- The paper introduces an energy-efficient deep RL method using quantized spiking neural networks on SpiNNaker2, achieving significant energy savings compared to GPUs.
- The methodology incorporates surrogate gradient backpropagation and 8-bit weight quantization to enable real-time control in tasks like CartPole and Acrobot.
- Results demonstrate up to 32× energy consumption reduction while maintaining comparable inference latency and performance on neuromorphic hardware.
This paper presents an energy-efficient implementation of a reinforcement learning algorithm using quantized spiking neural networks (SNNs) on the SpiNNaker2 neuromorphic hardware platform. The primary focus is on training deep spiking Q-networks (DSQNs) for robotic control tasks, achieving significant reductions in energy consumption and maintaining comparable inference latency to GPU-based systems.
Introduction
Spiking Neural Networks (SNNs) are compelling alternatives to traditional artificial neural networks (ANNs), leveraging asynchronous updates and discrete spikes to reduce power consumption and computational load. Neuromorphic platforms like SpiNNaker2 exploit these attributes, offering scalable and real-time performance in energy-constrained applications. Despite theoretical alignment, deploying RL algorithms with SNNs remains a complex challenge due to the tight coupling between algorithmic design and hardware constraints.
The authors explore deploying SNN-based Deep Q-Learning on SpiNNaker2, showcasing its potential for low-power, real-time control across various tasks.
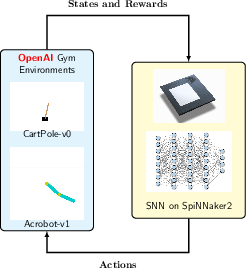
