- The paper introduces VisTA, a novel reinforcement learning framework that autonomously selects effective visual tools based on task outcomes.
- It employs the GRPO algorithm to optimize tool combinations, significantly improving visual reasoning on benchmarks like ChartQA and Geometry3K.
- Results show that adaptive tool selection narrows performance gaps, highlighting the RL agent's ability to generalize across diverse visual tasks.
Introduction
The "VisualToolAgent (VisTA): A Reinforcement Learning Framework for Visual Tool Selection" introduces an RL framework that equips visual agents with the capability to autonomously explore, select, and integrate tools from a diverse library based on their empirical performance. This framework contrasts with traditional approaches that either involve training-free prompting or extensive fine-tuning to integrate tools, both of which limit tool diversity and exploration. VisTA leverages the GRPO algorithm to enable agents to discover and refine sophisticated tool-selection strategies without explicit supervision.
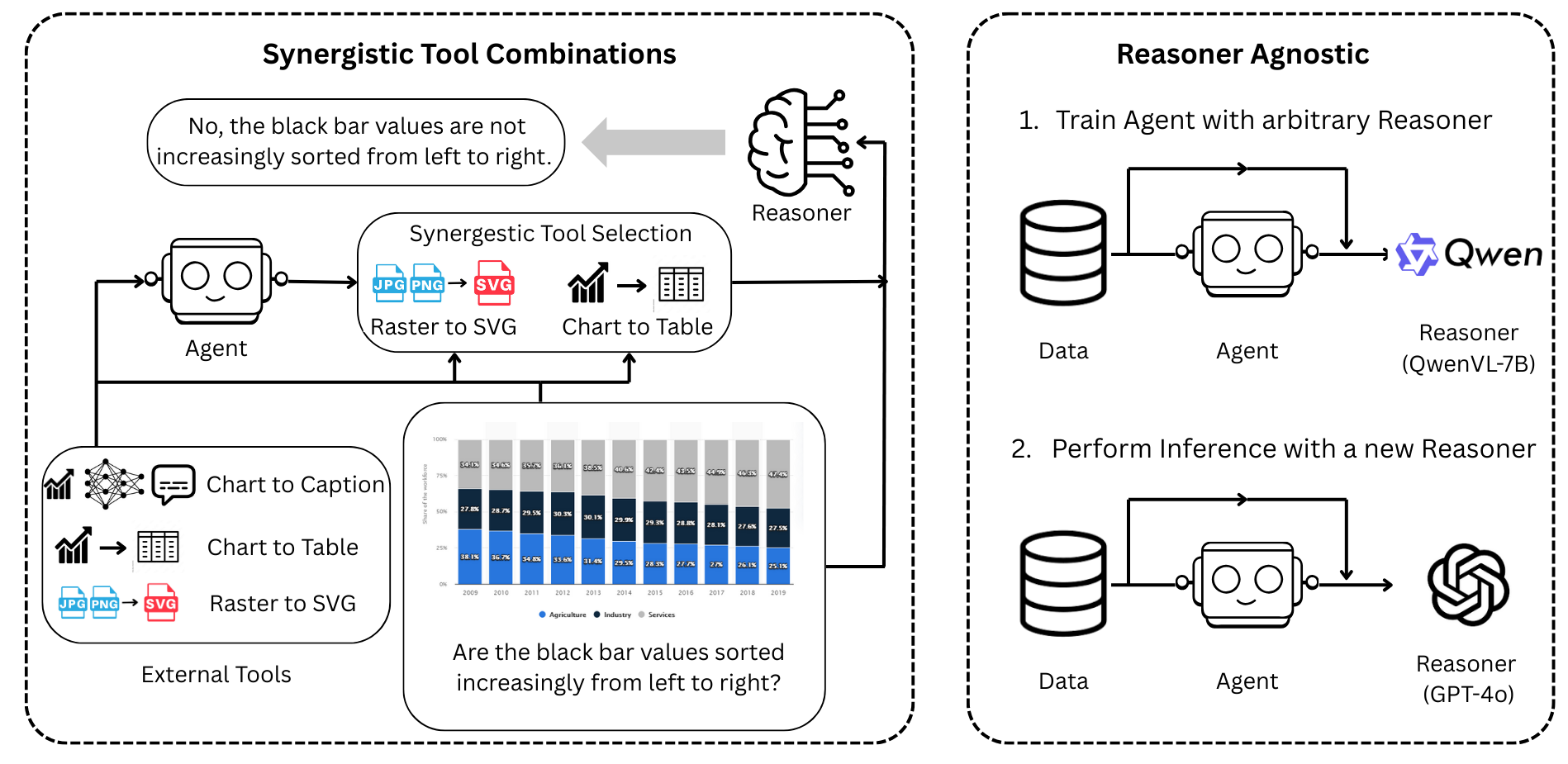
Figure 1: Overview of VisTA. (Left) Our method trains an agent to autonomously discover effective combinations of visual tools without human supervision. (Right) By decoupling the agent from the reasoner, the learned policy can be seamlessly integrated with a wide range of reasoning models.
