Is your batch size the problem? Revisiting the Adam-SGD gap in language modeling
Published 14 Jun 2025 in cs.LG and math.OC | (2506.12543v1)
Abstract: Adam is known to perform significantly better than Stochastic Gradient Descent (SGD) in LLMs, a phenomenon for which a number of explanations have been proposed. In this work, we revisit this "optimizer gap" through a series of comprehensively tuned baseline training runs for language modeling with Transformers. We exhaustively study how momentum, gradient clipping, and batch size affect the gap between SGD and Adam. Our empirical findings show that SGD with momentum can actually perform similarly to Adam in small-batch settings, if tuned correctly. We revisit existing explanations for Adam's advantage, including heavy-tailed class imbalance, directional sharpness, and Hessian heterogeneity, which struggle to directly explain this phenomenon. Towards bridging this gap in our understanding, by analyzing our Transformer training runs and simple quadratic settings inspired by the literature, we provide new insights, driven by stochastic differential equation models, into the role of batch size on the training dynamics.
The paper demonstrates that SGD, when carefully tuned with small batch sizes, achieves performance comparable to Adam in language model training.
It re-evaluates common explanations like heavy-tailed class imbalance and Hessian heterogeneity, revealing that batch size is a critical factor in optimizer performance.
Empirical experiments and SDE-based theoretical insights highlight that SGD’s update direction challenges are mitigated in small-batch regimes.
Batch Size and the Adam-SGD Performance Gap in Language Modeling
This essay summarizes "Is your batch size the problem? Revisiting the Adam-SGD gap in language modeling" (2506.12543). The paper investigates the performance disparity between Adam and SGD in training Transformer-based LLMs. It challenges the prevailing notion that Adam inherently outperforms SGD by demonstrating that SGD, when appropriately tuned, can achieve comparable performance to Adam, particularly in small-batch settings. The paper re-evaluates existing explanations for Adam's superiority, like heavy-tailed class imbalance and Hessian heterogeneity, and provides new insights into the role of batch size in training dynamics, using stochastic differential equation (SDE) models.
Experimental Setup and Findings
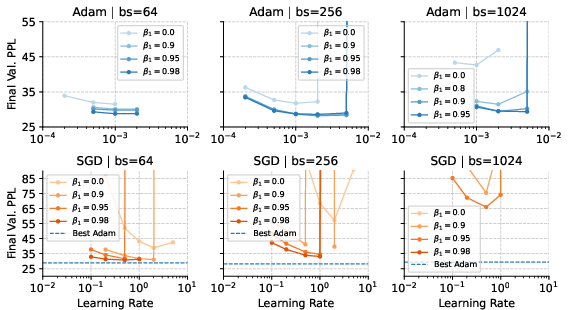
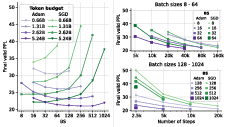
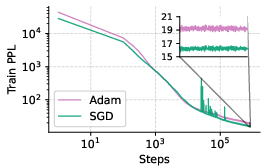
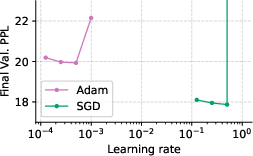
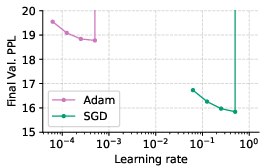
The authors conduct a comprehensive empirical study using a 160M-parameter nanoGPT model trained on the SlimPajama dataset. They vary batch sizes, momentum, and gradient clipping to assess their impact on the Adam-SGD gap. The key finding is that SGD can match Adam's performance at the same token budget if the batch size is sufficiently small and hyperparameters are carefully tuned (Figure 1). This result holds even at a scale of 1B parameters. The authors also observe that the performance gap between Adam and SGD widens as the batch size increases, suggesting that SGD struggles with larger batches. Clipping gradients is more frequent when training with large batch sizes using SGD (Figure 2).