Figure 1: Pipeline Overview: Closed-loop SNN-based RL with SpiNNaker2.
Methodology
Model Architecture
The authors detail the architecture for training DSQNs using Q-learning, which involves surrogate gradient backpropagation in spiking networks. The architecture consists of leaky integrate-and-fire (LIF) neurons interleaved in fully connected layers. The dynamic evolution of membrane potentials is governed by:
ut+1j=βutj+i∑wijzti−ztjθ
where utj represents the membrane potential, β is the decay factor, wij are the synaptic weights, and θ is the firing threshold.
The architecture accommodates signed input encoding to represent continuous observations from environments like CartPole and Acrobot. State vectors are encoded into spike trains using rate coding, which is compatible with SpiNNaker2's hardware capabilities.
Model Quantization
The quantization strategy involves mapping floating-point weights to 8-bit integers post-training, with necessary scaling factors to maintain precision. Empirical testing determined scaling factors (λ) that preserve dynamic range without saturation, ensuring robust signal propagation post-quantization.
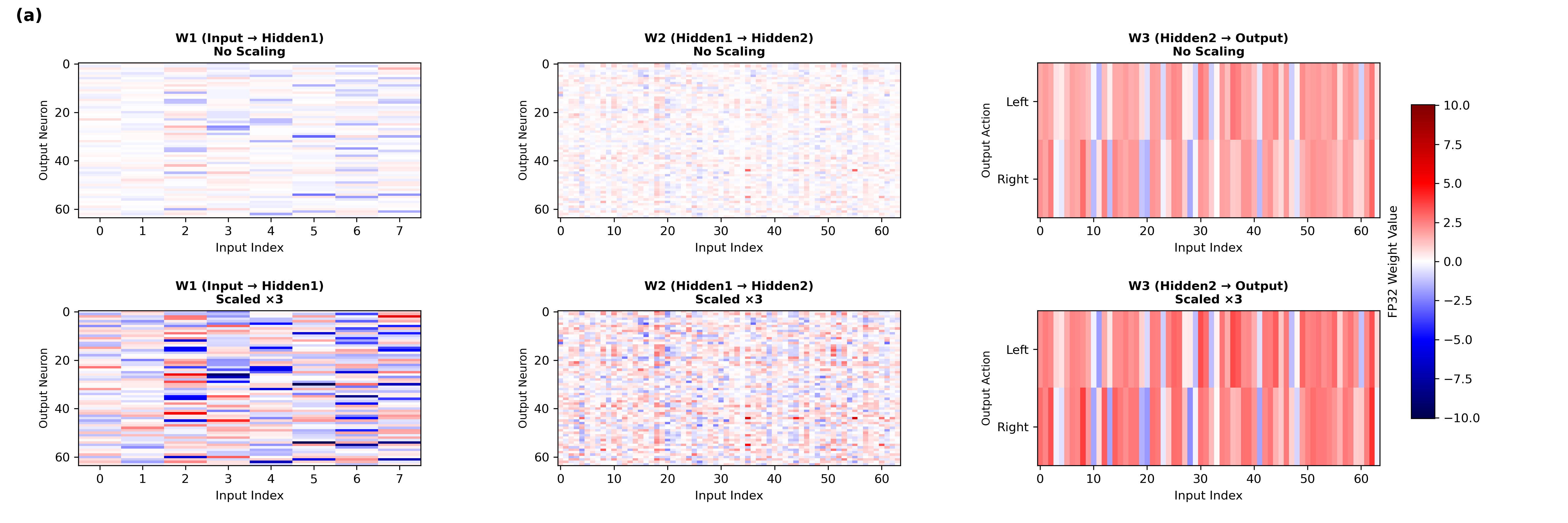
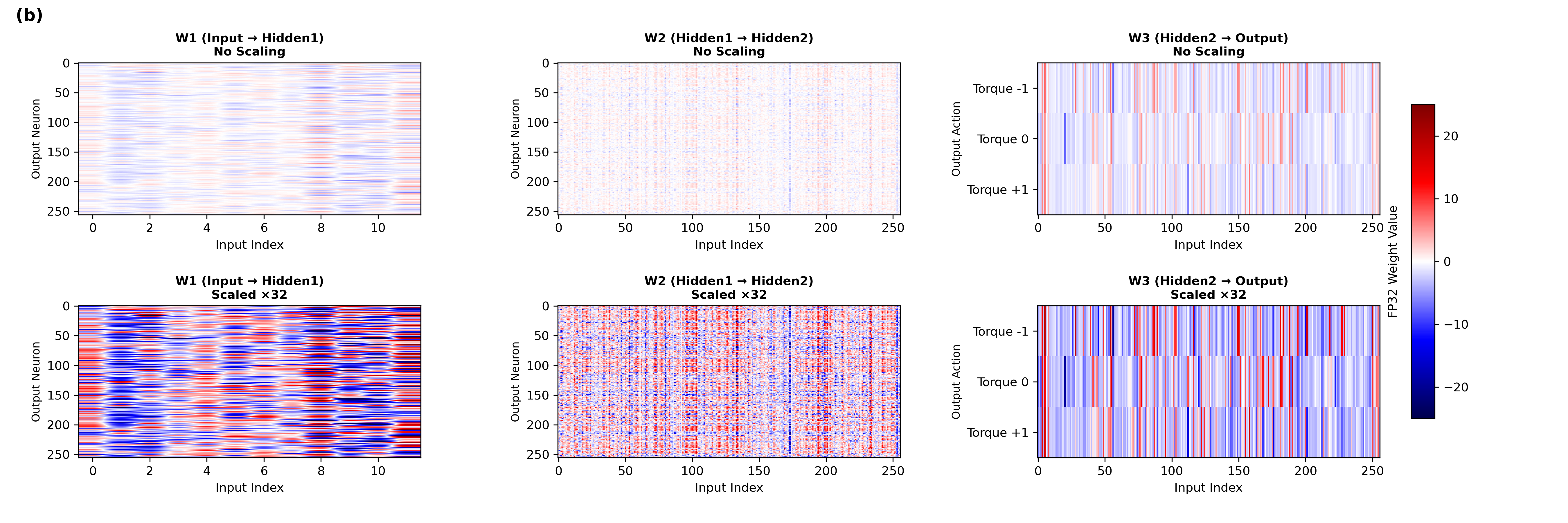
Figure 2: Effect of Uniform Full-Layer Quantization Scaling in CartPole-v0 and Acrobot-v1.
Encoding and Decoding Strategies
For input encoding, features are transformed into a two-neuron format representing positive and negative values. Rate coding then translates these values into spike trains. Output selection relies on reading the final membrane potentials of output neurons, with spikes inhibited by setting high firing thresholds.
