- The paper introduces ToolSandbox, a dynamic benchmark incorporating stateful execution and implicit dependencies to assess LLM tool-use capabilities.
- It employs Milestones and Minefields to evaluate multi-turn, conversational tasks and reveals performance differences between proprietary and open-source models.
- The evaluation highlights LLM limitations in reasoning and state tracking, urging improvements in model architectures and training strategies.
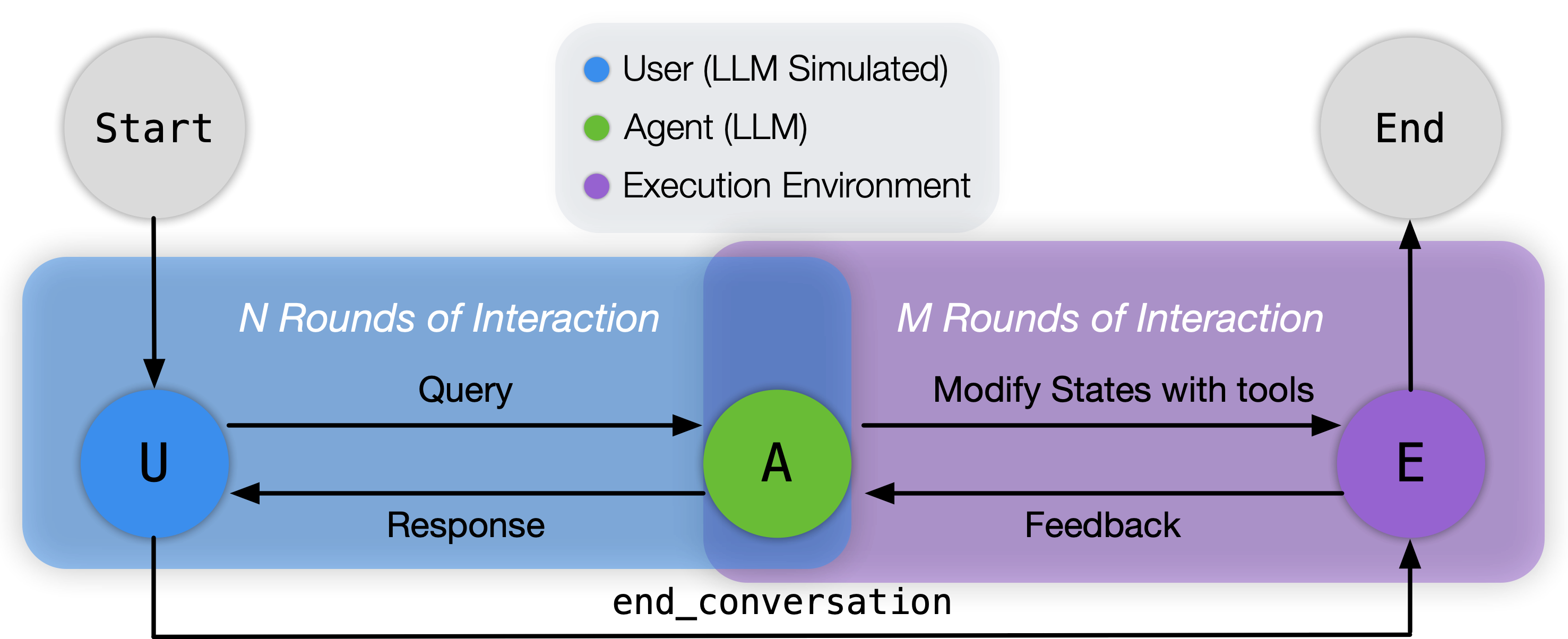
ToolSandbox introduces a novel benchmark for evaluating the tool-use capabilities of LLMs. It addresses key limitations in existing benchmarks by incorporating stateful tool execution, implicit dependencies, and a dynamic evaluation strategy. The following sections explore the design, implementation, and implications of ToolSandbox, focusing on its various components and evaluation metrics.
ToolSandbox aims to evaluate the real-world tool-use capabilities of LLMs, an area of growing research interest. Unlike previous benchmarks that rely on stateless interactions or off-policy dialogues, ToolSandbox introduces a stateful environment with implicit state dependencies. It evaluates LLMs in a conversational and interactive setting, providing insights into how these models handle complex, multi-turn tasks.
