- The paper presents MR-Ben, a benchmark evaluating System-2 thinking by detecting and explaining reasoning errors in LLMs.
- It leverages expert-annotated data from 5,975 questions across subjects, using metrics like step and reason accuracy.
- Results reveal that while LLMs excel in outcome-based tasks, they struggle with deep reasoning, guiding future model improvements.
Introduction to MR-Ben Benchmark
The paper presents MR-Ben, a meta-reasoning benchmark designed for evaluating System-2 thinking capabilities in LLMs. Traditional benchmarks have primarily focused on outcome-based evaluations, which often overlook the quality of the reasoning processes that lead to those outcomes. MR-Ben aims to address this gap by providing a more comprehensive framework that evaluates the meta-reasoning skills of LLMs. Specifically, MR-Ben challenges LLMs to locate and analyze potential errors in automatically generated reasoning steps across various subjects.
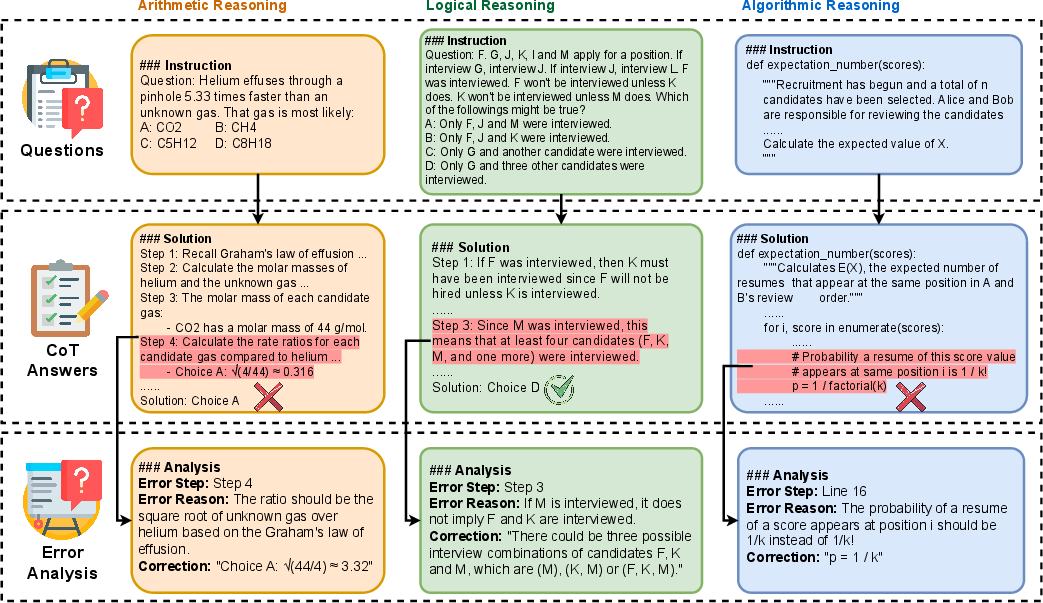
Figure 1: Overview of the evaluation paradigm and representative examples in Mr-Ben, illustrating the Chain-of-Thought and error analysis process.
Dataset Construction and Annotation
MR-Ben comprises 5,975 questions across diverse domains such as physics, chemistry, logic, coding, and more. The dataset includes manually annotated solutions from experts, detailing solution correctness, the first error step, and reasons for errors. The dataset is designed to cover arithmetic, logical, and algorithmic reasoning types, offering a rich source for evaluating LLMs' capabilities in identifying and explaining reasoning errors.
The dataset construction involves a rigorous annotation process where domain experts assess the solution correctness and provide detailed analyses of the reasoning errors and their corrections. This ensures the high quality and reliability of the benchmark.
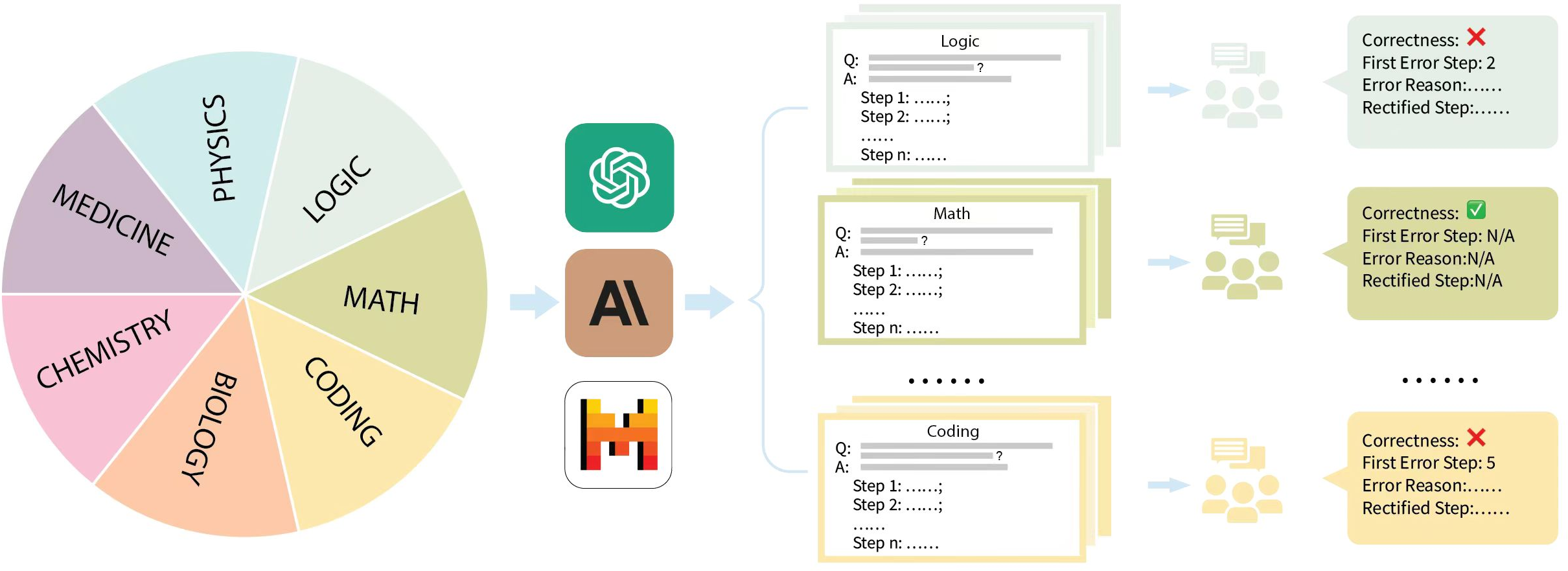
Figure 2: Dataset creation pipeline of Mr-Ben, highlighting question compilation and solution annotation by domain experts.
