- The paper presents the W2SR paradigm, where strong student LLMs learn structured reasoning from weak teacher-generated chain-of-thought traces.
- It shows that even imperfect reasoning traces can yield up to 94% of RL performance gains, emphasizing structured reasoning over teacher scale.
- The approach offers a scalable and cost-effective alternative, significantly reducing computational costs compared to traditional reinforcement learning.
Incentivizing Strong Reasoning from Weak Supervision
Introduction
The research presented in "Incentivizing Strong Reasoning from Weak Supervision" addresses the challenge of effectively enhancing the reasoning capacities of LLMs without reliance on expensive high-quality demonstrations or reinforcement learning (RL). Traditional methods, such as RL with verifiable signals or supervised fine-tuning (SFT) with high-quality chain-of-thought (CoT) demonstrations, are resource-intensive, requiring significant computational power and data engineering, thereby limiting accessibility and scalability. This paper explores an alternative, cost-effective approach leveraging supervision from significantly weaker models to incentivize reasoning in stronger models.
Weak-to-Strong Reasoning Paradigm
The core innovation introduced is the Weak-to-Strong Reasoning (W2SR) paradigm, where a "strong" student model learns through supervision on reasoning traces generated by "weak" teacher models. In this paradigm, even considerably smaller and less accurate teachers provide useful and structured CoT reasoning traces. These traces, despite their potential inaccuracies, help in eliciting and amplifying the reasoning capabilities of stronger students.
The student model is fine-tuned via SFT using reasoning trajectories generated by the weaker teacher models. The principle is that these traces, though imperfect, are informative enough to unlock latent reasoning potential in students. The W2SR paradigm is tested against various baselines, demonstrating that it recovers a substantial portion of reasoning gains traditionally achieved through costly RL.
Experimental Setup
Datasets and Models
Experiments are conducted on diverse reasoning benchmarks including MATH, OlympiadBench, MinervaMath, AMC2023, and GPQA, ensuring a comprehensive evaluation across different reasoning tasks. The student models belong to the Qwen-2.5 series (ranging from 7B to 32B parameters), whereas the teachers are considerably weaker, ranging from 0.5B to 14B parameters.
Training and Evaluation
The training employs full-parameter fine-tuning with a consistent setup across various model scales. Evaluations measure performance through Pass@1 metrics and Reasoning Gap Recovered (RGR), quantifying the efficacy of weak-to-strong transfers compared to traditional RL.
Results and Analysis
Effectiveness of Weak Supervision
The W2SR paradigm shows that weak supervision can significantly enhance reasoning capabilities, achieving performance levels close to or even surpassing RL-trained models. For example, training a 7B student with a 1.5B reasoner recovers nearly 94% of the RL performance gain.
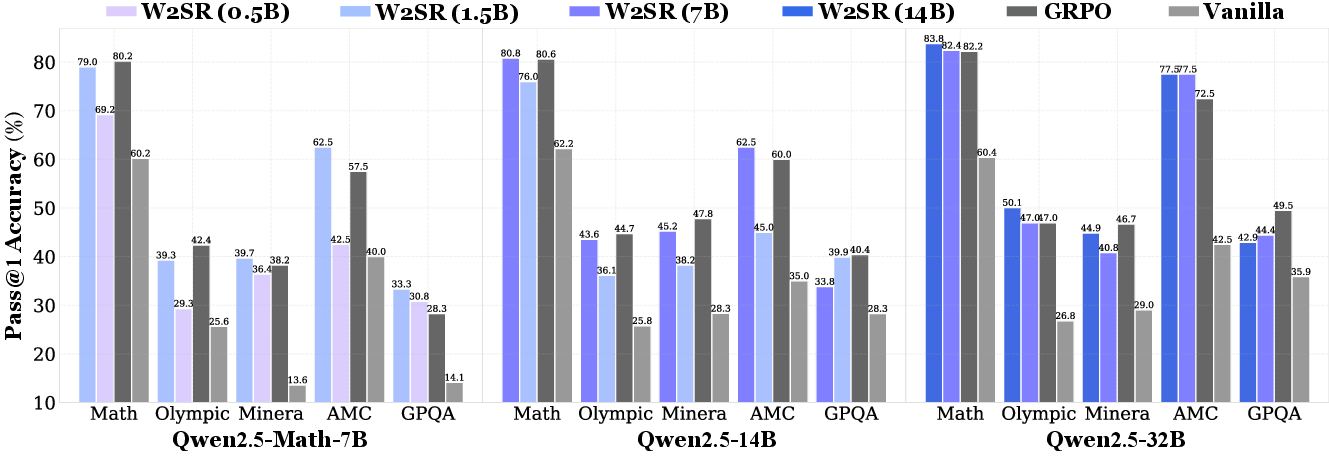
Figure 1: Benchmark performance of W2SR across student scales, demonstrating consistent strong reasoning with weak teachers across reasoning benchmarks.
Teacher Model Attributes
Experiments reveal that the reasoning capability—specifically the ability to generate structured CoT—is more critical than the scale or raw performance of the teacher model. Surprisingly, even reasoning traces that do not yield correct final answers can still provide significant learning value, indicating that the reasoning structure itself is a crucial component of effective learning.
Efficiency and Trade-Offs
W2SR presents a compelling efficiency advantage. Utilizing weaker teachers results in drastically reduced computational costs without a significant compromise in reasoning performance. This cost-effectiveness is evident when compared to the computational demands of RL approaches, making W2SR a practical alternative for incentivizing reasoning capabilities at scale.
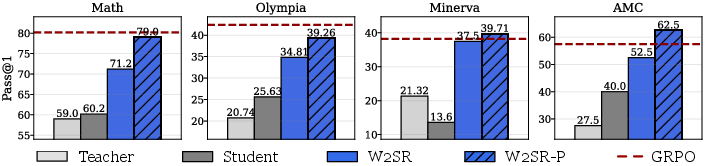
Figure 2: Efficiency and performance comparison among GRPO, W2SR, and W2SR-P, highlighting substantial gains in training efficiency and performance using weaker teachers.
Conclusion
The "Incentivizing Strong Reasoning from Weak Supervision" study illustrates a scalable, cost-effective alternative for enhancing LLM reasoning capabilities by utilizing weak-to-strong transfers. The results position W2SR as a promising approach for facilitating strong reasoning in LLMs outside the constraints of traditional, resource-heavy methods. Future research directions may include optimizing selection processes of weak supervision signals, extending the framework to multi-modal contexts, and refining theoretical foundations to further enhance weak-to-strong learning paradigms.