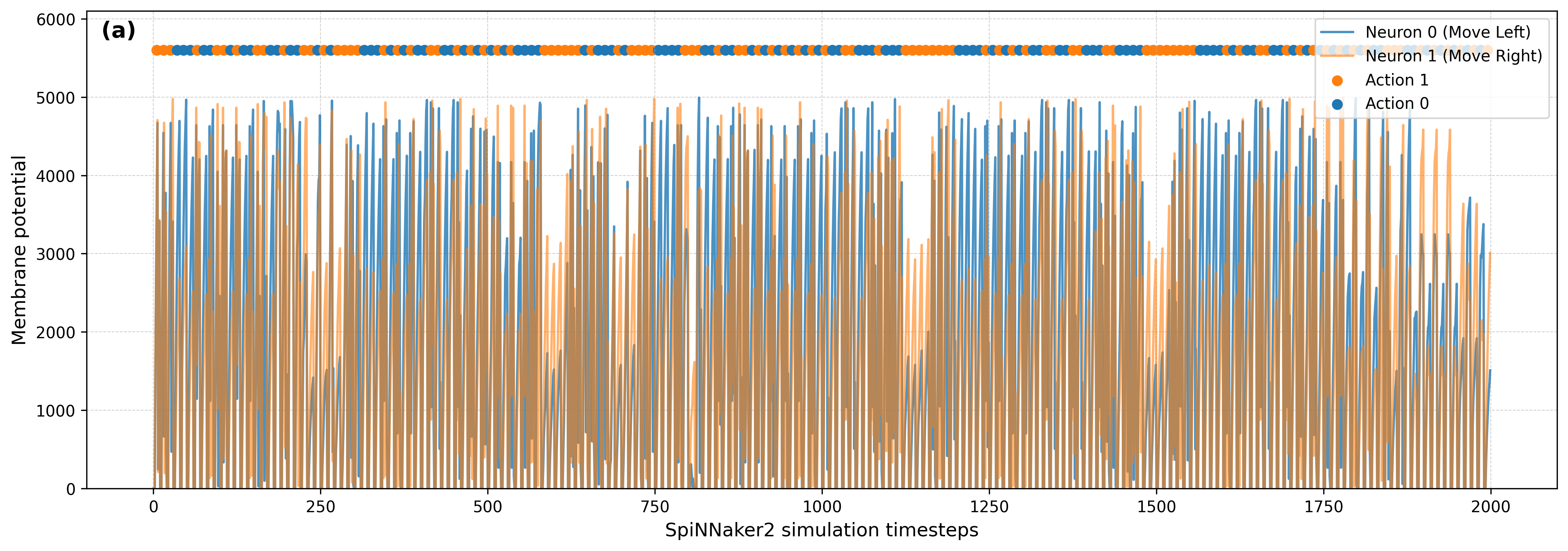
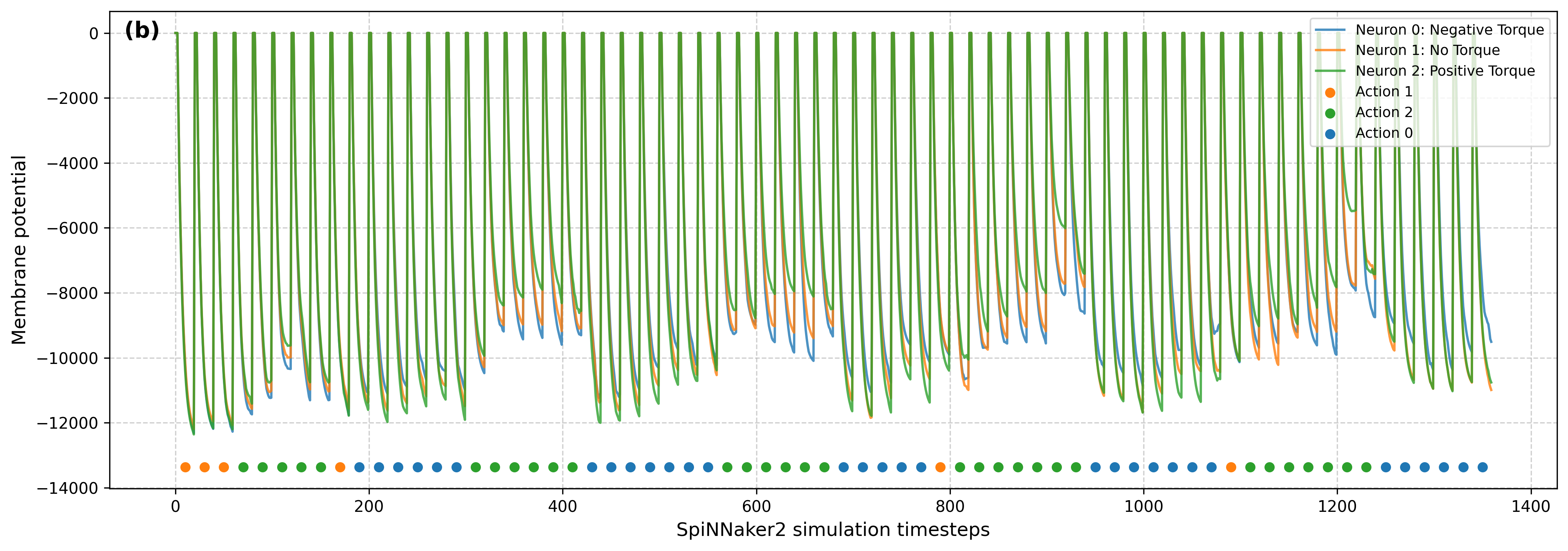
Figure 3: Voltage dynamics in CartPole-v0 and Acrobot-v1 recorded for one episode on SpiNNaker2.
Results
Quantization strategy ablation confirmed optimal scaling factors, showing negligible performance degradation for CartPole-v0 and a slight improvement for Acrobot-v1 on SpiNNaker2. On-chip threshold sensitivity analysis highlights a sequential tuning procedure for optimal LIF thresholds.
