- The paper shows that benchmark scores are unreliable because they reflect superficial lexical patterns instead of genuine reasoning.
- It employs human annotation on SocialIQa, FauxPas-EAI, and ToMi benchmarks to identify structural, semantic, and pragmatic flaws.
- It recommends shifting to dynamic, process-oriented evaluation methods, such as structured rationale assessment and LLM-as-a-judge.
Garbage In, Reasoning Out? Why Benchmark Scores are Unreliable and What to Do About It
This essay presents an extensive audit of reasoning benchmarks used to evaluate LLMs, highlighting pervasive flaws in their design and evaluation methods. The authors argue that current benchmark scores often reflect superficial lexical alignment rather than genuine reasoning capabilities.
Benchmark Analysis
The paper investigates SocialIQa, FauxPas-EAI, and ToMi benchmarks using five LLMs—GPT-3, GPT-3.5, GPT-4, GPT-o1, and LLaMA 3.1—serving as diagnostic tools to identify errors in benchmark data and methodology. Their analysis revealed that inconsistencies in these benchmarks result from duplicated items, ambiguous wording, implausible answers, and methodologies prioritizing form over substance. By conducting a systematic audit with human annotation, the authors reveal critical limitations in scoring metrics that impact reported performance.
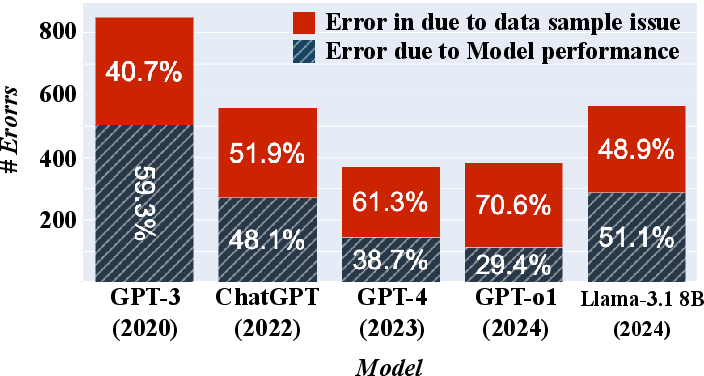
Figure 1: Breakdown of total errors for each model on SocialIQA dev set, demonstrating a significant portion of errors due to benchmark flaws.
Dataset- and Evaluation-Level Issues
The audit categorized errors into structural, semantic, and pragmatic flaws within SocialIQa and ToMi datasets. Structural flaws included duplicate or malformed items that hindered the validity of reasoning evaluation, while semantic flaws involved ambiguous or illogical question and answer pairs. Pragmatic flaws highlighted unrealistic scenarios or culturally biased assumptions, impacting the interpretation of model performance.
In ToMi, flaws were also related to context fragmentation, semantics-agnostic scoring, and granularity mismatches in model responses. This distorts evaluation by failing to provide coherent context during multi-step inference tasks, penalizing semantically valid answers due to lexical variations, and overlooking necessary detail in responses.
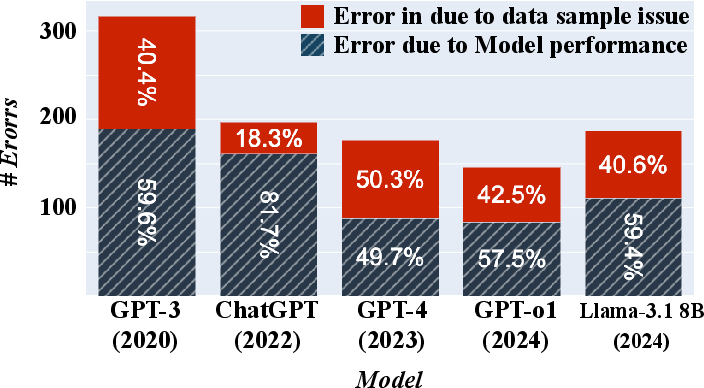
Figure 2: Breakdown of total errors for each model on ToMi, illustrating where reasoning errors and benchmark flaws impact model scores.
Implications of High Scores
Upon filtering out flawed data and conducting context-aware evaluations, models showed improved performance but demonstrated instability when subjected to surface-level variations. High scores were often a result of alignment with benchmark artifacts rather than inference-based reasoning. The performance fluctuations during semantically equivalent rephrasing trials indicated sensitivity to specific lexical formats and not robust reasoning.
