- The paper introduces a unified framework treating RAG as noisy in-context learning and derives finite-sample generalization and risk bounds.
- It quantifies the bias-variance tradeoff under uniform and non-uniform retrieval noise while establishing optimal sample complexity conditions.
- Experimental validation on QA datasets confirms the theory by showing how additional retrieved examples can either enhance or degrade performance.
Retrieval-Augmented Generation as Noisy In-Context Learning
The paper "Retrieval-Augmented Generation as Noisy In-Context Learning: A Unified Theory and Risk Bounds" (2506.03100) introduces a theoretical framework for analyzing RAG. It provides finite-sample generalization bounds for RAG in in-context linear regression and derives a bias-variance tradeoff. By framing RAG as noisy ICL, the paper models retrieval noise and quantifies its impact on generalization. The analysis includes uniform and non-uniform noise regimes, offering insights into when additional retrieved examples improve or degrade performance.
Theoretical Framework
The paper frames RAG as noisy ICL, treating retrieved texts as query-dependent noisy in-context examples. It considers two noise regimes: uniform retrieval noise, where the noise variance is constant across examples, and non-uniform retrieval noise, where the variance is inversely correlated with retrieval relevance.
Problem Setup
The problem setup involves linear regression data with prompts of size m, represented as matrices $\PPT_{m}$. The goal is to predict y^q for a query example $\bx_q$. During inference, the test prompt $\PTTRAG_{m,n}$ includes m in-context pairs and n retrieval-augmented pairs. The paper uses a single-layer linear self-attention model (LSA) for theoretical analysis.
Key Assumptions
The analysis relies on several key assumptions:
- Gaussian Retrieval Offset: Retrieval offsets $\br_i$ follow a Gaussian distribution N(0,δi2Id).
- Data Distribution: Pretraining examples, test-time examples, and RAG examples follow specific Gaussian distributions as outlined in Assumption 2 of the paper.
- Uniform Retrieval Noise: The RAG noise $\beps_{\text{rag}$ shares the same Gaussian distribution with variance $\sigma^2_{\text{rag}$.
Generalization Bound for RAG
The paper derives a generalization bound for RAG by decomposing the population loss into variance-induced error, bias-induced error, and irreducible noise. The analysis quantifies the impact of retrieval noise and provides insights into when additional retrieved examples improve or degrade performance.
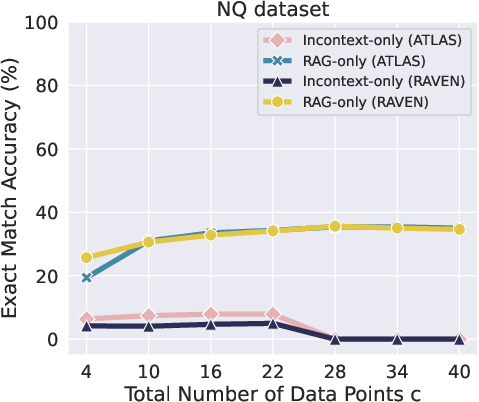
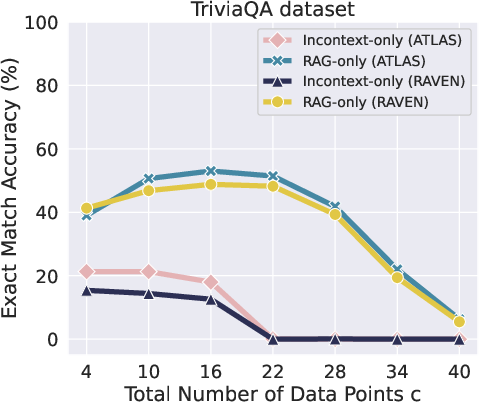
Figure 1: We compare performance between the RAG-only (c=m) versus in-context-only methods (c=n1+n2,n1=n2), where c is the total number of data, n1 refers to retrieved examples and n2 to passages.
Under uniform retrieval noise, the population loss is given by:
$\mathcal{L}_{\text{tt+rag}(\bW) = \operatorname{err}_{\text {variance}(\bW)} + \operatorname{err}_{\text{bias}(\bW)} + \sigma^2$
where
$\operatorname{err}_{\text{variance}(\bW) = \left[m\sigma^2 + \left( 1 + \delta^2\right)n\sigma_{\text{rag}^2\right]\tr(\bW^\T\bW) + n \sigma_{\text{rag}^2 \tr(\bW^2) + n\sigma_{\text{rag}^2 \tr(\bW)^2$
$\operatorname{err}_{\text{bias}(\bW) = \betatt^\T \left[I - (n \delta^2 + 2n + m) (\bW+ \bW^\T) - 2n\tr(\bW)I + M_4\right]\betatt$
The paper analyzes the finite sample complexity under the optimal pretrained weight $\bW^*$ and derives an optimal number of RAG examples n∗ for a given number of ICL examples m.
Under non-uniform retrieval noise, the paper proves sample complexity under distance-proportional noise and distance-weighted mixture noise. This analysis reveals that RAG can improve variance-induced error up to a finite n at the cost of increasing bias-induced error.