Figure 1: Learning rate and momentum sweep for SGD and Adam across batch sizes under a fixed compute budget of 1.3B tokens.
Figure 2: SGD (green) and Adam (purple) performance across batch sizes, showing the gap increasing with batch size for a fixed token budget and decreasing with the number of steps for a fixed number of steps.
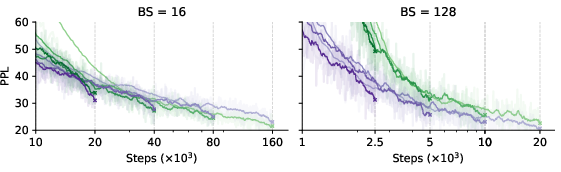
To further investigate whether the problem lies in large batch sizes or the number of steps, the authors compare performance under two training regimes: fixed token budget and fixed number of steps. They find that Adam improves with larger batch sizes under a fixed token budget, while SGD's performance degrades. However, with a fixed number of steps, SGD improves significantly with more steps and can eventually match or outperform Adam, given a sufficiently small batch size (Figure 3).
Figure 3: Perplexity during training for SGD (green) and Adam (purple) across different training lengths in small- and large-batch settings, highlighting the decreasing gap with longer training.
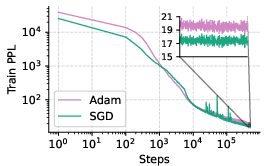
The study extends its findings to larger models (250M, 410M, and 1B parameters) and the FineWeb dataset. Training trajectories for 410M and 1B models demonstrate that SGD can outperform Adam even at these scales in small-batch regimes (Figures 4 and 9).
Figure 4: Training trajectory of a 410M model on SlimPajama, showing SGD outperforming Adam in a small-batch regime.
Figure 5: 410M model on SlimPajama (seq. length 2048, batch size 8, 500k steps).
Revisiting Prior Explanations
The authors revisit several existing explanations for Adam's advantage, including heavy-tailed class imbalance, directional sharpness, and Hessian heterogeneity. They find that while these explanations offer insights into scenarios where Adam outperforms SGD, they do not fully account for SGD's strong performance in small-batch settings.
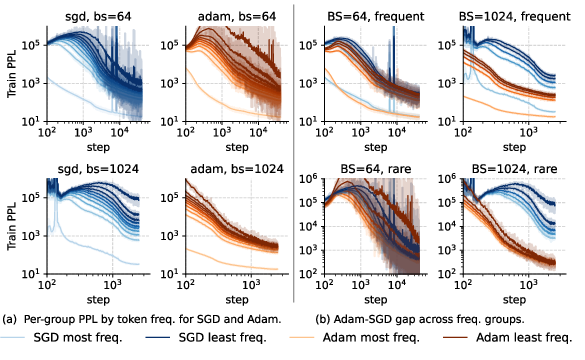
Regarding heavy-tailed class imbalance, the authors observe that while class imbalance exists in both small and large batch settings, it does not necessarily lead to an Adam-SGD gap in all training regimes. Perplexity is computed separately for each frequency group, with SGD showing a larger gap across groups in the large-batch setting, whereas the opposite holds for Adam (Figure 6).
Figure 6: Perplexity during training for Adam and SGD in small- and large-batch settings, computed per frequency group, showing a larger gap across groups for SGD in large batches.
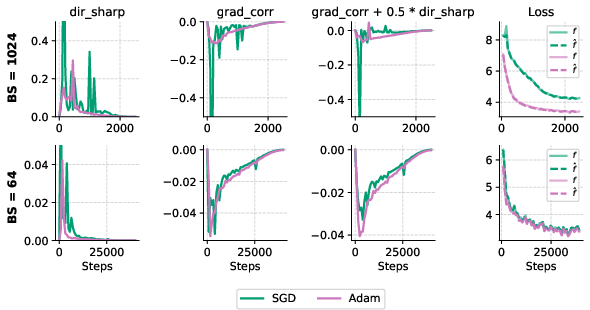
Analyzing directional sharpness, the authors visualize gradient correlation, directional sharpness, and their sum (a second-order approximation of loss change). In the large-batch setting, SGD exhibits low gradient correlation and high directional sharpness. However, when SGD succeeds in small-batch settings, its gradient correlation and directional sharpness closely match Adam's (Figure 7).
