Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
Published 23 May 2024 in cs.LG | (2405.14578v5)
Abstract: In current deep learning tasks, Adam style optimizers such as Adam, Adagrad, RMSProp, Adafactor, and Lion have been widely used as alternatives to SGD style optimizers. These optimizers typically update model parameters using the sign of gradients, resulting in more stable convergence curves. The learning rate and the batch size are the most critical hyperparameters for optimizers, which require careful tuning to enable effective convergence. Previous research has shown that the optimal learning rate increases linearly or follows similar rules with batch size for SGD style optimizers. However, this conclusion is not applicable to Adam style optimizers. In this paper, we elucidate the connection between optimal learning rates and batch sizes for Adam style optimizers through both theoretical analysis and extensive experiments. First, we raise the scaling law between batch sizes and optimal learning rates in the sign of gradient case, in which we prove that the optimal learning rate first rises and then falls as the batch size increases. Moreover, the peak value of the surge will gradually move toward the larger batch size as training progresses. Second, we conducted experiments on various CV and NLP tasks and verified the correctness of the scaling law.
The paper demonstrates that the optimal learning rate surges and then declines with increasing batch size, challenging the traditional linear scaling assumption.
It employs rigorous theoretical analysis and experiments on CNNs, ResNet, and Transformer models to validate the nuanced scaling law.
The findings imply that dynamically adjusting learning rates and batch sizes can significantly enhance training efficiency in distributed deep learning.
Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
Introduction
The paper "Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling" explores the intricate interplay between learning rates and batch sizes within the field of Adam-style optimizers, a class comprising optimizers such as Adam, RMSprop, and Adafactor. These optimizers rely on the sign of gradients for parameter updates, diverging from the traditional SGD-style optimizers that utilize raw gradients. The paper challenges the prevailing notion that the optimal learning rate scales linearly with batch size, offering a nuanced theory that encompasses a surge phenomenon where the optimal learning rate first rises and then falls as batch size increases. This paper provides both theoretical insights and empirical validation across a variety of deep learning tasks, shedding light on the efficiency and convergence characteristics of these optimizers.
Theoretical Analysis
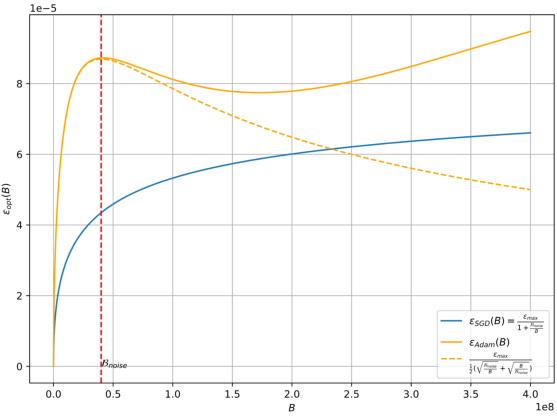
The core contribution of the paper is the derivation of a new scaling law that characterizes the relationship between optimal learning rates and batch sizes for Adam-style optimizers. The primary theoretical finding is encapsulated in the equation that describes the learning rate ϵopt(B) relative to the batch size B:
ϵopt(B)=21(BBnoise+BnoiseB)ϵmax
This relationship signifies that as the batch size increases, the optimal learning rate does not monotonically increase but instead experiences a surge, with a peak that represents a balance between training speed and data efficiency. This peak gradually shifts towards larger batch sizes as training progresses.
Figure 1: The relationship between the optimal learning rate and the batch size is different between Adam and SGD. The orange line represents the tendency of the optimal learning rate to converge to a non-zero value when the batch size is large enough.
The derivation hinges on a careful consideration of Adam-style optimizers' utilization of the sign of gradients. This behavior, contrasted with SGD's reliance on raw gradients, introduces unique scaling dynamics for the learning rate that become evident particularly in large-batch training scenarios.
Empirical Validation
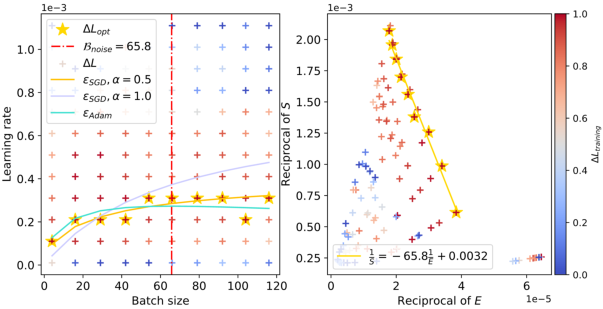
The paper's theoretical assertions are substantiated through extensive experiments on diverse tasks, including CNN training on FashionMNIST, ResNet18 on TinyImageNet, and Transformer models on the ELI5-Category dataset. These experiments consistently demonstrate a non-monotonic relationship between the optimal learning rate and batch sizes, validating the predicted surge phenomenon.
