- The paper presents a novel DLELP framework that uses dual knowledge graphs, combining prerequisite and similarity relationships for effective learning path recommendations.
- The methodology leverages generative LLM-based text refinement and GraphRAG to construct comprehensive KC structure graphs even in datasets lacking expert annotations.
- Multi-agent reinforcement learning, featuring P-Agent, S-Agent, and D-Agent, optimizes personalized learning paths and demonstrates significant performance gains over SOTA methods.
Dual Knowledge Structure Graphs and Discrimination Learning for Personalized Learning Path Recommendation
Motivation and Problem Setting
Personalized learning path recommendation (LPR) aims to sequence educational content to optimize individual learner mastery efficiently. Traditional methods predominantly rely on knowledge concept (KC) prerequisite relationship graphs supplied by domain experts. However, most real-world educational datasets lack explicit or complete prerequisite graphs, rendering prior LPR algorithms either inapplicable or suboptimal. Moreover, exclusive dependence on prerequisite relationships often leads to the "blocked phenomenon," where learners become impeded due to confusion among similar KCs—an effect well-documented in cognitive science as a failure of discrimination learning. Addressing both sparse KC structure graphs and the need for discrimination learning is critical for advancing adaptive LPR systems.
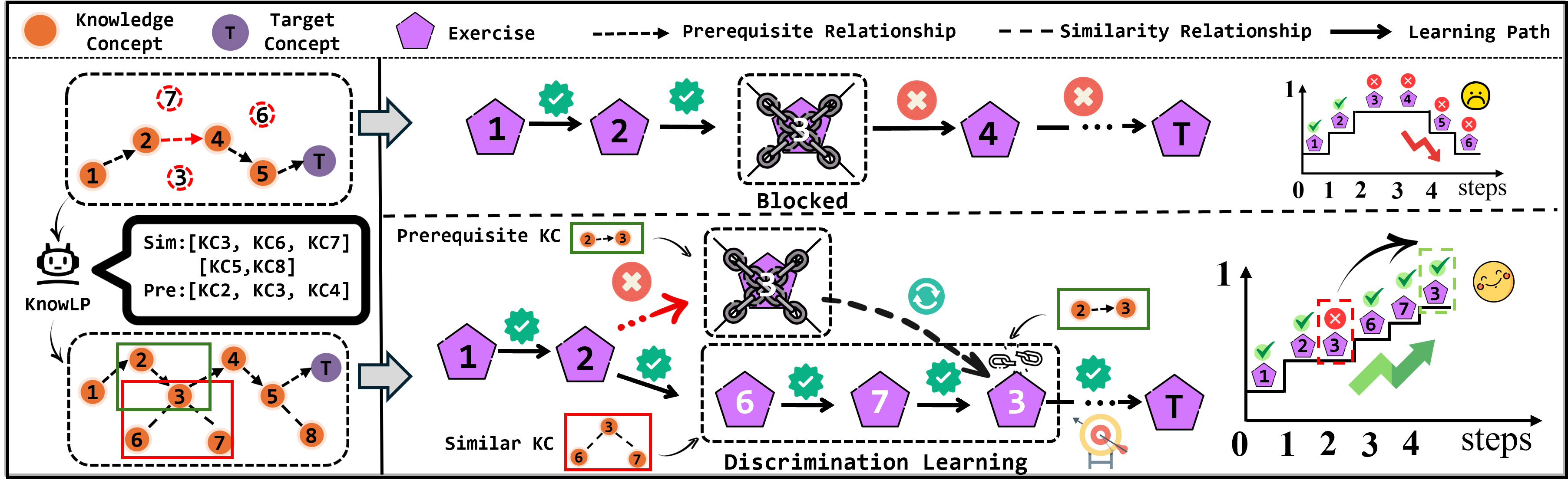
Figure 1: Comparison between traditional prerequisite-only methods (top) and the proposed KnowLP approach incorporating similarity-based discrimination learning (bottom).
