- The paper evaluates state-of-the-art LLMs on Filipino using a benchmark covering cultural, classical NLP, reading comprehension, and generation tasks.
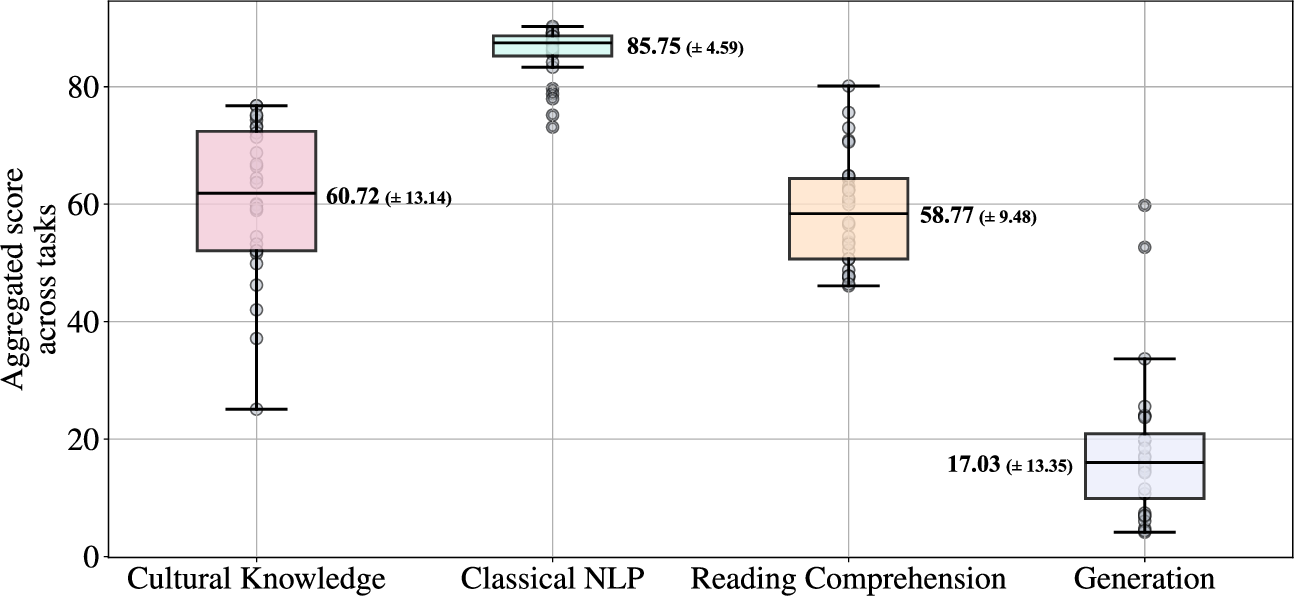
- It reveals strong performance in classical NLP tasks but significant failures in generation and translation, with GPT-4o leading at 72.23% accuracy.
- Language-specific finetuning and few-shot prompting are shown to enhance model performance for low-resource Filipino language tasks.
"FilBench: Can LLMs Understand and Generate Filipino?" Review
Introduction
"FilBench" explores the capabilities of LLMs in understanding and generating content in Filipino, a language with unique linguistic characteristics and substantial speaker population. The paper introduces FilBench, a benchmark specifically designed to assess the proficiency of LLMs in Filipino, Tagalog, and Cebuano.

Figure 1: Overview of FilBench illustrating four categories and twelve subtasks across major Philippine languages.
Despite considerable development in LLM technologies, their effectiveness for languages like Filipino remains under-addressed. The benchmark reflects Philippine NLP's research priorities encompassing Cultural Knowledge, Classical NLP, Reading Comprehension, and Generation. Through a detailed evaluation of 27 state-of-the-art models, it highlights existing models' limitations, notably in reading comprehension and translation, and advocates for tailored model training.
FilBench Composition
FilBench includes diverse tasks aimed at thoroughly assessing LLM performance in Philippine languages. These tasks are derived from curated datasets reflecting the aforementioned categories:
This structure ensures comprehensive language evaluation, particularly focusing on low-resource scenarios prevalent with these languages. FilBench's scoring system employs a weighted average across categories, enabling clear performance comparison.