Methodology
VisTA utilizes reinforcement learning to train an autonomous agent capable of selecting the most effective tools from a library suited to solve complex visual reasoning tasks. This RL framework is designed to maximize the reasoning model's performance by adaptively selecting tool combinations based on task outcomes as feedback signals.
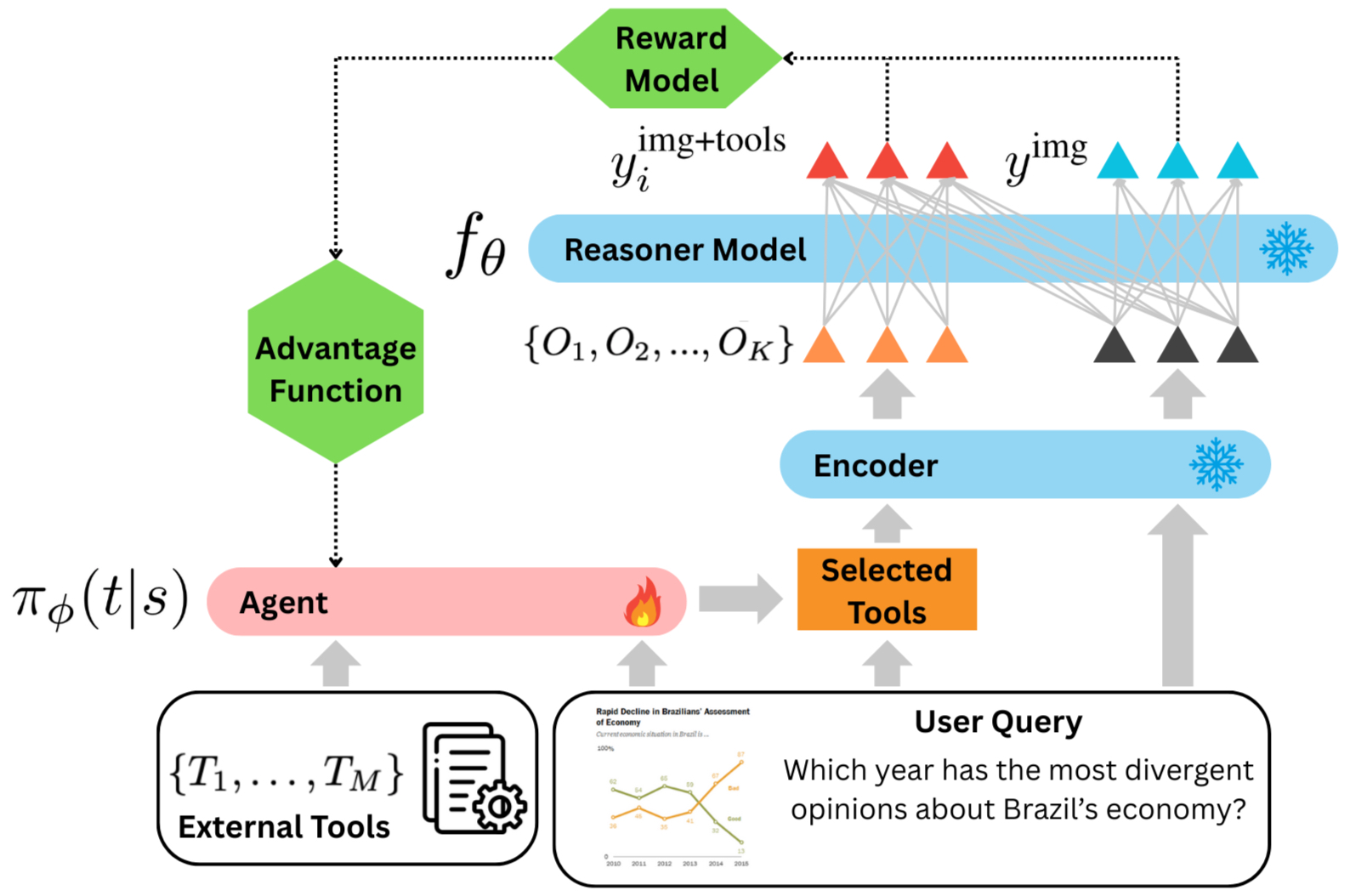
Figure 2: Policy Optimization. Given a user query, the agent selects tools from a pre-defined set of external tools. The tools are applied to the image, and their outputs and the query are fed to a frozen reasoner model. Both the Direct Path (query + image) and the Tool-Augmented Path (query + tools + image) are evaluated to compute a reward signal, which is used to update the agent's tool-selection policy.
Given a visual-language query (q,I), the agent observes this input and learns a policy πϕ(t∣s) that dictates the selection of a sequence of tools for that particular query. The reward structure is designed to encourage tool selections that improve reasoning model outcomes, while penalizing selections that detract from performance.
