- The paper presents the TIM model, which recursively decomposes complex tasks into subtask trees to preserve higher-level instructions.
- It details TIMRUN, an inference runtime that prunes irrelevant subtasks to optimize memory use and improve throughput.
- Experimental results show that the system maintains strong performance on STEM benchmarks while generalizing effectively to novel tasks.
Thread Inference Model (TIM) for Long-Horizon Reasoning
This paper introduces the Thread Inference Model (TIM) and its dedicated runtime, TIMRUN, designed to overcome the context length limitations of LLMs when applied to long-horizon reasoning tasks. TIM employs a novel approach of recursively decomposing complex tasks into subtasks, while TIMRUN manages memory efficiently by pruning irrelevant subtasks during inference.
Thread-2: Recursive Subtask Trees
The authors model reasoning trajectories as recursive subtask trees, where each node represents a task comprising a thought process, optional tool use, subtasks, and a conclusion. This structure, named Thread-2, improves upon the original Thread framework by ensuring that subtasks have access to the instructions of higher-level tasks, preventing information gaps and enabling end-to-end inference within a single LLM call.
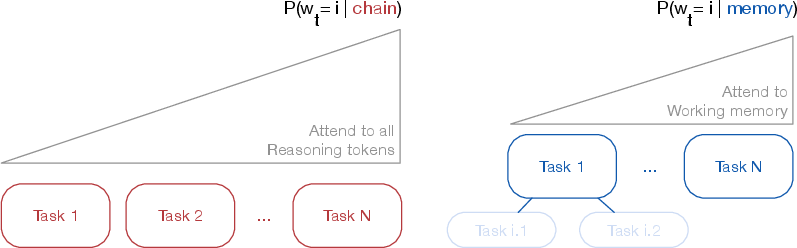
Figure 1: Latent information compression for all context tokens versus structural latent information compression focusing on the working memory enabled by parsing the reasoning trajectory.
A key aspect of Thread-2 is its subtask pruning mechanism, which reduces the complexity of the reasoning context by selectively retaining only the most relevant information. This is achieved using a subtask stack with a fixed size, where completed subtask lists are added to the stack, and the earliest subtask list is pruned from the working memory when the stack exceeds a defined threshold. The authors implement JSON decoding using schemas, which allows for efficient extraction of tool parameters. TIM waits until receiving tool responses in the reasoning runtime and extends its KV cache by encoding them as batches of new input tokens. An example of the JSON schema used for constrained decoding is shown in (Figure 2).
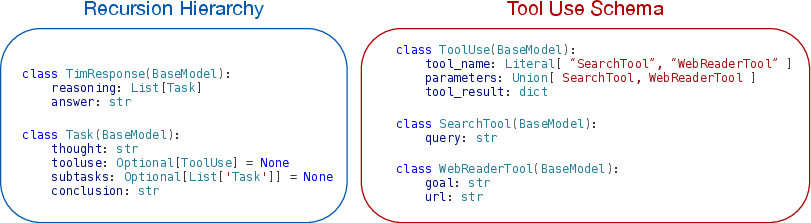
Figure 2: The pydantic class we use to create the JSON schema for constrained decoding.
TIMRUN: Inference Runtime for Thread-2
TIMRUN is an inference runtime system specifically designed for the TIM model, addressing the deployment challenges posed by the Thread-2 reasoning framework. TIMRUN supports the reuse of GPU memory and positional embeddings for output generation, enabling long-horizon reasoning that exceeds the output limit of many LLMs. Subtask pruning is essential for efficiently implementing TIM and sustaining long-term reasoning. TIMRUN keeps a pruning buffer, a stack that temporarily caches a small set of prunable subtasks, retaining just enough redundancy to ensure lossless information flow. The subtask pruning process is shown in (Figure 3).
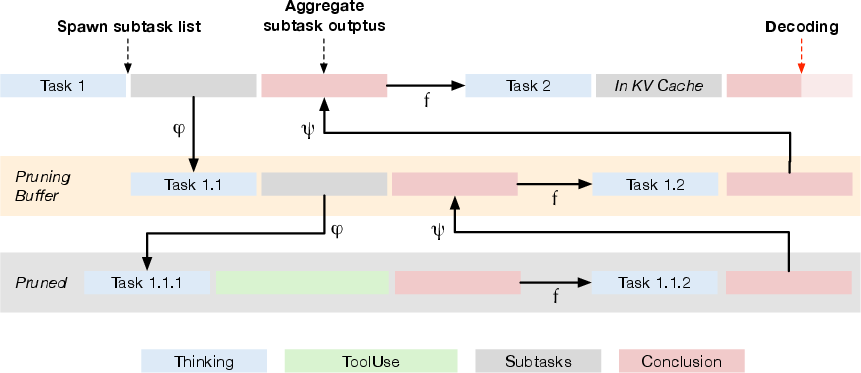
Figure 3: While TIM is decoding the conclusion of task 2, tokens in task 1.1.1 and 1.1.2, including the enclosed tool call and response have been pruned from the KV-cache.