Energy consumption benchmarks against the GTX 1650 GPU demonstrated substantial efficiency gains, with up to 32× reduction in energy usage on SpiNNaker2. Comparative latency and power metrics align with real-time control needs, indicating neuromorphic platforms are viable for efficient deep RL.
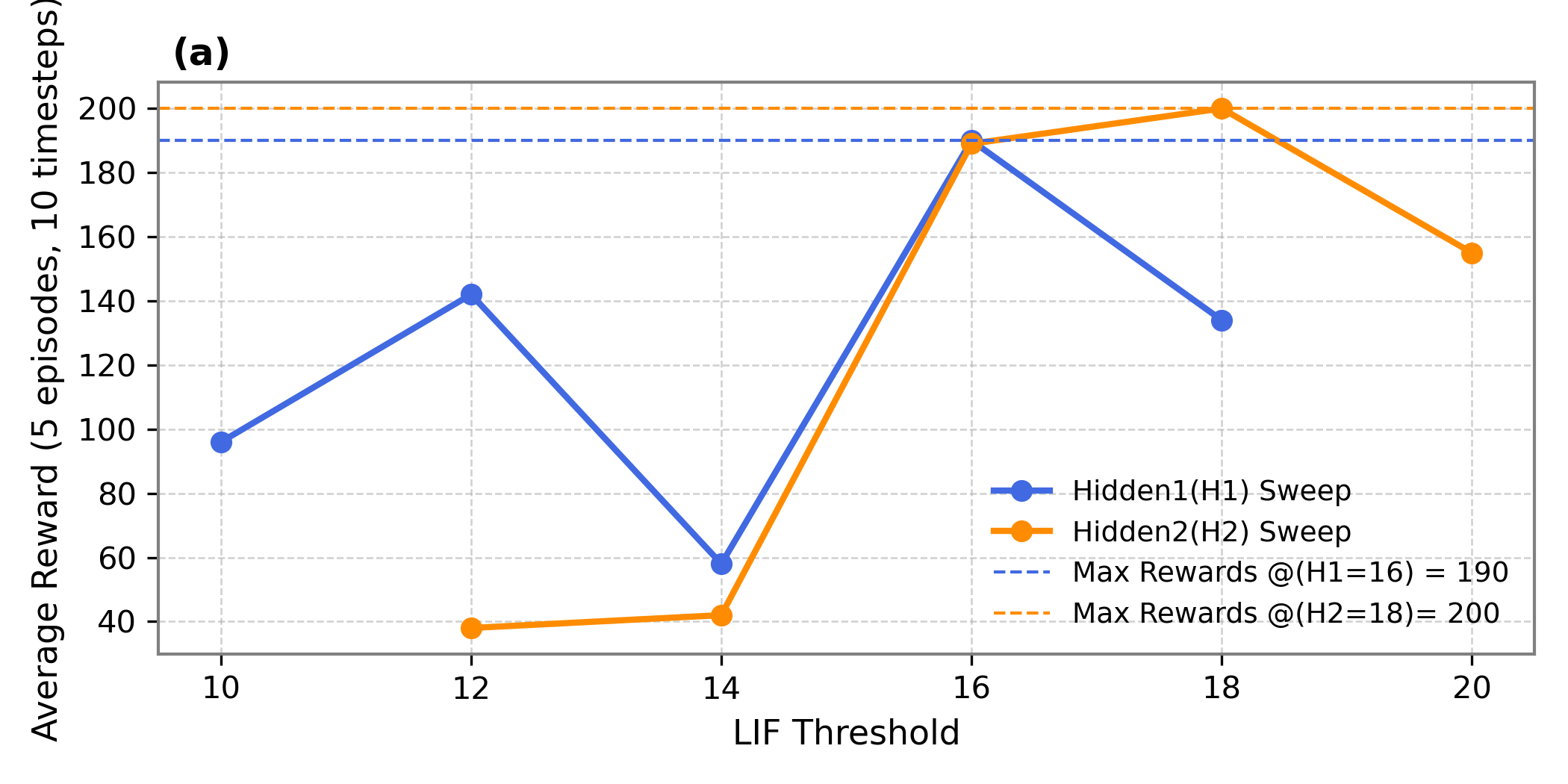
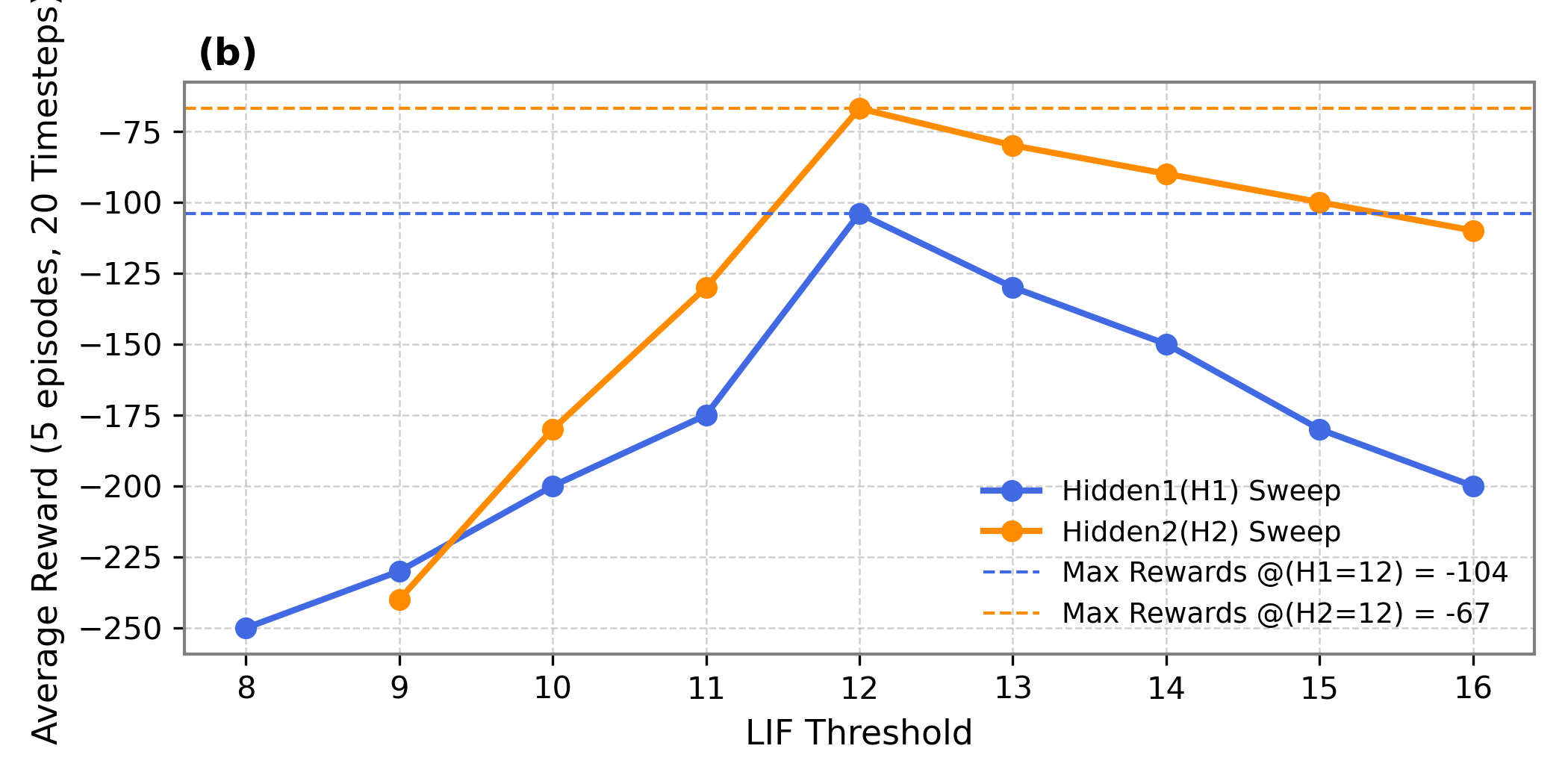
Figure 4: Average rewards over 5 episodes for various hidden layer thresholds.
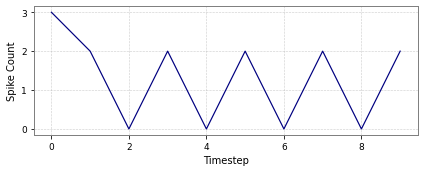
