- The paper introduces a self-improvement method for LLMs that uses chain-of-thought prompting and self-consistency to generate high-confidence rationales.
- The methodology fine-tunes models on self-generated reasoning paths, yielding significant accuracy gains on benchmarks like GSM8K and DROP.
- Experimental results highlight improved performance metrics and underscore the potential of unsupervised self-optimization in large language models.
LLMs Can Self-Improve
Introduction
The paper "LLMs Can Self-Improve" (arXiv ID: (2210.11610)) investigates the capability of LLMs to enhance their reasoning abilities through a self-improvement mechanism without requiring labeled datasets. By leveraging Chain-of-Thought (CoT) prompting and self-consistency techniques, the authors propose a method that enables LLMs to generate "high-confidence" rationale-augmented answers for unlabeled questions, which are then used to fine-tune the model. This approach demonstrates significant improvements in general reasoning ability across multiple benchmarks such as GSM8K, DROP, OpenBookQA, and ANLI-A3. The method achieved state-of-the-art performance without relying on any ground truth labels.
Methodology
The self-improvement framework utilizes pre-trained LLMs to generate multiple reasoning paths for each question using CoT prompting. The most consistent answer is selected through majority voting, denoted as self-consistency. Fine-tuning the model on these high-confidence reasoning paths augments the training process, mimicking the metacognitive capabilities of human reasoning.
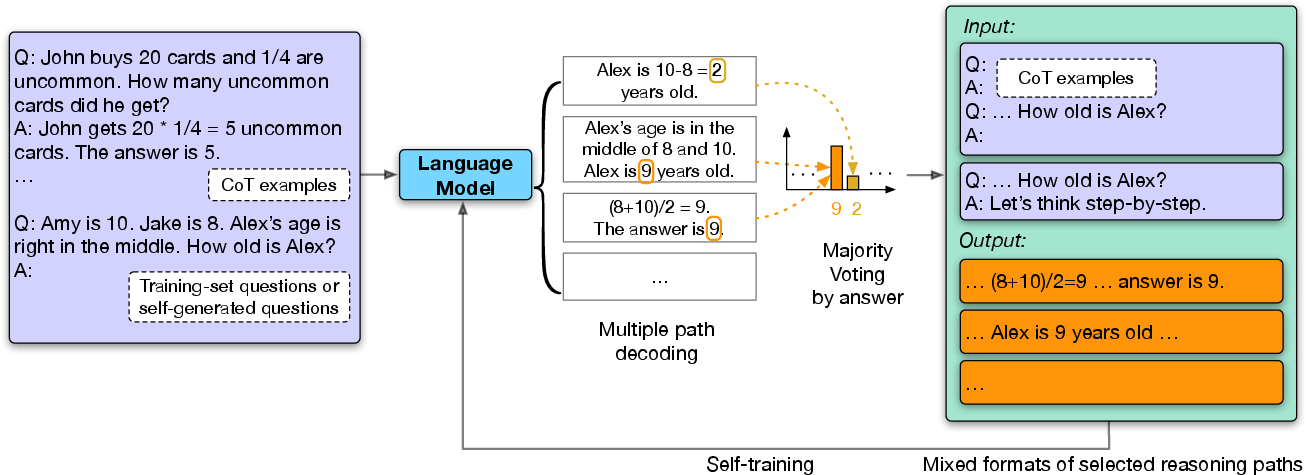
Figure 1: Overview of our method. With Chain-of-Thought (CoT) examples as demonstration.
To augment the LLM without supervision, the method begins by applying few-shot CoT for each question. The model then samples multiple reasoning paths with diverse outputs, selecting only those paths consistent with the majority answer. These filtered paths become self-generated training data. The model is further fine-tuned with mixed formats, including direct answers and CoT paths, avoiding overfitting to specific prompt styles.
Results
The experimental results demonstrated considerable improvement in reasoning benchmarks. The methodology applied on models such as PaLM-540B showcased significant advances in performance metrics, achieving substantial accuracy gains compared to pre-self-improvement baselines.
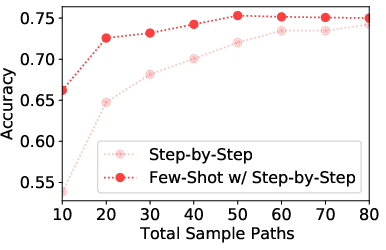
Figure 2: Accuracy results on GSM8K test set using PaLM-540B model with multi-path sampling and self-consistency.
For tasks such as arithmetic reasoning and commonsense reasoning on datasets like GSM8K, DROP, and OpenBookQA, this approach led to performance boosts without using labeled data:
- GSM8K: Improved from 74.4% to 82.1% using self-consistency.
- DROP: Increased from 78.2% to 83.0%.
- OpenBookQA: Enhanced from 90.0% to 94.4%.
- ANLI-A3: Rose from 63.4% to 67.9%.
Hyperparameter Study
An exploration into the hyperparameters, such as sampling temperature, indicated that a higher temperature of 1.2 post-improvement yielded better reasoning performance compared to pre-training configurations. Similarly, optimizing the number of sampled reasoning paths showed efficiency in reaching high accuracy scores with fewer resources.
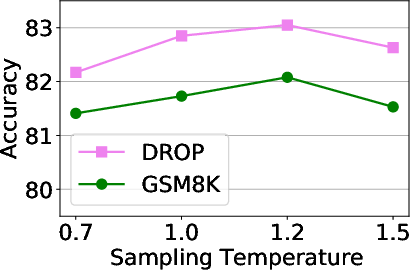
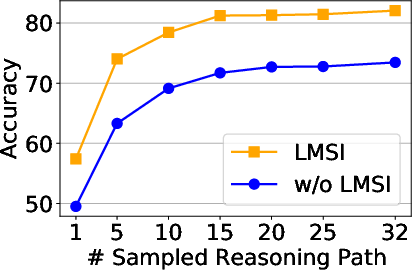
Figure 3: Hyperparameter study results.
Additionally, experiments highlighted the feasibility of distilling reasoning knowledge to smaller models, allowing for enhanced performance across different model architectures without incurring additional computational costs.
Implications and Future Directions
The paper presents a compelling case for self-improvement in LLMs, emphasizing its potential to reduce the dependency on meticulously curated datasets. The robustness of LLMs to generate reliable training samples autonomously can significantly mitigate data bottlenecks encountered in model development.
Future research could focus on integrating this framework with existing supervised paradigms to elevate LLMs' scalability and applicability across more complex real-world tasks. The idea of encouraging LLMs to self-generate questions and prompts opens avenues for enhanced task-specific adaptation, further pushing the envelope of unsupervised learning methodologies.
Conclusion
The findings delineate a novel approach for self-improvement in LLMs, leveraging their reasoning capabilities to refine their output on unseen tasks effectively. This signifies a step forward in understanding and harnessing the emergent capabilities of LLMs in autonomous learning, setting the stage for AI systems that can continually self-optimize.