- The paper proposes DGMR, a method that prunes MLP modules using a Gram-Schmidt strategy to preserve neuron diversity.
- It achieves over 57% reduction in parameters and FLOPs on models like EVA-CLIP-E, while maintaining near-original performance.
- The approach employs effective knowledge distillation to ensure minimal performance loss in zero-shot classification and retrieval tasks.
Introduction
Transformer models have demonstrated superior scaling capability in both computer vision and NLP tasks, where enhanced performance is achieved through model enlargement. However, the increase in model size also significantly elevates the computational and memory costs, posing challenges for deployment. This paper addresses the issue by focusing on compressing the multilayer perceptron (MLP) modules within vision transformers, which constitute the bulk of the model parameters. The authors propose a Diversity-Guided MLP Reduction (DGMR) technique that employs a Gram-Schmidt pruning strategy to eliminate redundant neurons while preserving weight diversity. The pruning method requires considerably less training data to recover the original model performance when distilling knowledge. Experimental results show substantial reductions (>57%) in parameters and FLOPs with negligible performance loss, highlighting the efficiency of DGMR in compressing large vision transformers.
Methodology
Diversity-Guided MLP Reduction
The primary focus of the DGMR method is MLP module pruning, targeting parameter heavy regions within transformer architectures. By employing a Gram-Schmidt based pruning strategy, redundant weights are removed while maximizing the diversity of the remaining neurons (Figure 1).

Figure 1: We eliminate vj of neuron j from {vi}i.
The process selects important neurons by evaluating connection strengths. Neurons are chosen iteratively based on the largest ℓ2 norm, and subsequent weight updates are performed to eliminate redundant information from the remaining neurons. This ordered selection enhances neuron diversity, crucial for effective weight recovery during the distillation phase.
Knowledge Distillation
Knowledge distillation follows the pruning phase, refining the pruned model's performance by treating the uncompressed model as the teacher. Utilizing mean squared error loss for both class token and patch tokens, the distillation process effectively reteaches the compressed model (Figure 2).
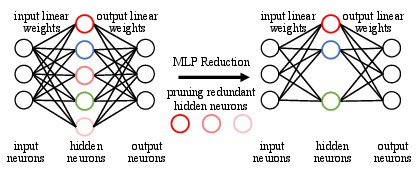
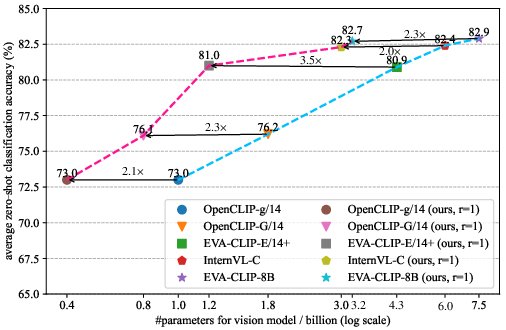
Figure 2: (a) Due to the large MLP expansion ratio of vision transformer models, there are significant redundant parameters. (b) Our method yields near lossless performance on model compression.
Experimental Results
The DGMR method was extensively tested on state-of-the-art vision transformers like EVA-CLIP-E, EVA-CLIP-8B, and DINOv2-g across various benchmarks, including image classification and retrieval tasks. For EVA-CLIP-E, the DGMR achieved a notable 71.5% reduction in parameters and FLOPs without performance degradation, a testament to its efficacy.
Zero-Shot Image Classification
Experimental results demonstrate the DGMR method’s capability to achieve negligible performance loss in zero-shot classification tasks on diverse ImageNet variants and ObjectNet. While achieving significant computational reduction (>57% reduction), the DGMR-modified models maintain comparable accuracies to their original counterparts, with notable throughput improvements.
Zero-Shot Retrieval
The DGMR pruned models also perform competitively in zero-shot text and image retrieval tasks, maintaining robust mean recall across Flickr30K and COCO datasets. Notably, adopting the text encoder led to significant improvements in retrieval metrics without sacrificing image classification performance.
DGMR builds on previous model pruning strategies focused on weight importance metrics and distillation paradigms, addressing the common oversight of neuron diversity. Unlike gradient-dependent pruning methods, DGMR improves parameter efficiency without computing-intensive iterative steps, making it highly applicable to large transformer models.
Conclusion
The Diversity-Guided MLP Reduction technique offers an effective framework for transforming large vision transformer models into compact, efficient counterparts while preserving their performance capabilities. DGMR achieves exceptional parameter and FLOPs reductions and enhances model deployability in resource-constrained environments. Future developments may explore expanding DGMR’s applicability to attention components and broader transformer applications beyond vision models.