- The paper introduces TigerCoder, a suite of LLMs that leverages curated Bangla code datasets to achieve substantial performance gains in code generation tasks.
- It presents MBPP-Bangla benchmark, translating 974 programming problems into Bangla with expert validation across five languages.
- Experiments show TigerCoder models attain 4–18% improvements in Pass@1 scores, highlighting the value of fine-tuning on language-specific data.
TigerCoder: Dedicated LLMs for Bangla Code Generation
Introduction
The paper presents TigerCoder, a suite of LLMs specifically optimized for code generation in Bangla, a language with over 240 million native speakers but minimal representation in current LLMs. The work addresses the acute lack of high-quality Bangla code datasets and benchmarks, which has resulted in subpar performance of both proprietary and open-source models on Bangla code generation tasks. The authors introduce three major contributions: (1) a set of curated Bangla code instruction datasets, (2) MBPP-Bangla, a comprehensive benchmark for Bangla code generation across five programming languages, and (3) the TigerCoder model family, which demonstrates substantial performance improvements over existing models.
Benchmarking Bangla Code Generation
The MBPP-Bangla benchmark is constructed by translating 974 programming problems from the MBPP dataset into Bangla, with expert validation for linguistic and technical fidelity. Each problem is paired with reference solutions in Python, Java, JavaScript, Ruby, and C++, enabling multi-language evaluation. The benchmark is designed to stress both natural language comprehension and code synthesis capabilities of LLMs in Bangla.
Evaluation of Existing Models
The authors systematically evaluate a range of proprietary, multilingual, and Bangla-specific LLMs on MBPP-Bangla and mHumanEval-Bangla. The results reveal a consistent and substantial performance gap: models perform markedly better when prompted in English compared to Bangla. Proprietary models (e.g., GPT-3.5, Gemini-2.5) achieve Pass@1 scores of 60–81% in English but drop to 51–62% in Bangla. Open-source multilingual models exhibit even larger declines, with most Bangla-specific models failing to surpass 15% Pass@1 in Bangla. The only exception is TigerLLM, which maintains competitive performance in Bangla due to targeted fine-tuning.
Machine Translation Does Not Bridge the Gap
To test whether machine-translating Bangla prompts to English improves code generation, the authors use NLLB for translation and re-evaluate all models. The results show that machine translation does not yield significant improvements; in many cases, performance is similar or slightly worse than direct Bangla inference. Analysis reveals that translation often produces incorrect or misleading keywords, which degrade model performance.
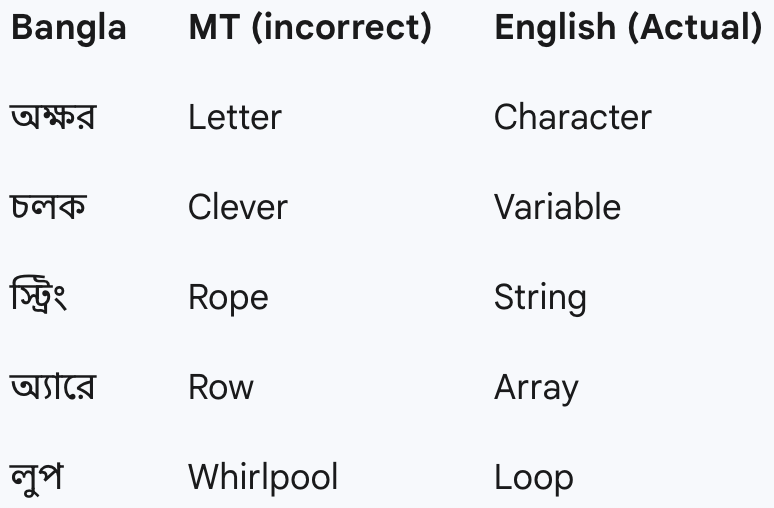
Figure 1: Incorrect keywords generated by machine translation, illustrating semantic drift and loss of code-specific intent.
Construction of Bangla-Code-Instruct Datasets
To address the data scarcity, the authors curate three instruction-tuning datasets:
- Bangla-Code-Instruct-SI: 100,000 self-instructed pairs, seeded by 5,000 expert-authored Bangla prompts and expanded using GPT-4o, with rigorous code validation.
- Bangla-Code-Instruct-Syn: 100,000 synthetic pairs generated by GPT-4o and Claude 3.5, filtered for diversity using BERTScore.
- Bangla-Code-Instruct-TE: 100,000 pairs by translating English instructions from Evol-Instruct using NLLB, with quality filtering via CometKiwi-22 QE and BERTScore.
These datasets provide diverse, high-quality training signals, capturing both natural and synthetic instructional styles.
TigerCoder Model Family and Fine-Tuning
TigerCoder models are built by fine-tuning TigerLLM (1B and 9B parameter variants) on combinations of the curated datasets. The fine-tuning process is conducted on a single NVIDIA A100 (40GB), with empirically selected hyperparameters. Ablation studies show that combining SI and TE datasets yields the highest performance, with further gains from including all three datasets.