Figure 7: Gradient correlation, directional sharpness, and their sum during training under small- and large-batch settings, indicating that good training trajectories have strong negative gradient correlation and low directional sharpness.
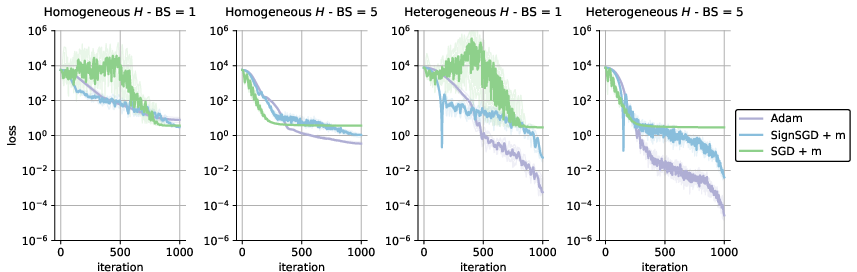
The authors also revisit the simplified quadratic setting from "Why Transformers Need Adam: A Hessian Perspective" (Zhang et al., 2024), comparing optimization on problems with homogeneous and heterogeneous Hessians. They observe that the largest Adam-SGD gap occurs in the heterogeneous setting, but Adam benefits from increasing batch size in both settings, while SGD does not (Figure 8).
Figure 8: Performance gap between Adam and SGD relative to batch size in noisy quadratic models with heterogeneous and homogeneous Hessians.
Disentangling Update Direction and Magnitude
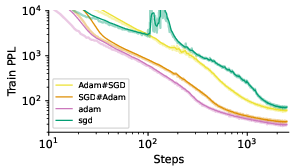
To understand what goes wrong for SGD in large-batch settings, the authors employ a grafting technique to isolate the role of update direction and magnitude. They find that using Adam's direction with SGD's magnitude results in performance closer to Adam, while the reverse combination behaves similarly to SGD (Figure 9). This suggests that the update direction is the more problematic component of the SGD update in large-batch training.
Figure 9: Grafting in large-batch training, demonstrating that using Adam's direction results in performance closer to Adam.
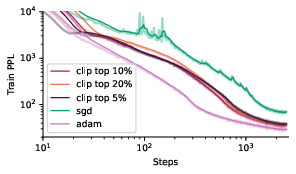
Additionally, the authors experiment with adaptive clipping, clipping the top p% of the largest momentum coordinates at each step. Adaptive clipping helps reduce the gap between SGD and Adam, suggesting that a subset of larger update coordinates consistently contributes to poor update directions (Figure 9).
Theoretical Insights from SDEs
The authors provide a theoretical analysis based on SDEs to explain the observed phenomena. They demonstrate that, while SGD performance in early training is dominated by the number of iterations, the dynamics of signed momentum methods exhibit a strong dependency on batch size from the very first iterations. The local update of parameters is driven by $- \erf \left(\sqrt{\frac{B}{2} \Sigma^{-\frac{1}{2} \nabla f(X_t) \right) dt}$ in the signSGD case, while in the SGD setting, this term is simply −∇f(Xt)dt. Increasing the batch size B increases the drift in the direction of the negative gradient by B, up to a critical batch size.
Conclusion
The paper demonstrates that SGD can be competitive with Adam in training LLMs under specific conditions, particularly in small-batch settings. It challenges existing explanations for Adam's superiority and highlights the importance of considering batch size and gradient noise in future analyses. The theoretical insights based on SDEs provide a potential explanation for the observed batch size dependency, suggesting that adaptive methods may benefit from larger batch sizes due to their ability to accelerate convergence. These findings have implications for low-resource and small-scale settings, where small batches are common and optimizer memory usage is critical.