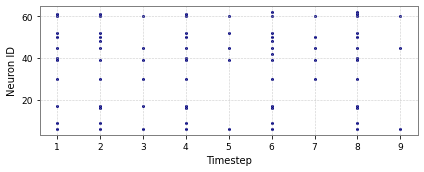
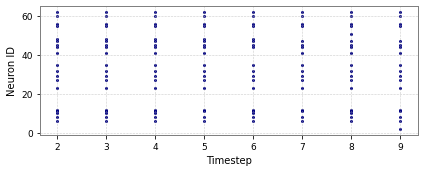
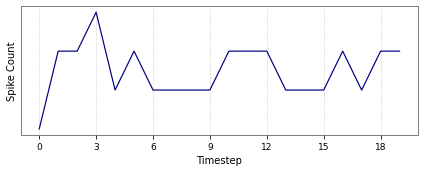
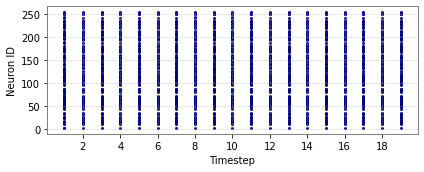
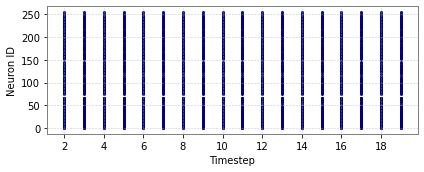
Figure 5: Spike activity for CartPole-v0 and Acrobot-v1 across input and hidden layers.
Discussion and Conclusion
The research successfully integrates deep RL with SNNs, deploying quantized DSQN models on the SpiNNaker2 chip, preserving task performance and achieving energy-efficient real-time closed-loop execution. The findings suggest SpiNNaker2 as a promising neuromorphic platform for deploying intelligent agents in energy-constrained environments, such as mobile robots and IoT devices.
Future work will investigate in-loop training and broader applications, enhancing the scalability and real-world deployment potential of neuromorphic RL systems. This approach contributes to developing intelligent systems capable of operating efficiently under stringent resource constraints.

