- The paper introduces a novel framework that integrates Diffusion Transformers with High-level Color Extractor and Low-level Color Guider to achieve precise animation colorization.
- It employs a sophisticated attention mechanism and a multi-stage training strategy to separately optimize geometric and color controls, resulting in improved PSNR, SSIM, and FVD metrics.
- Experimental validations and ablation studies confirm AnimeColor’s superior performance over existing methods, highlighting its practical benefits for animation production.
Introduction to AnimeColor
"AnimeColor: Reference-based Animation Colorization with Diffusion Transformers" presents a novel framework leveraging Diffusion Transformers (DiT) for animation colorization. Addressing the inherent challenges of color accuracy and temporal consistency in animation production, the paper introduces a methodology that integrates reference images and sketch sequences into a DiT-based model, facilitating controlled animation generation. The work proposes two pivotal components—the High-level Color Extractor (HCE) for semantic color consistency and the Low-level Color Guider (LCG) for fine-grained color precision—to guide the video diffusion process effectively.
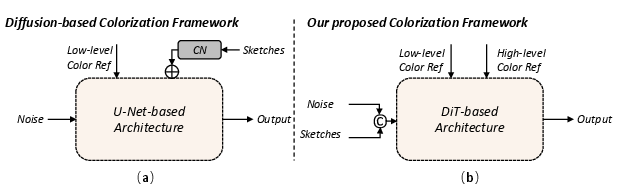
Figure 1: Illustration of the difference between our proposed AnimeColor and other diffusion-based animation colorization methods (CN denotes ControlNet).
Methodological Insights
Framework Utilization
AnimeColor employs Diffusion Transformers to enrich video generation capabilities. The model architecture, outlined in Figure 2, initiates with the concatenation of sketch latents and noise as inputs for DiT, leading to sketch-conditioned video production. The integration of high-level and low-level color references via HCE and LCG enhances the accuracy of color reproduction, improving semantic alignment and detail-level precision.
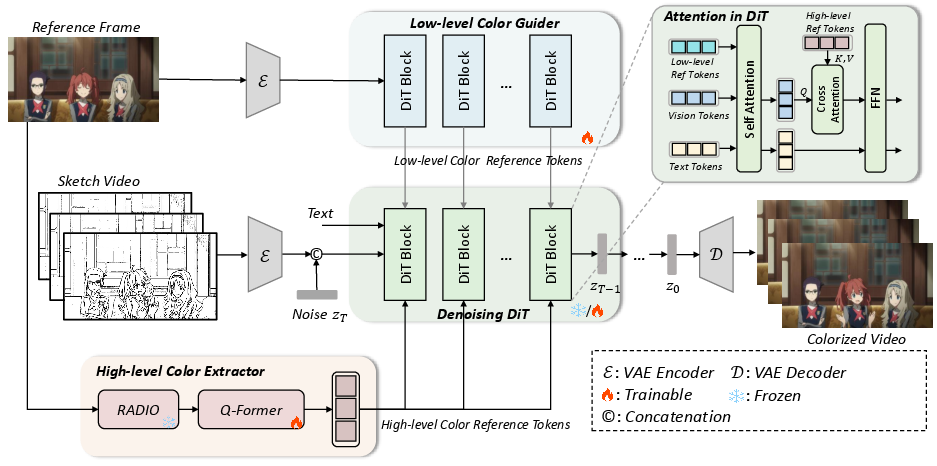
Figure 2: The framework of our proposed AnimeColor.
Attention Mechanism
The method employs a sophisticated attention mechanism to integrate color control, as depicted in the upper left corner of Figure 2. By concatenating low-level reference tokens with vision and text tokens, and utilizing self-attention and cross-attention blocks, fine-grained and semantic color control is achieved without introducing inconsistencies.
Multi-stage Training Strategy
A four-stage training strategy prevents the intertwining of geometric and color controls during model optimization. This approach ensures each module performs its function without excessive training burdens, promoting stability in temporal consistency and color accuracy.
Experimental Validation
Qualitative Comparisons
AnimeColor demonstrates superior performance compared to alternative methods such as CN+IPA, AniDoc, ToonCrafter, and LVCD across a range of challenging scenarios, as illustrated in Figures 3 and 4. The model excels in maintaining color consistency and visual quality in scenes characterized by large motion and varied sketch inputs.