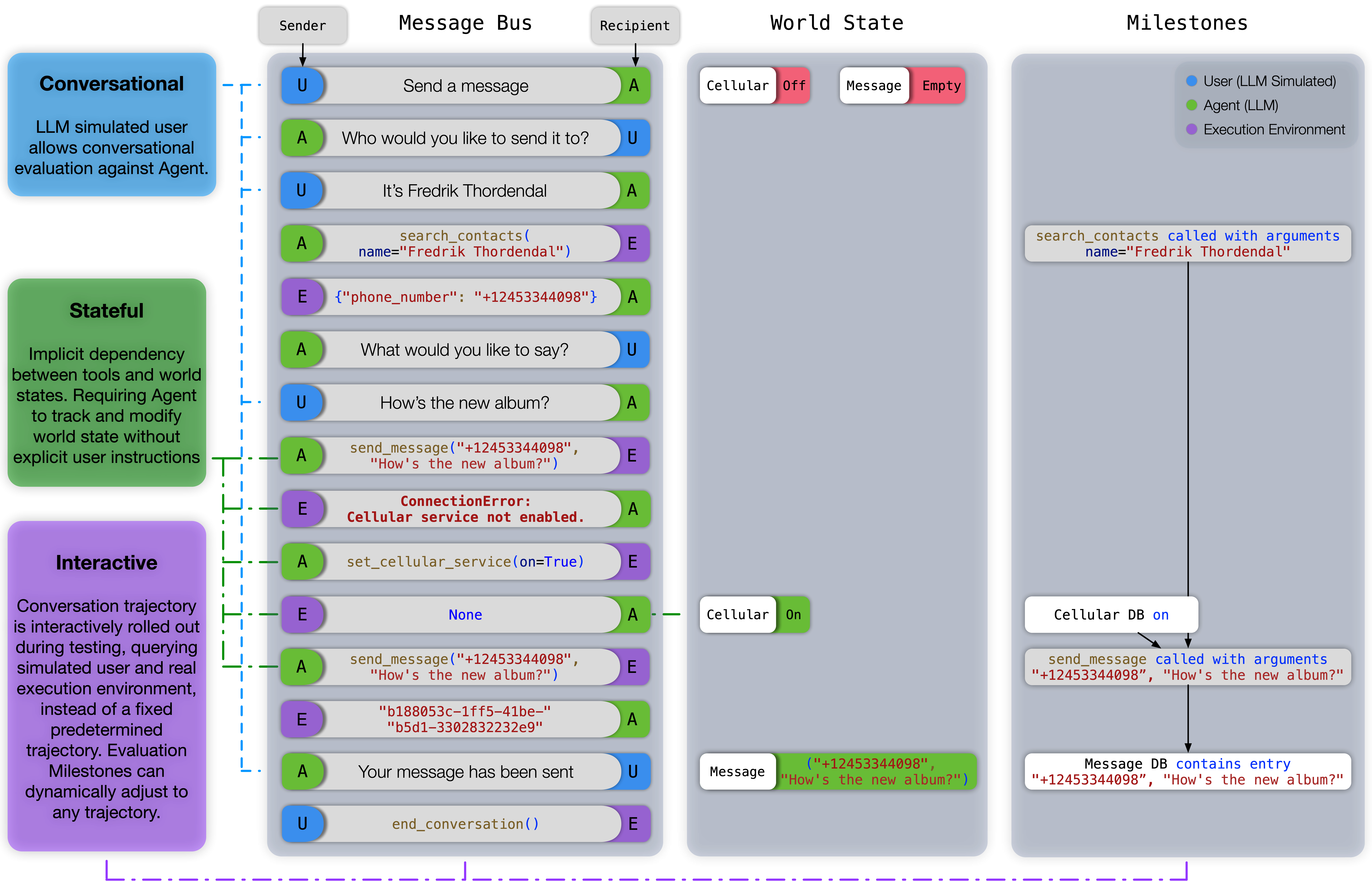
Figure 1: An example evaluation trajectory from ToolSandbox, illustrating the interaction between User, Agent, and Execution Environment.
Core Components
ToolSandbox is a Python-native testing environment, featuring the following components:
Evaluation Strategy
ToolSandbox employs an innovative evaluation strategy based on Milestones and Minefields:
- Milestones: Represent critical steps that must occur to achieve a goal. They allow for evaluating the sequence and correctness of tool interactions in a task.
- Minefields: Define events that must not happen, preventing illogical actions and hallucinations in task completion.
This approach provides rich intermediate and final execution signals, enabling a deep understanding of model performance.
Evaluation Results and Model Comparisons
ToolSandbox highlights a significant performance gap between proprietary and open-source models. Proprietary models like GPT-4o excel in complex tasks but still face challenges in scenarios like State Dependency and Canonicalization. The benchmark reveals that LLMs often struggle with tasks involving implicit dependencies and require improved reasoning and state-tracking capabilities.