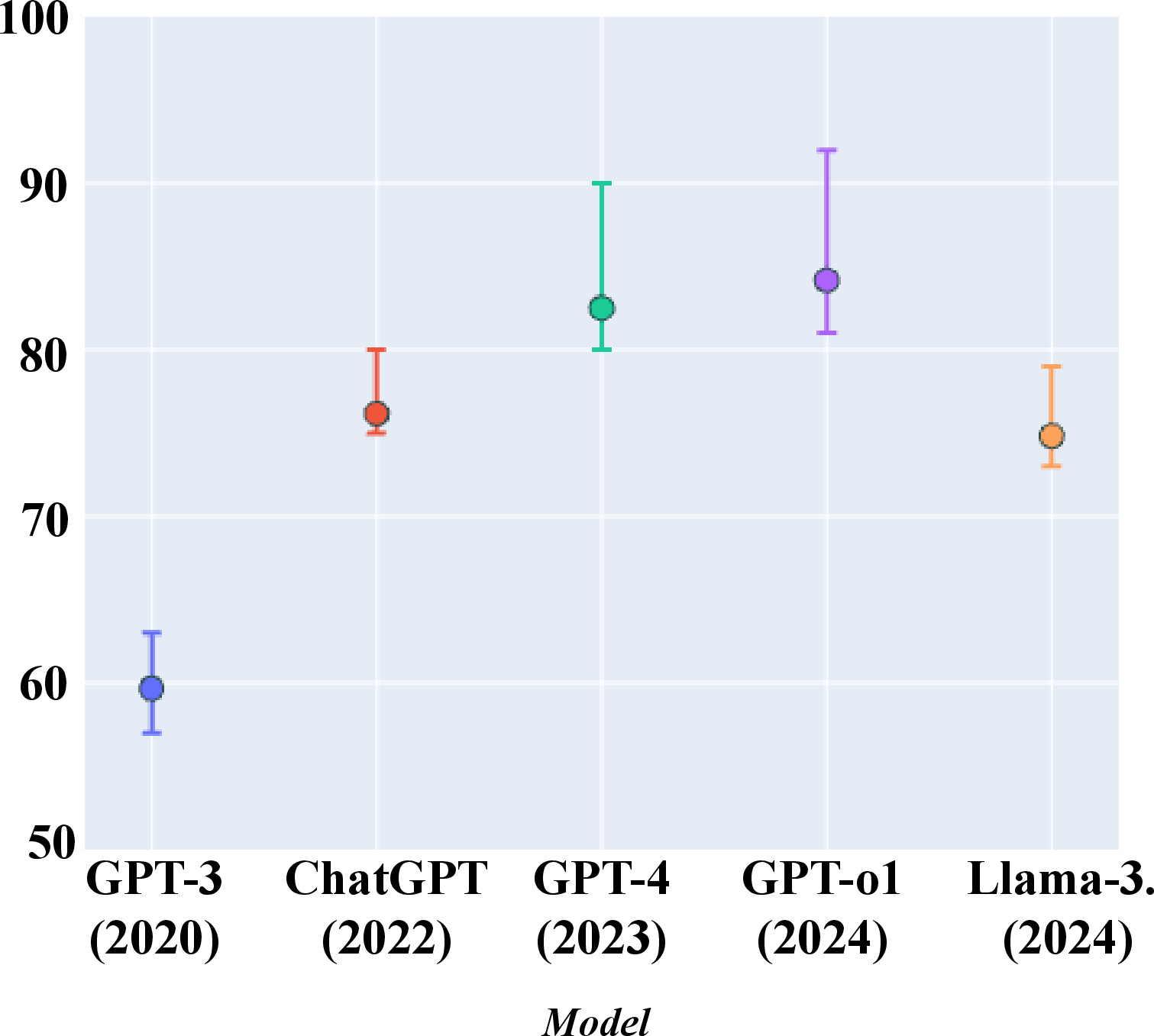
Figure 3: Performance on SocialIQa under semantically equivalent rephrasings, revealing sensitivity to surface-level variation.
Recommendations for Future Evaluation
The findings advocate for a shift from static output metrics to evaluations grounded in reasoning processes. Suggested alternatives include structured rationale evaluation, contradiction detection, counterfactual testing, and interactive diagnostic formats. These approaches emphasize reasoning as a dynamic and explainable process, crucial for accurately assessing model competence.
Use of LLM-as-a-Judge
The paper briefly explores using LLMs as evaluators for meaning-aware scoring as a scalable alternative to semantics-agnostic metrics. The experiment showed that LLMs can provide reasonable evaluations of model predictions, suggesting a potential role for LLMs in diagnostic evaluations alongside human judgments.
Conclusion
The audit reveals fundamental shortcomings in current reasoning benchmarks and highlights the need for more process-oriented evaluation methods that assess inference from context rather than lexical alignment. These findings underscore the importance of transitioning from static benchmarks to dynamic evaluative approaches to better reflect the reasoning and inferential capabilities of LLMs.
By acknowledging the limitations and biases intrinsic to existing benchmarks, this paper suggests imperative reforms toward developing more reliable and contextually grounded evaluation protocols for future LLM research and implementation.