Figure 3: Qualitative comparison of reference-based colorization with CN+IPA, Concat, Anidoc, ToonCrafter, and LVCD.
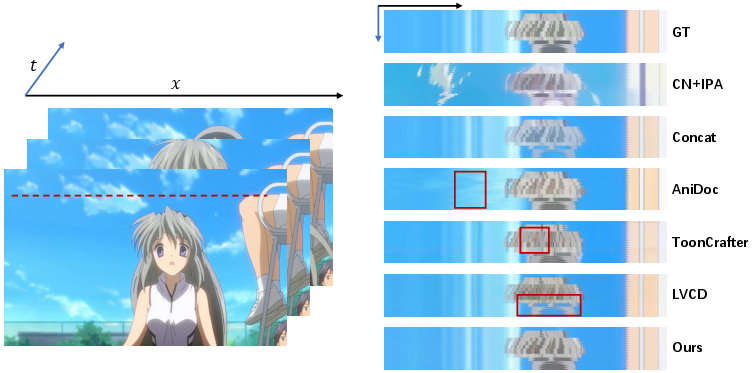
Figure 4: Temporal profile comparison of different animation colorization methods.
Quantitative Metrics
The paper reports significant improvements in metrics such as PSNR, SSIM, and FVD, indicating enhanced color accuracy and visual quality relative to existing methods. Table 1 outlines these results, reinforcing the efficacy of the proposed framework.
User Preferences
A user study (Figure 5) corroborated the model's effectiveness, with AnimeColor preferred by a substantial portion of participants, suggesting its practical applicability in animation production settings.
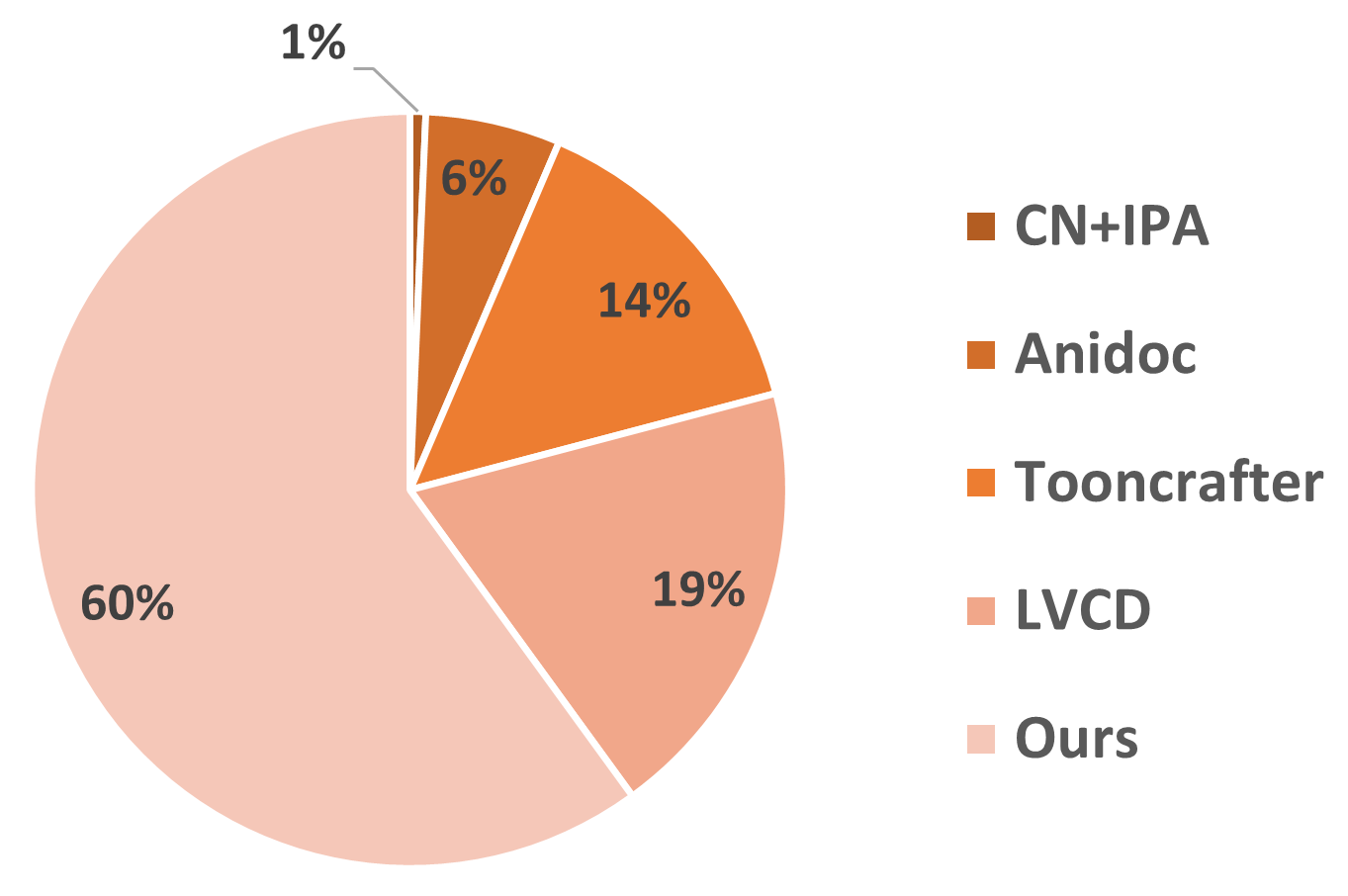
Figure 5: The results of user study, where AnimeColor is preferred by the majority of the group.
Ablation Studies
Component Efficacy
Ablation experiments affirm the importance of HCE and LCG, showing marked improvements in performance metrics when these components are integrated. Figures 6, 7, and 8 illustrate how each module contributes to the model's overall success.