Evaluation Results
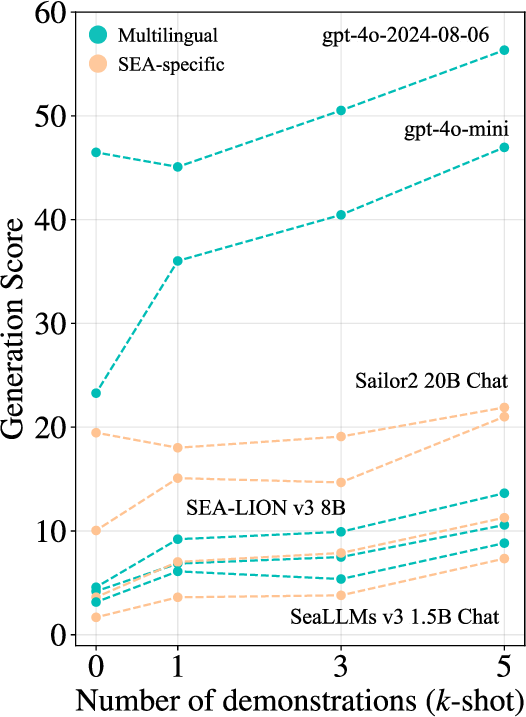
FilBench's results reveal significant performance disparities among evaluated models. GPT-4o emerges as the leading model with approximately 72.23% in overall accuracy, but critical failures are noted in generation tasks with scores significantly below expectation (average GN: 17.03%). SEA-specific models demonstrate parameter efficiency, where models like SEA-LION v3 showcase competitive scoring (61.07%) despite lower scores relative to Filipino challenges.
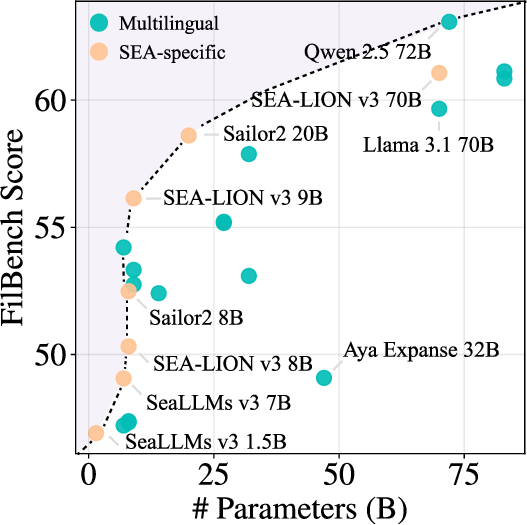
Figure 3: Parameter-efficiency of LLMs indicating SEA-specific models' relative efficacy.
Notably, language-specific finetuning enhances proficiency remarkably. Models trained on Southeast Asian languages outperform general-purpose LLMs, implying substantial benefits from focused training datasets. Additionally, few-shot prompting mitigates Generation task failures, highlighting potential methods for improving translation performance.
Analysis of Model Behavior
The paper analyzes cases where LLMs perform well or fail on Filipino-centric tasks:
Implications and Future Developments
The insights from FilBench highlight pressing needs for targeted model development that enhance Filipino language processing. There's potential for building Filipino-specific LLMs given the effective parameter-utilization shown by SEA-specific models. FilBench underscores critical areas for computational focus, such as data augmentation in generation tasks, and emphasizes community-driven benchmarks like Batayan.
(Likely future work includes augmentation of task datasets, expansion into more Philippine languages, and leveraging cross-lingual transfer for improved model adaptability.)
Conclusion
FilBench offers a critical appraisal of LLM capabilities regarding Filipino languages, illustrating performance limits in generation tasks while providing a framework for language-focused LLM improvements. Such benchmarks are instrumental in directing AI advancements towards inclusivity and effective linguistic representation. Future developments should consider enriching the language-model space further, ensuring the advancement of AI that respects and caters to linguistic diversity.