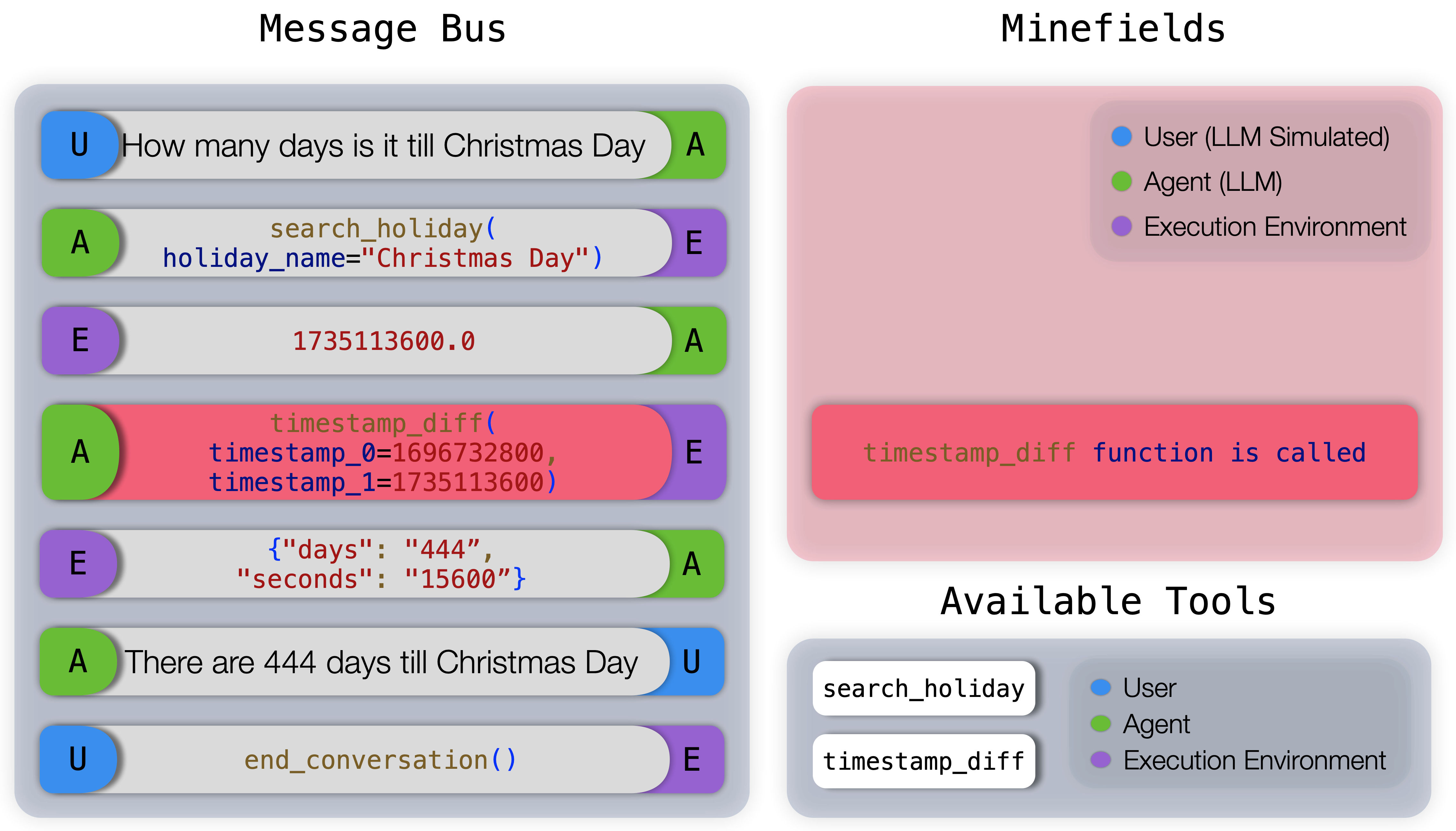
Figure 3: Example GPT-4 trajectory for Insufficient Information category Minefield Evaluation.
Implications and Future Directions
ToolSandbox's detailed evaluation metrics and diverse test scenarios offer new insights into the capabilities and limitations of LLMs in real-world tool use. The challenging nature of state dependencies and the requirement for accurate canonicalization highlight the need for improved LLM architectures and training strategies. ToolSandbox serves as a valuable resource for advancing research in LLM tool-use capabilities and can inspire future developments in this rapidly evolving field.
Conclusion
ToolSandbox redefines the evaluation of LLM tool-use capabilities by introducing stateful, conversational, and interactive test scenarios. It provides a comprehensive framework for understanding the strengths and weaknesses of current models and sets the stage for future advancements in this area. Through its innovative design and robust evaluation metrics, ToolSandbox contributes significantly to the field of AI research, promoting the development of more capable and efficient tool-use LLMs.