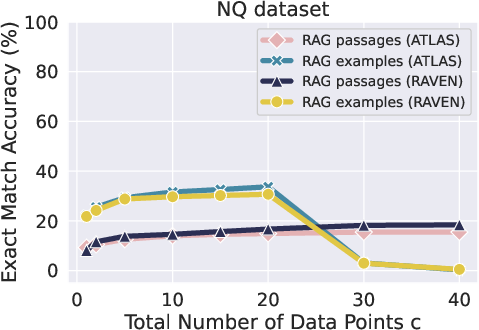
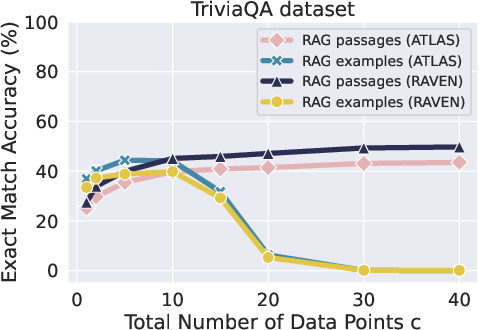
Figure 2: We compare the performance of RAG using examples (c=n1) versus passages (c=n2).
Distance-Proportional Noise (DPN)
Under DPN, the RAG noise variance grows linearly with the variance δi2 that governs the retrieval distance: σrag,i2=γ1σ2δi2. The population loss is given as:
$\hat{\err}_{\text{variance}(\bW) = m\sigma^2 \tr(\bW^\T \bW) + \sum_{i=1}^n \gamma_1 \delta_i^2 [(1+\delta_i^2) \tr(\bW^\T \bW)+ \tr(\bW^2) + \tr(\bW)^2]$
Distance-Weighted Mixture Noise
The paper also considers a scenario where further RAG examples are less likely to contain correct answers, modeled by a mixture of small and large noise.
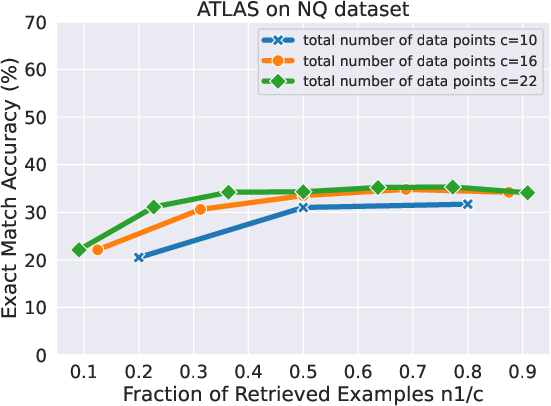
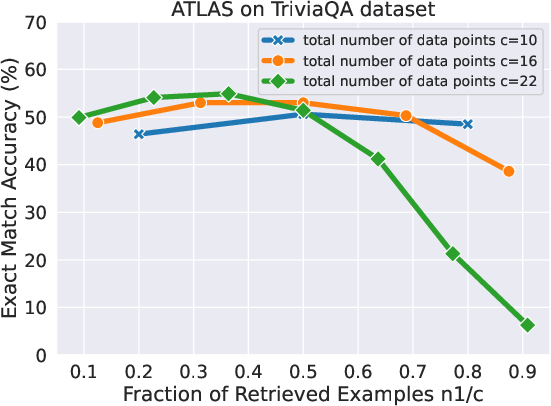
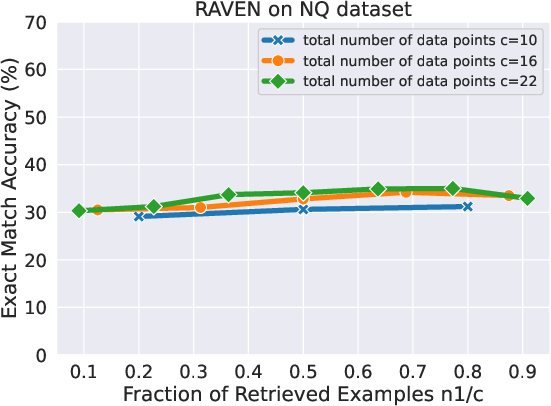
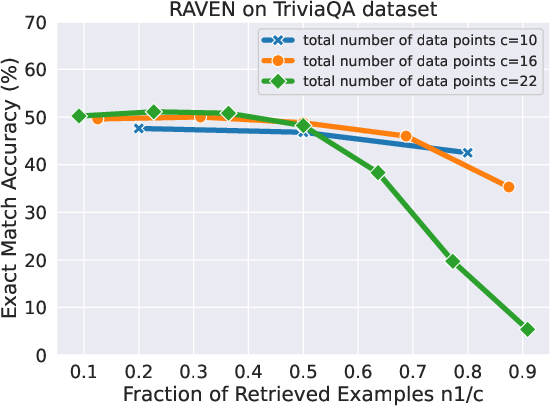
Figure 3: ATLAS Performance as a function of n1/c under different data points c on NQ.
Experimental Validation
The paper conducts experiments on question answering datasets, demonstrating that RAG data outperforms randomly sampled in-context examples. The experiments also reveal that early RAG retrieves lie in the uniform noise regime, while later ones shift to the non-uniform noise regime, aligning with the theory.
Conclusion
The paper provides a theoretical framework for understanding RAG as noisy ICL. It derives finite-sample error bounds and analyzes the impact of retrieval noise on generalization. The framework includes ICL and standard RAG as limit cases and models retrieved data under different noise regimes. Experiments on QA datasets corroborate the theoretical analysis. The findings offer guidance on when to stop adding retrieved examples in RAG to avoid performance degradation.