TIMRUN initiates tool calls directly within the runtime, extracting relevant parameters and forwarding the request to the external tool. This approach reduces inter-module communication, streamlining agent development and deployment. A comparison of the communications among clients, tools, and different inference runtimes is shown in (Figure 4).
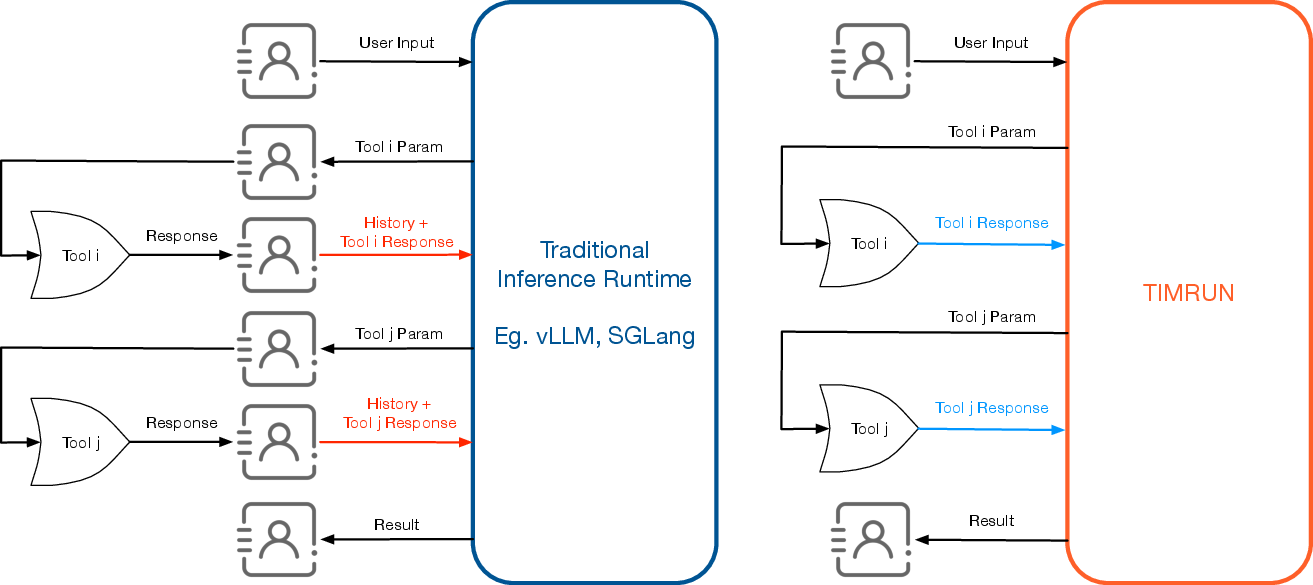
Figure 4: Comparing the communications among clients, tools, and different inference runtimes.
Experimental Results
The authors evaluated TIM models on MATH500, MMLU-STEM500, AMC 2022, AMC 2023, AIME 2024, and GPQADiamond to assess their STEM knowledge and reasoning abilities. The results demonstrate that subtask pruning in TIMRUN does not degrade overall performance, and in some cases, it improves performance by retaining only the most relevant information in the KV cache. The authors also evaluated TIM models on agentic research tasks, using the BrowseComp and Datacommons QA benchmarks, both requiring multi-hop information retrieval, processing of tool responses, and reasoning. The reported performance shows that the TIM model generalizes well to novel tasks not encountered during training, offering greater efficiency by eliminating the need for carefully crafted few-shot examples and task-specific prompts.
Experiments testing the efficiency of TIMRUN focused on memory management overhead and throughput. The results showed that TIMRUN delivers improved throughput, due to the balance it strikes.
Conclusion
The authors introduce a co-designed system consisting of the TIM model and its dedicated serving infrastructure, TIMRUN. Experiments show that generating a more concise KV cache increases inference throughput and enhances performance by helping the model focus on relevant context. The combination of TIM and TIMRUN delivers strong reasoning ability, more efficient inference and tool use, and greater flexibility and scalability for agentic tasks.