Experimental Results
VisTA demonstrates substantial performance improvements over baseline methods on benchmarks like ChartQA and Geometry3K. The RL-based approach significantly advances the ability of models to generalize across out-of-distribution examples, thereby enhancing adaptive tool utilization.

Figure 3: Comparison of ChartQA accuracy across individual tools (T0–T8), the no-tool baseline (No), our RL-based selection policy (Ours), and a pseudo-upper bound (Upper).
Figure 3 illustrates the efficacy of VisTA's selection strategy, outperforming individual tool performance and narrowing the gap towards a pseudo-upper bound.
The VisTA framework highlights a novel potential for dynamic tool selection, suited to the varying complexities of visual reasoning tasks.
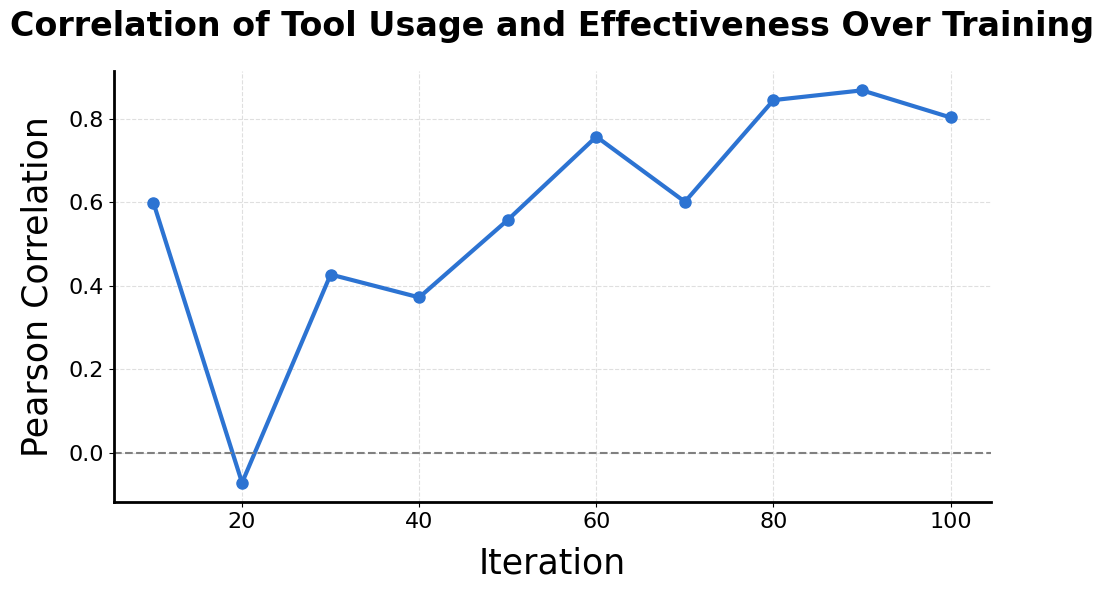
Figure 4: Pearson correlation between tool usage frequency and individual tool performance.