Methodological Advances
KC Structure Graph Generation Using TextGrad and GraphRAG
The proposed framework, DLELP, begins by constructing comprehensive KC structure graphs comprising both prerequisite and similarity relationships. Since most educational datasets lack detailed KC descriptions, generative LLMs are used to generate explanatory texts for each KC. To mitigate LLM hallucination and ensure high-fidelity knowledge extraction, TextGrad—a prompt-based output refinement method—is deployed iteratively, filtering and upgrading explanations through LLM self-critique cycles.
Subsequently, the EDU-GraphRAG module, a domain-adapted version of the GraphRAG framework, parses the refined KC texts to extract both prerequisite and similarity relationships via entity/relation extraction and community-level graph summarization. This process ensures coverage and density in the resulting KC structure graphs even for datasets lacking any initial structure. The methodology yields dual knowledge graphs that encode both hierarchical (prerequisite) and associative (similarity) structure.
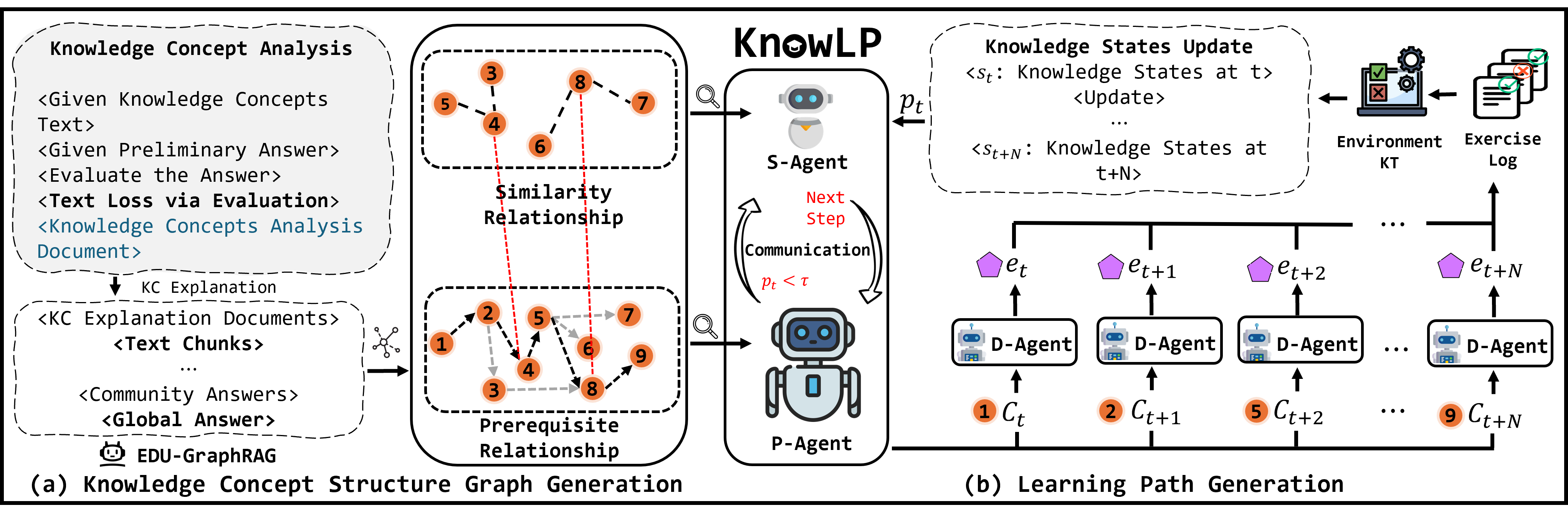
Figure 2: Overview of the KnowLP framework showing dual graph generation (left) and sequential path generation via multi-agent RL (right).
