- The paper introduces ToSA, which integrates spatial awareness via depth tokens to improve token merging in Vision Transformers.
- It fuses visual and spatial score matrices using a weighted alpha parameter, enabling adaptive merging decisions across different layers.
- Experimental results show enhanced spatial coherence and performance in tasks such as counting and object existence, validating the approach.
Token Merging with Spatial Awareness: An Exploration
The paper "ToSA: Token Merging with Spatial Awareness" (2506.20066) introduces a novel approach to enhance Vision Transformers (ViT) through the integration of spatial information in token merging processes. ToSA seeks to address limitations observed in conventional token merging strategies that rely solely on visual token feature similarity, which can be insufficient, particularly in early layers where visual features are less semantically rich. This exploration outlines the methodology, implications, and potential applications of the proposed technique.
Introduction to Token Merging in ViT
Vision Transformers like ViT have become prominent in advancing various perception tasks including classification, detection, and segmentation. Despite their success, ViTs are hampered by substantial computational demands due to their intensive attention mechanisms. Previous works have attempted to alleviate these demands through efficient architectures and token reduction techniques, ensuring that ViTs remain viable for real-time applications in fields like robotics and autonomous driving.
The core concept behind token merging is to streamline ViT processing by reducing the number of tokens, thereby preserving computational resources. Conventional methods predominantly merge tokens based on visual feature similarity, a parameter that can be unreliable in early layers due to the absence of detailed semantic information (Figure 1).

Figure 1: A merging comparison between ToMe and ToSA. By leveraging depth input, ToSA utilizes spatial awareness in the token merging process and leads to more spatially coherent merging results, helping the models to answer the question correctly. Both merging results retain 16 visual tokens for better visual comparison. Merged token is denoted by the same patch and inner edge color.
Methodology: Spatial Awareness in Token Merging
ToSA innovatively incorporates spatial awareness into the token merging process by utilizing depth maps to generate spatial tokens. These auxiliary tokens enrich the merging criteria by providing additional spatial context. The spatial tokens are derived from RGB-D inputs, capturing critical spatial structures that are frequently overlooked when relying solely on visual features.
The merging process involves calculating separate score matrices for both visual tokens and spatial tokens. These matrices are then fused using a weighted approach governed by an alpha parameter, thereby combining semantic and spatial criteria efficiently (Figure 2).
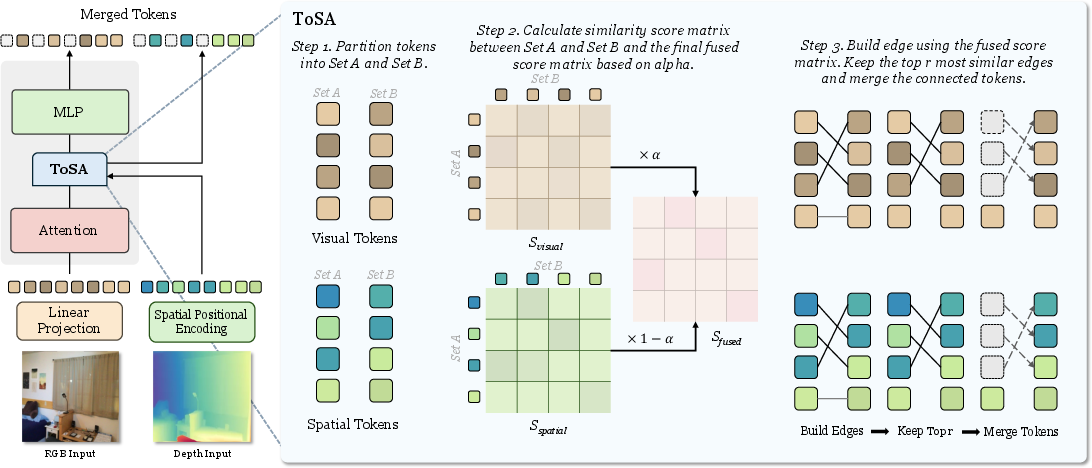
Figure 2: The overall framework of ToSA. ToSA block is inserted between attention and MLP across each encoder layer in ViT. ToSA block takes visual tokens and spatial tokens as input to conduct token merging. The merging process is based on the similarity of both visual tokens and spatial tokens.
The fusion parameter α effectively adjusts focus between visual features and spatial information across ViT layers. Initially, spatial tokens dominate the merging decision due to reduced reliability of visual tokens, whereas deeper layers gradually transition to semantic features as visual tokens mature in their semantic representations.
Experimental Results and Implications
The experimental section provides a comprehensive comparison of ToSA against existing token merging methods across various benchmarks. Results reveal ToSA's superiority in performance, particularly in tasks requiring spatial comprehension like counting and object existence, by maintaining more coherent spatial token structures (Table 1).

Figure 3: Merging results comparison between ToMe and ToSA. We only keep 16 visual tokens~(2\%) from both methods for better visual comparison. ToSA demonstrate more spatially coherent merging results, which leads to higher performance across various visual question answering benchmarks.
ToSA was evaluated on several benchmarks, including SpatialBench, VQAv2-Counting, GQA, and OpenEQA datasets, focusing heavily on spatial question types. The inclusion of spatial tokens significantly enhanced the ViT's ability to correctly interpret spatial relationships and preserved local scene structure, leading to improved question answering accuracy (Figure 3).
SpatialBench Performance:
- ToSA demonstrated robust spatial coherence in token merging compared to ToMe, contributing to enhanced performance in spatial tasks like object existence, counting, and size.
VQAv2-Counting Performance:
- ToSA reports higher accuracy and relative counting metrics compared to ToMe, validating the strength of spatial integration in token reduction strategies.
GQA Performance:
- While primarily a general visual reasoning task set, ToSA maintained superiority, showing its versatility across diverse question types.
OpenEQA Performance:
- ToSA made significant breakthroughs in handling embodied question answering, able to navigate complex 3D environments using depth-informed token merging.
Conclusion
ToSA extends the capabilities of ViTs by embedding spatial awareness into token merging strategies, unveiling new horizons in spatial reasoning tasks. It presents a low-complexity yet effective solution, enabling more practical applications in real-time scenarios. Despite minimal additional computational cost, ToSA enhances the fidelity of spatial comprehension, yielding transformative insights across numerous visual task domains.
The paper's methodology could be pivotal in advancing real-world ViT applications, notably in domains where efficient processing and high spatial accuracy are quintessential, like autonomous systems and interactive robotics. Future research could explore even broader aspects of spatial reasoning, potentially integrating dynamic environments and altering spatial criteria dynamically to adapt to various real-time stimuli.