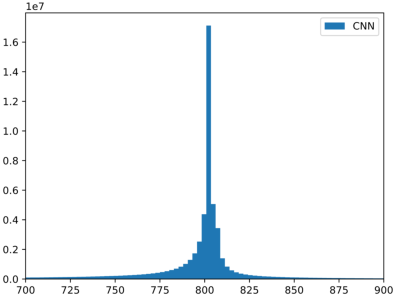
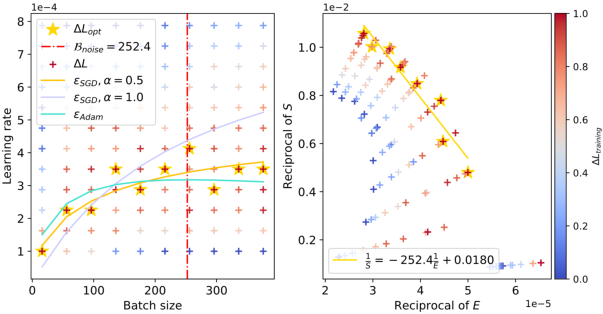
Figure 2: Batch size versus optimal learning rate within the context of CNN trained on FashionMNIST.
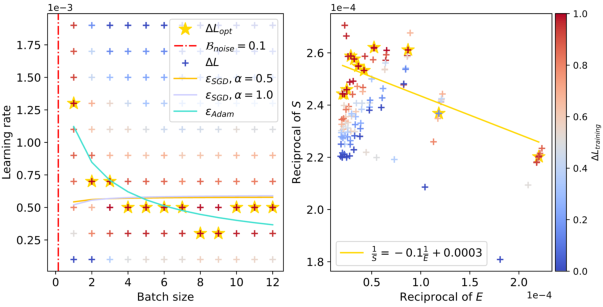
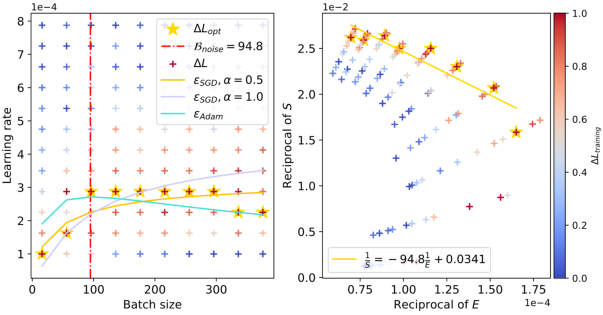
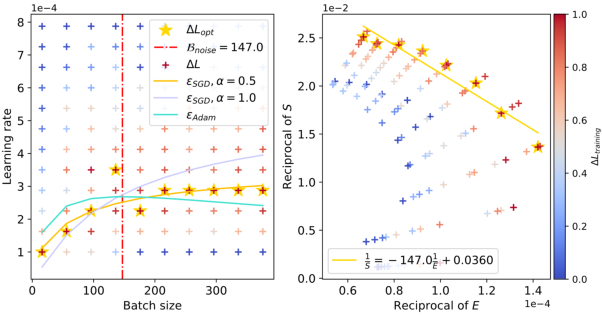
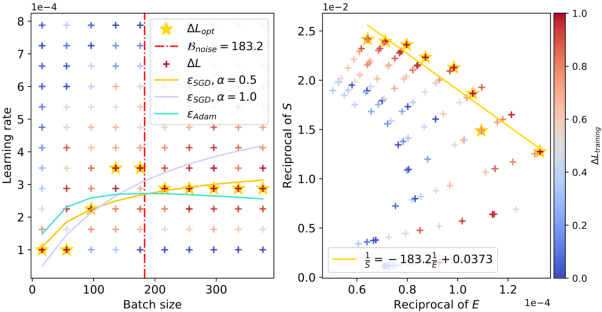
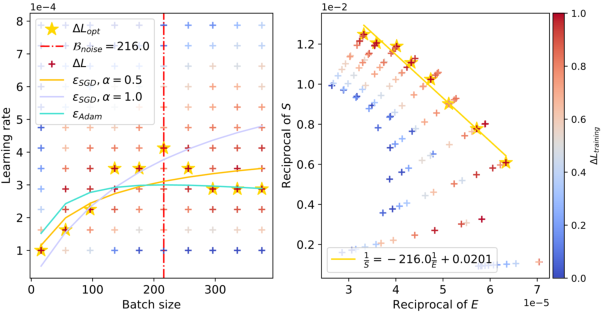
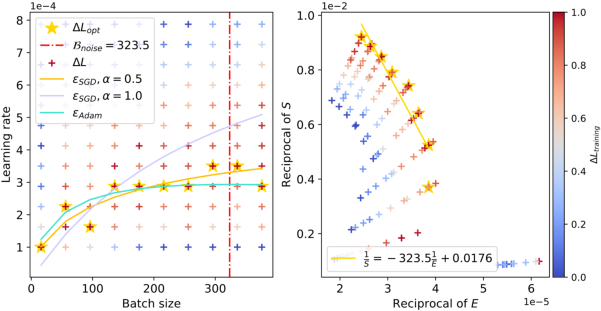
Figure 3: The relationship between batch sizes and optimal learning rates within the context of ResNet-18 trained on TinyImageNet. The red dashed line accurately predicts the peak value, and as the training loss decreases, the peak value gradually shifts to the right.
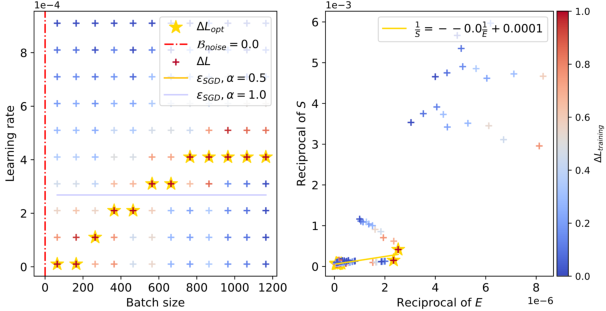
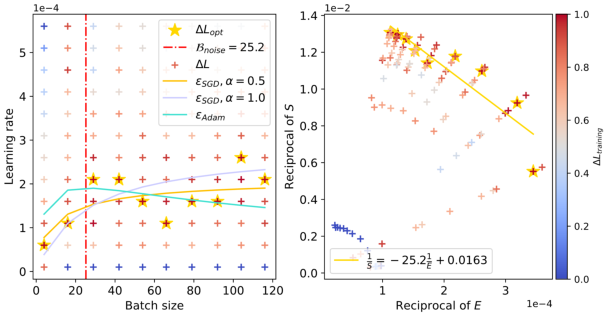
Figure 4: The relationship between batch sizes and optimal learning rates within the context of DistilGPT2 trained on Eli5Category.
The figures clearly illustrate the peak in optimal learning rate for varying configurations, and the empirical results align well with the theoretical predictions. The red dashed lines in the figures capture the estimated values of Bnoise, corresponding to the batch size where the learning rate peaks. Notably, as the training progresses and the model attains lower loss values, Bnoise, and hence the peak batch size, shifts to larger values.
Implications and Discussion
The implications of these findings extend to the strategies employed in training large-scale neural networks with Adam-style optimizers. The identification of a peak learning rate relative to batch size suggests potential avenues for improving training efficiency, such as dynamically adapting learning rates and batch sizes throughout the training process. This dynamic adjustment could enhance convergence speeds and optimize resource utilization, particularly in distributed training environments.
Moreover, this work challenges existing scaling laws predicated on SGD-like assumptions and encourages the development of adaptive optimization techniques that cater to the peculiarities of Adam-style optimizers. As deep learning models continue to scale, understanding and exploiting these scaling laws could offer significant gains in both computational efficiency and model performance.
Conclusion
The paper's exploration of the surge phenomenon in optimal learning rate scaling for Adam-style optimizers provides significant insight into the nuanced dynamics of hyperparameter interactions in deep learning. Through rigorous theoretical derivation and comprehensive experimentation, it underscores the complexity of optimization landscapes and contributes to a more refined understanding of learning rate strategies in the context of modern optimizers. Future work may leverage these insights to develop more sophisticated training algorithms that better harness the potential of large datasets and complex models in deep learning.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.