Reinforcement Learning for Learning Path Recommendation
DLELP frames learning path generation as a sequential decision-making problem in a personalized environment. The key design is a tri-agent RL architecture:
- Prerequisite Agent (P-Agent): Generates core learning sequences adhering to prerequisite constraints using Proximal Policy Optimization (PPO). The action space is dynamically pruned to feasible paths via a backward traversal that identifies optimal initial KCs, thus reducing sample complexity and mitigating local minima.
- Similarity Agent (S-Agent): Triggered when mastery improvement over sequential KC recommendations falls below a tunable threshold τ. The agent then injects sequences of similar KCs into the path to promote discrimination learning, leveraging the similarity subgraph.
- Difficulty Agent (D-Agent): Matches each KC recommendation to available exercises by aligning item difficulty (modeled via embedding) with learner current mastery, as tracked by a Difficulty-Integrated Knowledge Tracing (DIMKT) model.
At each decision stage, the composite state vector incorporates historical learner performance, current knowledge estimates, and learning goals, and each agent selects actions according to domain-adaptive policies. Reward signals are computed based on the delta in predicted mastery, maximizing the normalized gain over a session.

Figure 3: Example explanation sequence for a recommended learning path, illustrating stepwise agent decisions and rationales.
Empirical Analysis
Graph Generation and Structure Comparison
DLELP demonstrates substantial improvements in the density and coverage of generated KC structure graphs compared to expert-provided graphs. On the Junyi and MOOCCubeX datasets, the generated graphs capture more KCs and richer (albeit denser) prerequisite relations, and avoid the pitfalls of erroneously incomplete or overly dense baseline graphs present in public datasets.
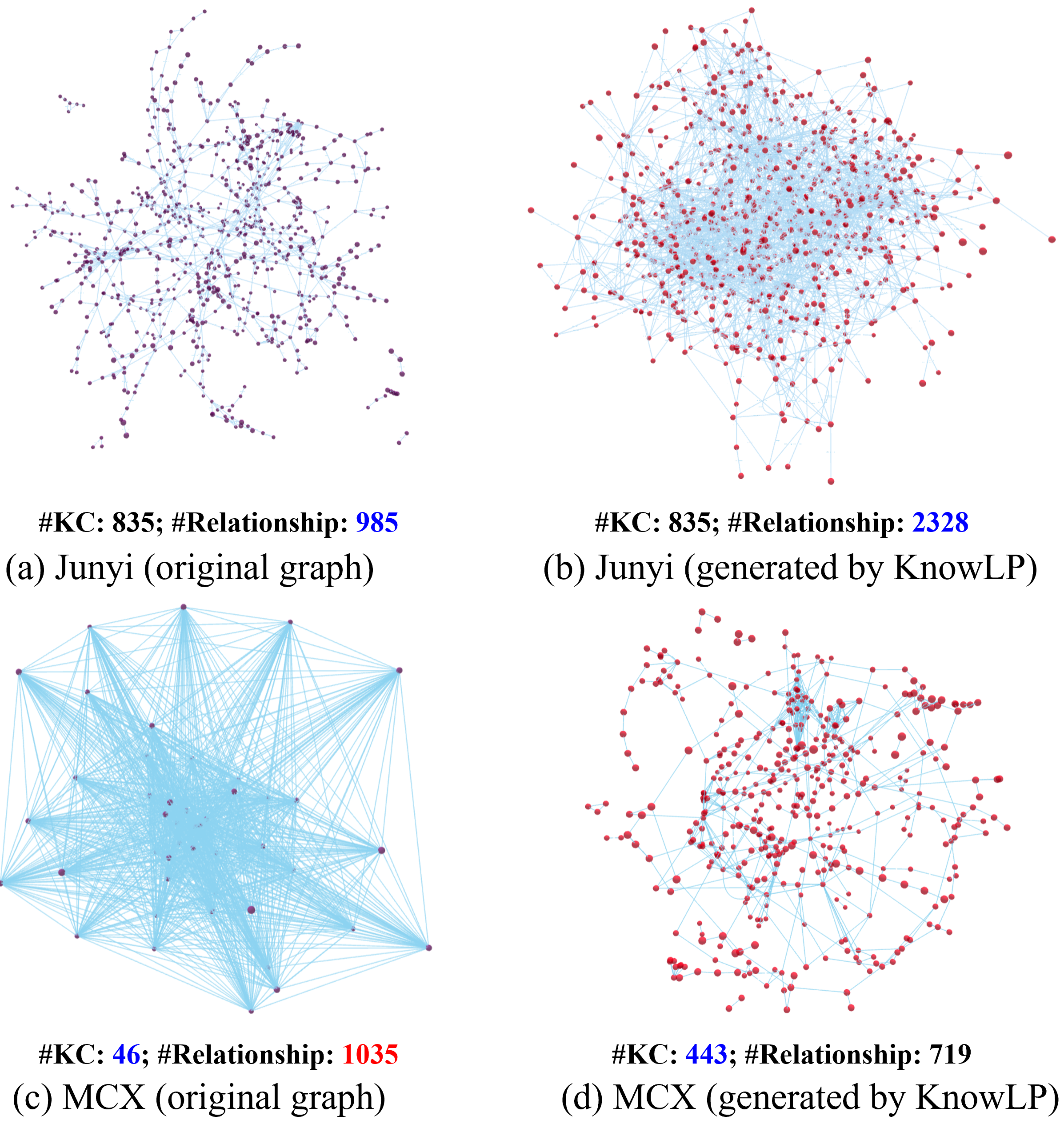
Figure 4: Comparison between original and KnowLP-generated KC structure graphs, quantifying node and edge counts.
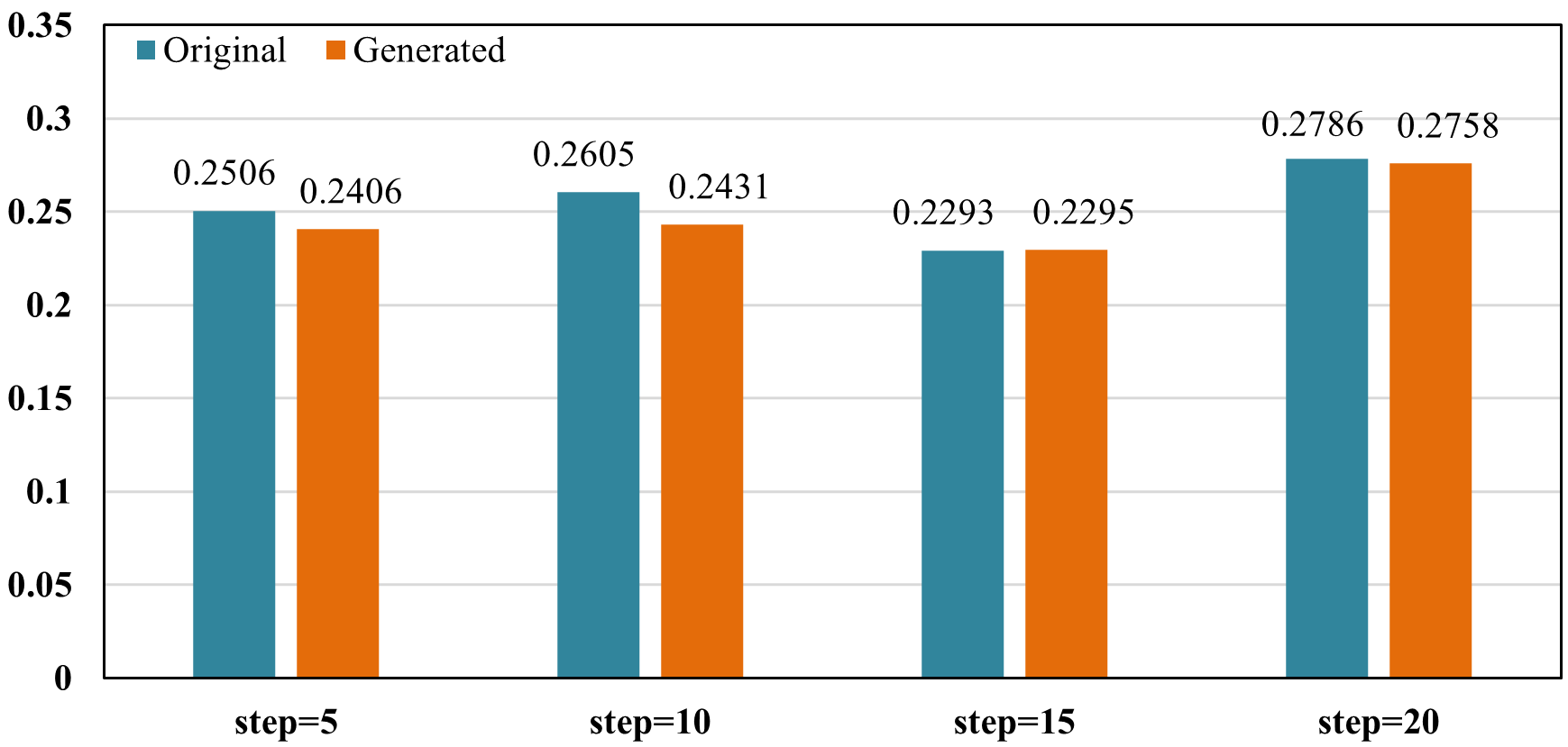
Figure 5: Downstream performance comparison using ground-truth vs. generated structure graphs; KnowLP graphs consistently enable superior or at least parity LPR quality.
Ablation and Simulation Studies