Evaluation Methodology
MR-Ben employs a unique evaluation framework that goes beyond accuracy metrics. It uses a combination of Matthews Correlation Coefficient, step accuracy, and reason accuracy to calculate the MR-Scores. These metrics provide a comprehensive assessment of an LLM's ability to understand and correct reasoning errors.
The evaluation framework is designed to challenge LLMs to act as a teacher, evaluating the reasoning process by assessing correctness, analyzing errors, and providing corrections.
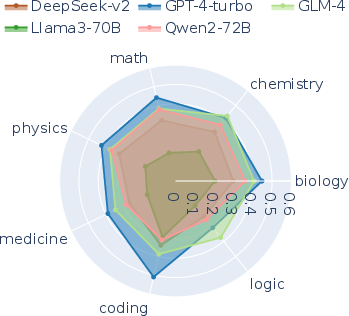
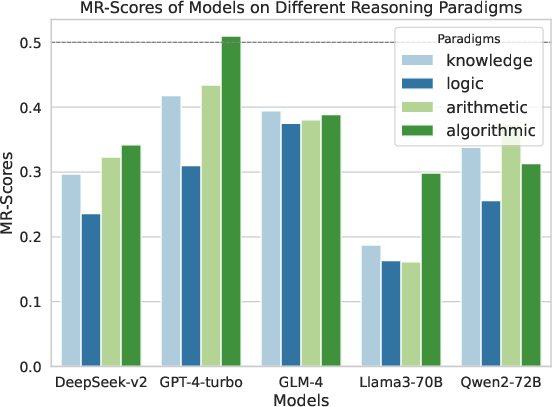
Figure 3: Model performance across subjects, showcasing the comprehensive evaluation of reasoning abilities.
Experimental Results
The paper evaluates the performance of various LLMs on MR-Ben, revealing distinct limitations in their reasoning abilities. Open-source models, despite performing comparably to GPT-4 on outcome-based benchmarks, show significant gaps in reasoning processes when evaluated with MR-Ben.
Strengths and weaknesses across different domains are highlighted, indicating areas where LLMs excel and where they struggle. Techniques such as leveraging synthetic data are discussed as potential pathways to improve reasoning capabilities.
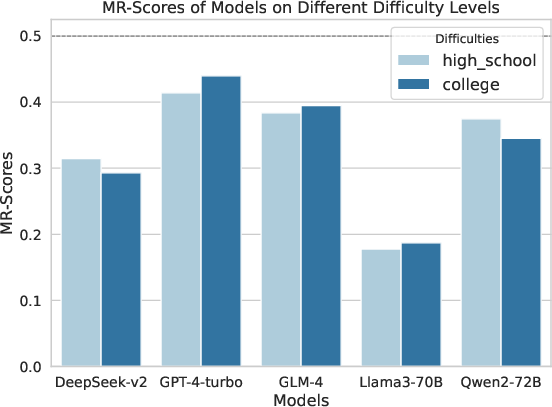
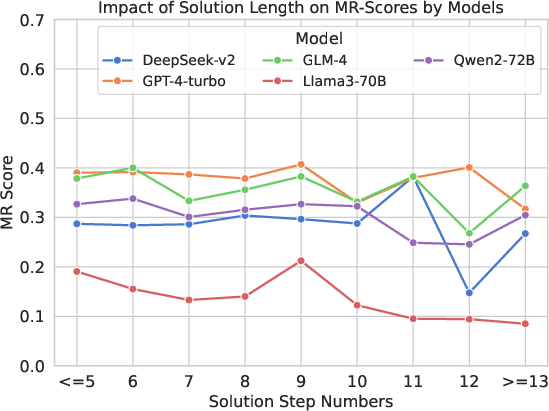
Figure 4: MR-Scores of different models on different levels of difficulty, illustrating the variability in performance.
Implications and Future Directions
MR-Ben provides valuable insights into the reasoning capabilities of current LLMs and opens up several avenues for future research. The benchmark is expected to guide researchers in developing models with better reasoning abilities that can understand and correct errors more effectively.
The findings suggest that enhancing LLMs' reasoning capabilities requires a focus on improving meta-reasoning skills. This can be achieved through advanced training methods and data synthesis techniques that enhance understanding of the reasoning process.
Conclusion
MR-Ben represents a significant advancement in the evaluation of reasoning capabilities in LLMs. By focusing on meta-reasoning, it provides a more nuanced understanding of LLMs' cognitive processes, highlighting areas for improvement and offering pathways for the development of more sophisticated AI reasoning frameworks.
The benchmark serves as a critical tool for researchers and developers aiming to enhance the decision-making and problem-solving abilities of LLMs, ultimately contributing to more robust AI systems capable of more complex and nuanced reasoning tasks.