Figure 6: Qualitative comparison about ablation study on model architecture.

Figure 7: Qualitative comparison about ablation study on sketch conditional modeling.

Figure 8: Qualitative comparison about ablation study on image encoder in High-level Color Extractor.
Applications
AnimeColor's flexibility is demonstrated through diverse applications, including varying sketch references and natural images, as shown in Figures 9 and 10. This adaptability highlights its potential for broader deployment in animation studios and creative projects.
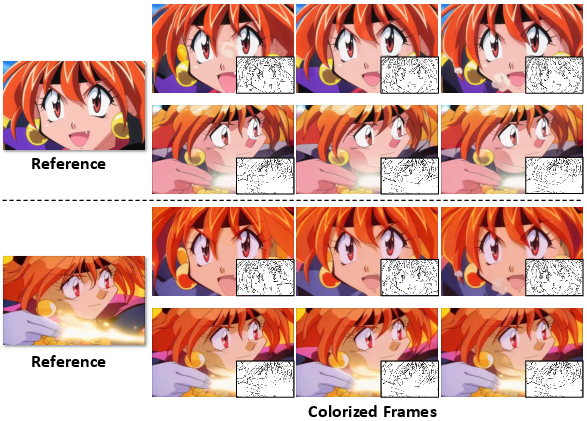
Figure 9: Illustration of the flexible application with Same Reference image and Different Sketches" andSame Sketches and Different Reference Images" settings.

Figure 10: Impact of different lineart extraction methods.

Figure 11: Colorization performance with natural images as reference.
Conclusion
AnimeColor presents a robust framework for enhancing animation colorization, leveraging the generative capabilities of DiT to address longstanding challenges in the field. Its integration of high-level and low-level color references ensures precise control, making it a valuable tool for animation studios seeking efficient, high-quality production methods. The release of the framework under open-source licensing will likely spur further innovation in the domain, fostering advancements in both industrial applications and academic research.