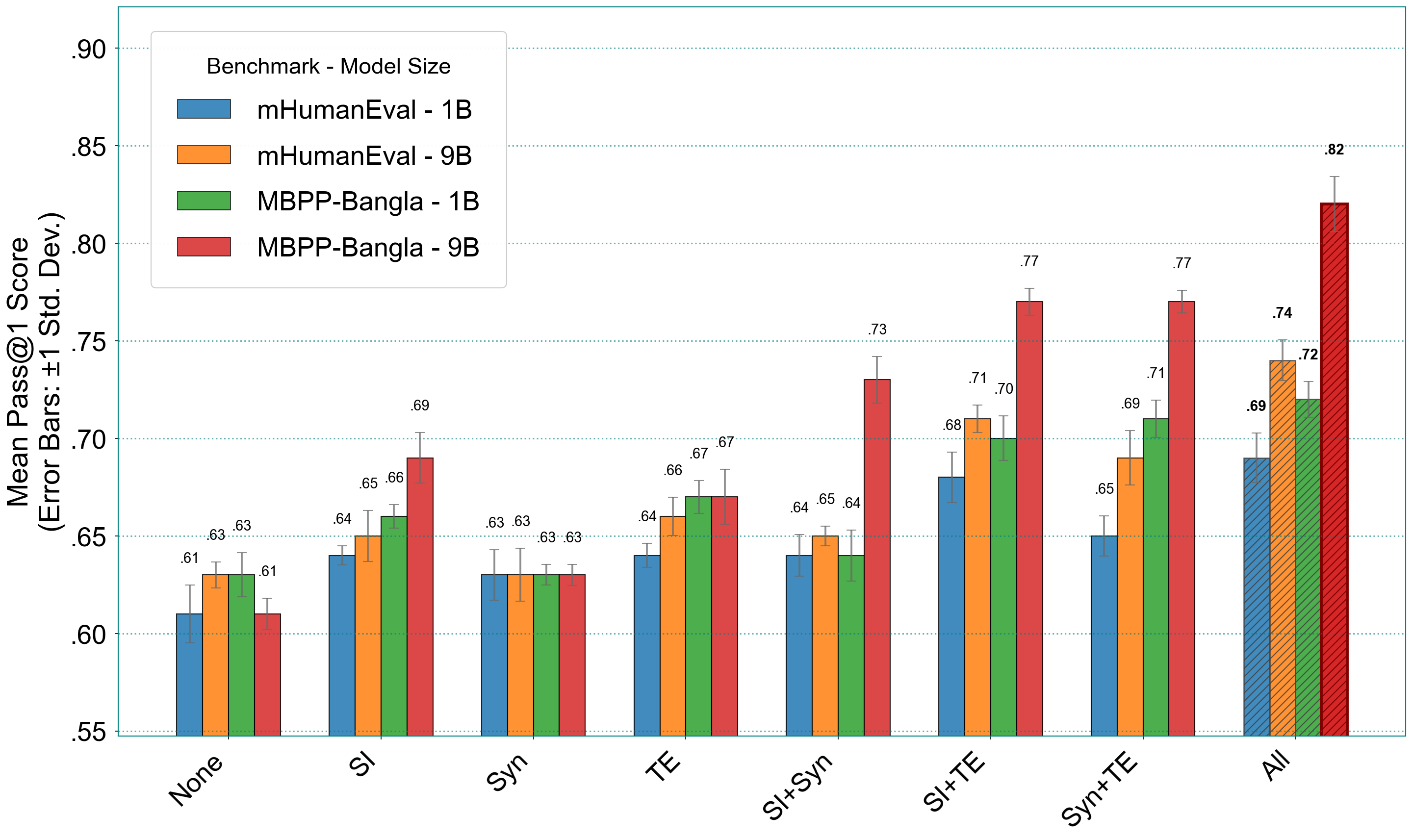
Figure 2: Performance (Pass@1) comparison for different combinations of the SI, Syn, and TE instruction datasets across model sizes (1B vs 9B).
TigerCoder models achieve strong numerical results:
- TigerCoder-1B: 0.69 Pass@1 on mHumanEval-Bangla, 0.74 Pass@1 on MBPP-Bangla.
- TigerCoder-9B: 0.75 Pass@1 on mHumanEval-Bangla, 0.82 Pass@1 on MBPP-Bangla.
These scores represent 4–8% improvements for the 1B model and 11–18% for the 9B model over the strongest prior baselines, including models up to 27× larger. The models also generalize well to C++, Java, JavaScript, and Ruby, consistently outperforming both proprietary and open-source alternatives.
Implications and Future Directions
The results decisively demonstrate that carefully curated, high-quality datasets can enable small, efficient models to outperform much larger systems on low-resource language tasks. This challenges the prevailing notion that scale alone drives performance, highlighting the critical role of targeted data curation and domain adaptation. The open-source release of TigerCoder, its datasets, and benchmarks provides a reproducible foundation for further research in Bangla and other underrepresented languages.
Theoretically, the work underscores the limitations of transfer learning and machine translation for code generation in low-resource languages, suggesting that direct, language-specific data is indispensable. Practically, TigerCoder sets a new standard for Bangla code generation and offers a blueprint for efficient LLM development in similar settings.
Conclusion
TigerCoder establishes a robust, reproducible approach for code generation in Bangla, achieving substantial performance gains through targeted data curation and fine-tuning. The research demonstrates that high-quality, language-specific datasets are essential for overcoming low-resource limitations, enabling small models to match or exceed the capabilities of much larger systems. This work has significant implications for the development of LLMs in underrepresented languages and provides a scalable methodology for future advancements in multilingual code generation.