Systematic ablation of the S-Agent reveals significant performance degradation without discrimination learning, confirming the theoretical hypothesis that similarity-driven interventions are essential to avoiding blocked progression, particularly for long learning sequences (step=20).
In simulation experiments using knowledge evolution simulators (KES), DLELP outperforms prior SOTA models (e.g., SRC, GEHRL, DLPR), exhibiting robustness under dynamic learner behavior and unseen exercise sequences.
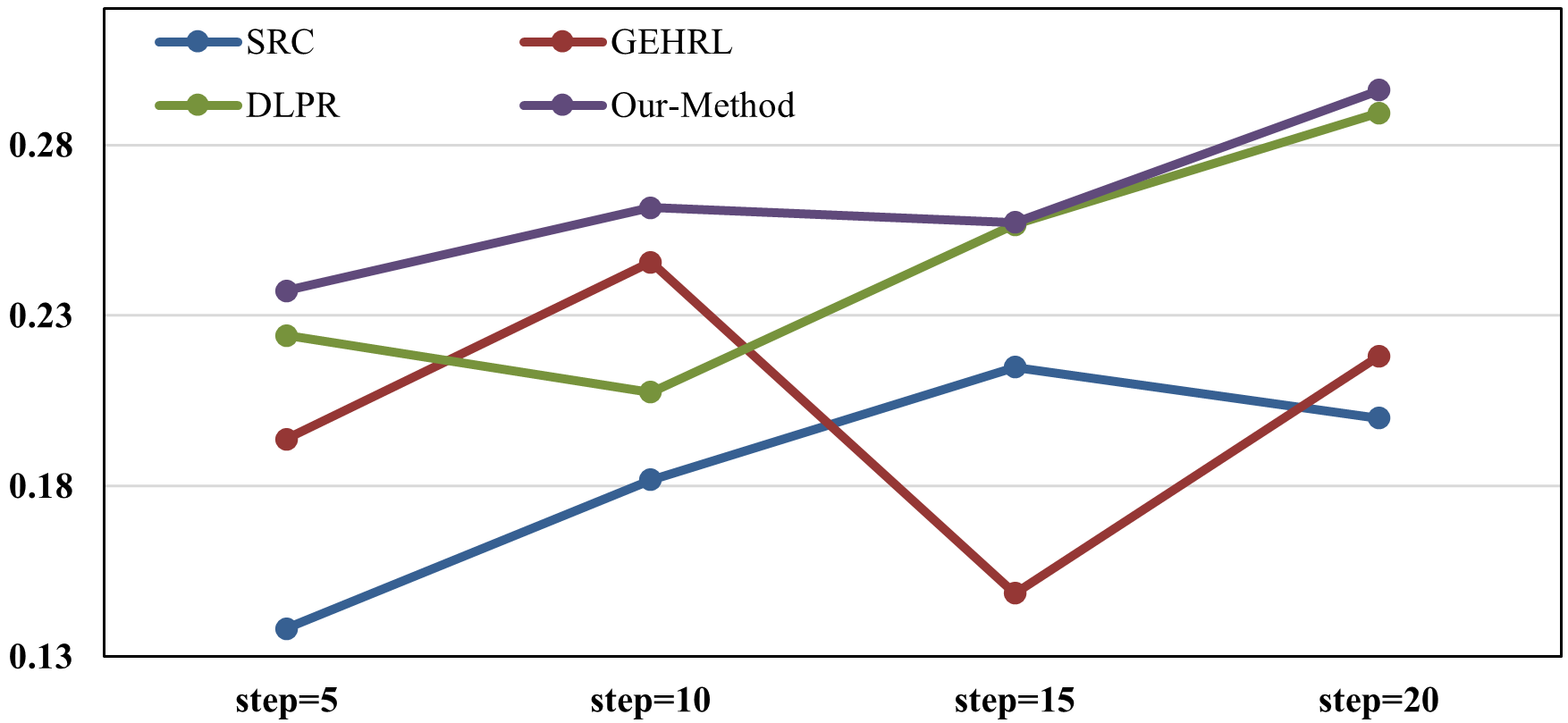
Figure 6: Learning outcome improvements in simulated online education scenario, comparing advanced LPR methods on KES-generated behavioral data.
Interpretation and Explainability
EDU-GraphRAG also produces community-level summaries supporting path-level explainability. For each recommended path, the underlying KC dependencies and similarity-based discriminations are made explicit, enhancing interpretability for stakeholders and facilitating trust in automated recommendations.
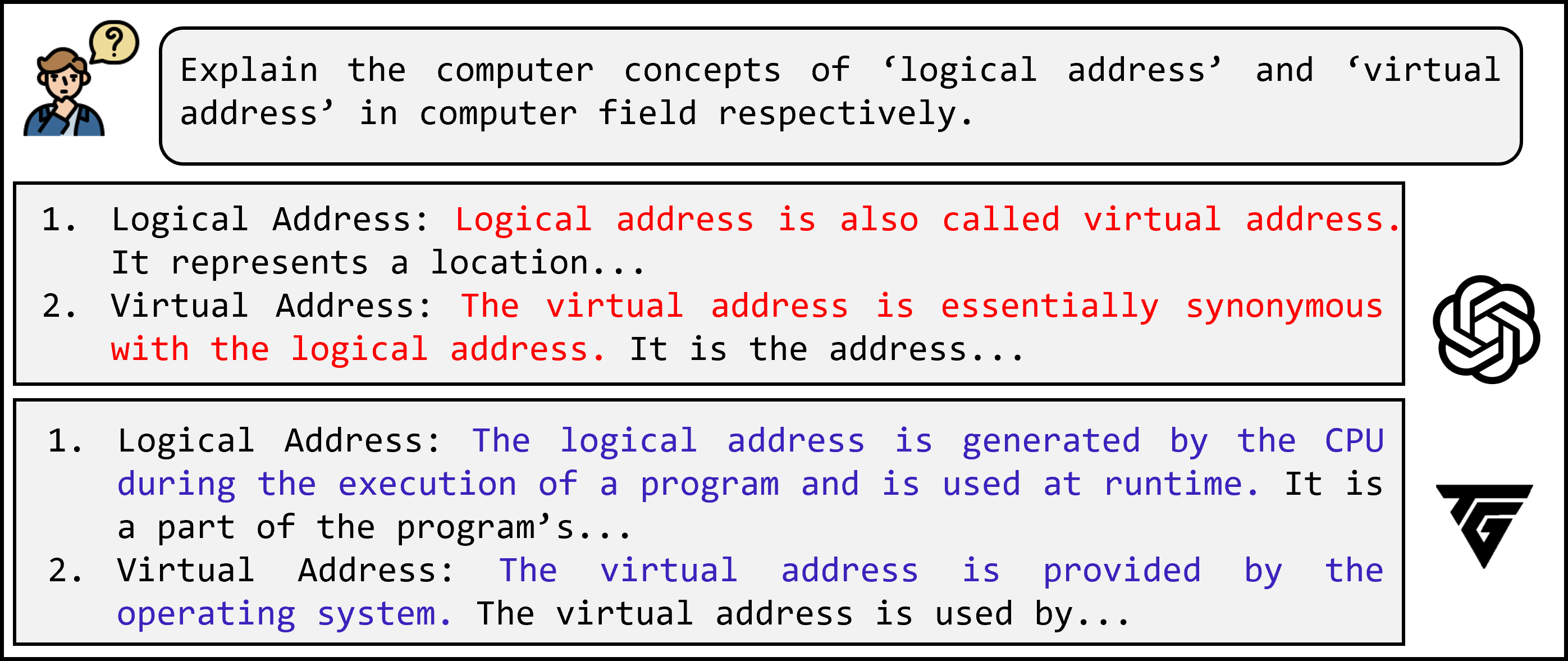
Figure 7: Impact of applying TextGrad; post-TextGrad explanations effectively separate closely related KCs, reducing confusion in both graph induction and downstream recommendations.
Quantitative Results
