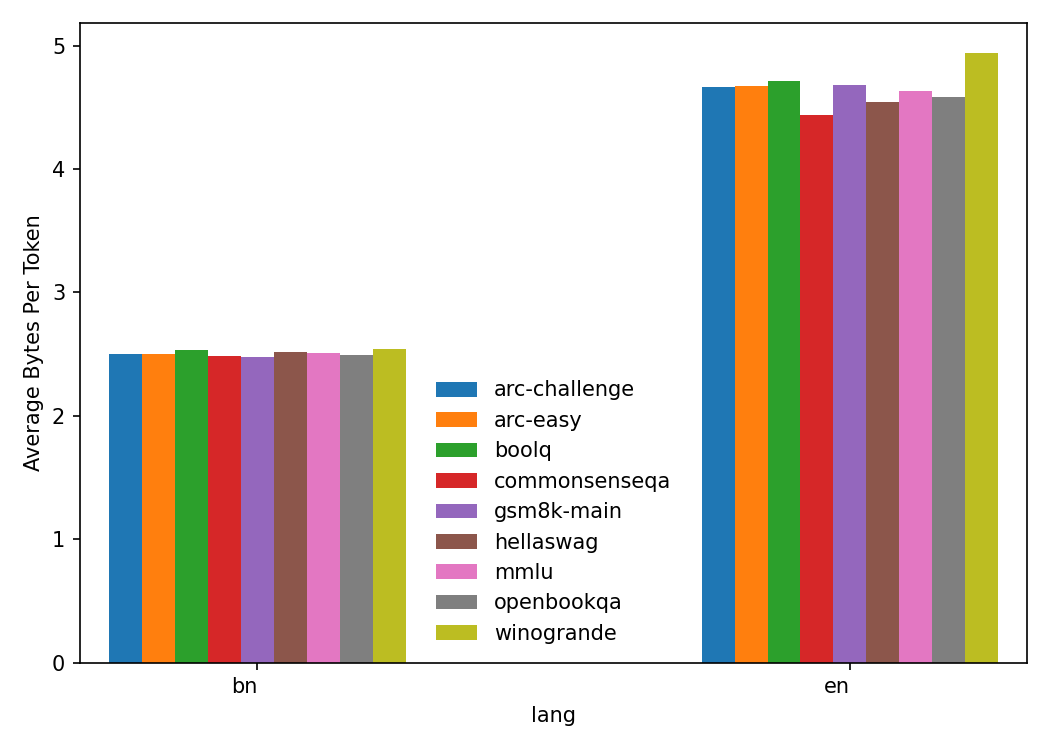
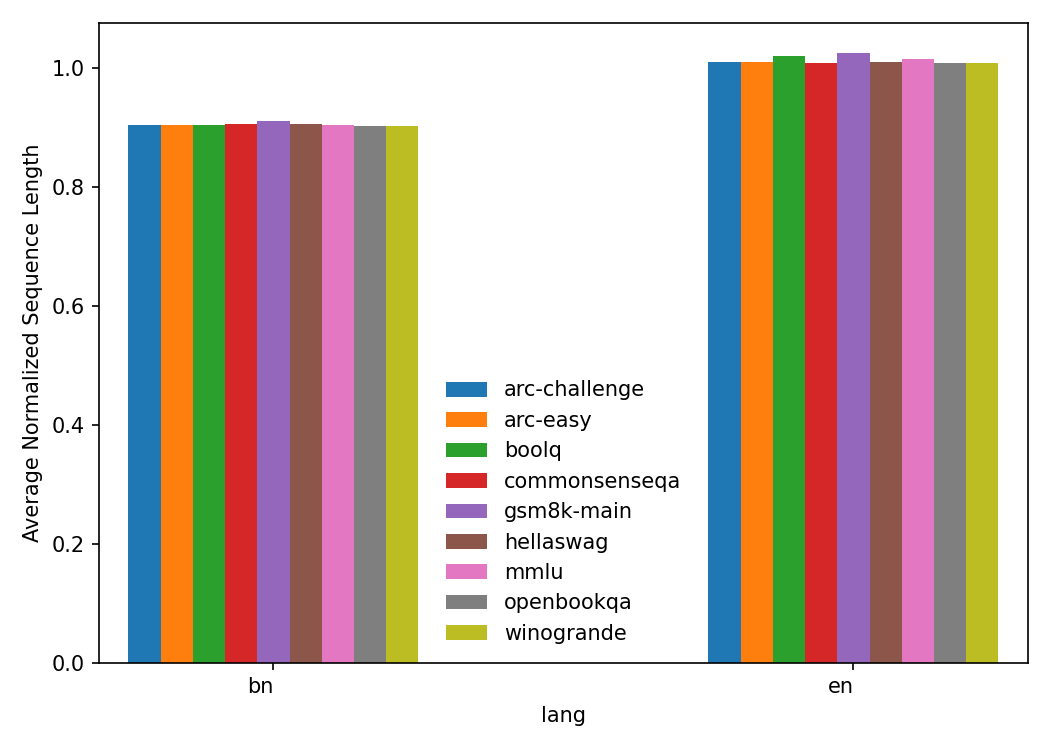
Figure 4: ABPT.
Conclusion
The research presents critical insights into the multilingual capabilities of LLMs, particularly for underrepresented languages like Bengali. The authors have successfully developed benchmark datasets and methodologies that pave the way for future research in this domain. The paper underscores the necessity of improved dataset quality and appraisal techniques tailored to multilingual contexts, with the aim of democratizing NLP technologies.
Future Directions
To build on this foundation, future research should prioritize the development of linguistically nuanced datasets and explore more flexible evaluation criteria. Additionally, advancing tokenization techniques specific to complex scripts like Bengali could enhance model efficiency and accuracy.
In summary, this paper provides a robust framework for evaluating multilingual LLMs and highlights the pathways for advancing NLP research in underrepresented languages. The comprehensive benchmarks and methodologies introduced serve as crucial stepping stones towards more inclusive and effective language technologies.