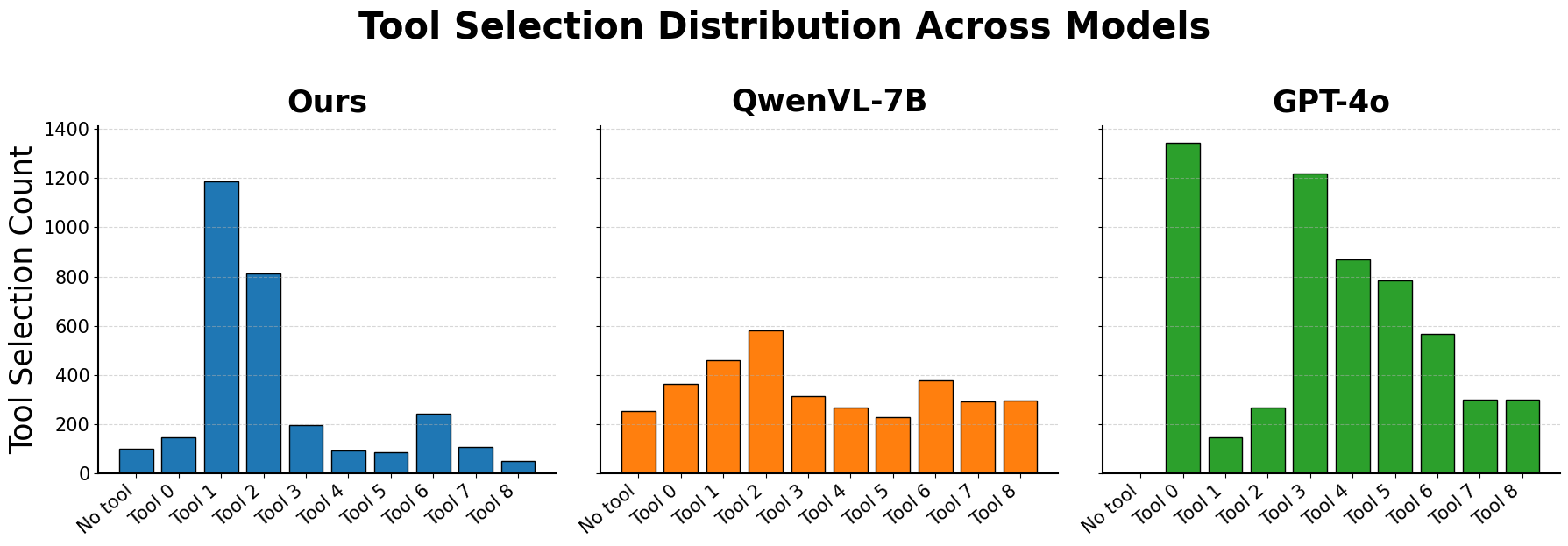
Figure 5: Tool selection frequency across our RL-trained agent, QwenVL-7B, and GPT-4o. Our method strongly favors effective tools (Tools 1 and 2) and avoids less useful ones, while QwenVL-7B shows a uniform distribution and GPT-4o selects broadly without clear alignment to tool performance.
The analysis shows an increasing alignment of tool selection frequency with tool utility, indicating effective optimization by the RL agent, as depicted in Figures 5 and 6.
Conclusion
The VisTA framework presents a novel approach for enhancing visual reasoning by dynamically and autonomously selecting tools through reinforcement learning. Its ability to generalize across challenges and improve reasoning performance without necessitating retraining of the underlying reasoning models places VisTA as a promising direction for future research and applications in AI. The implications of this research are crucial for the development of adaptive, modular reasoning systems capable of handling complex, real-world visual tasks.