DLELP achieves statistically significant performance gains in normalized learning objective improvement (Ep) across three benchmarks (Junyi, MOOCCubeX, ASSIST09), consistently outperforming KC correlation-based, vanilla RL-based, and advanced hierarchical RL (HRL) LPR algorithms. The improvement margin is pronounced for longer path recommendations and in scenarios with incomplete or absent structure graphs.
Notably, removal of the similarity agent results in a 20–60% drop in efficacy across all settings, and DLELP-generated structure graphs maintain or even slightly exceed the performance of manually annotated expert graphs.
Theoretical and Practical Implications
This work demonstrates a paradigm shift from single-structure LPR (prerequisites only) to dual-structure approaches encoding both prerequisite and similarity relations. The empirical findings validate cognitive science theory that interleaved discrimination learning between similar concepts is essential for robust knowledge transfer, especially in complex domains with high concept overlap. The framework's reliance on scalable LLM-based explanation generation and retrieval-augmented graph induction paves the way for fully automated LPR in domains lacking any prior structure or exhaustive expert annotation.
Practically, this approach generalizes to any context where item structures are latent and concept similarity impedes or accelerates mastery. Applications extend beyond education to adaptive training, content curation, and skill acquisition pipelines in enterprise and industrial settings.
Future Research Directions
Prospects for continued research include:
- Refinement of similarity metrics and more sophisticated adaptive thresholds τ for triggering discrimination interventions.
- Integration with multimodal knowledge tracing (e.g., video, audio KCs).
- Exploration of meta-learning for agent policy transfer across domains or cohorts.
- Deployment in large-scale MOOCs with real-time learner feedback and human-in-the-loop explainability.
Conclusion
The DLELP framework establishes a new standard for personalized LPR by synthesizing automated dual-structure KC graph induction, discrimination learning, and multi-agent reinforcement learning in a unified, explainable pipeline. Empirical evidence underscores its effectiveness and extensibility, addressing longstanding data and modeling gaps in adaptive educational systems.

