- The paper reveals that LLMs internally decompose complex tasks into sequential subtasks learned at distinct network depths.
- It employs layer-from context masking, cross-task patching, and LogitLens decoding to validate the sequential execution of subtasks.
- The findings enhance LLM transparency and suggest potential for precise control over instruction-level behavior in real-world applications.
Layer-Wise Subtask Scheduling in LLMs
This paper presents empirical evidence supporting the existence of an internal chain-of-thought (ICoT) within LLMs, wherein complex tasks are sequentially decomposed and executed layer by layer. The study posits two key claims: (i) distinct subtasks are learned at different network depths, and (ii) these subtasks are executed sequentially across layers. The authors employ layer-from context-masking and introduce a novel cross-task patching method to validate the first claim. To investigate the second claim, they utilize LogitLens to decode hidden states, revealing a consistent layer-wise execution pattern. The findings are further corroborated by replicating the analysis on the real-world TRACE benchmark.
Experimental Design and Claims
The authors analyze composite tasks, t:=s1∘s2, that decompose into two sequential subtasks. They frame their analysis within the Task Vector framework, where in-context learning (ICL) is divided into a learning phase and a rule application phase. This leads to two specific claims:
- Claim 1: Subtasks are learned at different network depths, inducing distinct subtask vectors θs1 and θs2 that generalize to their respective subtasks.
- Claim 2: Subtasks are executed sequentially across layers. At depth l1, the model applies fl1(x;θs1) to compute the first subtask. At a later depth l2, it applies fl2(x;θs2), yielding the final result.
The authors emphasize the distinction between "learning" and "execution," corresponding to the learning and application phases in the Task Vector framework, respectively.
Methodology and Results
To validate Claim 1, the authors employ two methods:
Layer-From Context Masking
This technique blocks attention to demonstrations after layer l, revealing where each subtask is learned. The results, visualized in an "X-shape" pattern (Figure 1), indicate a sequential learning dynamic: the model first abstracts the rule for s1 at an earlier layer and later learns s2 at a deeper layer.
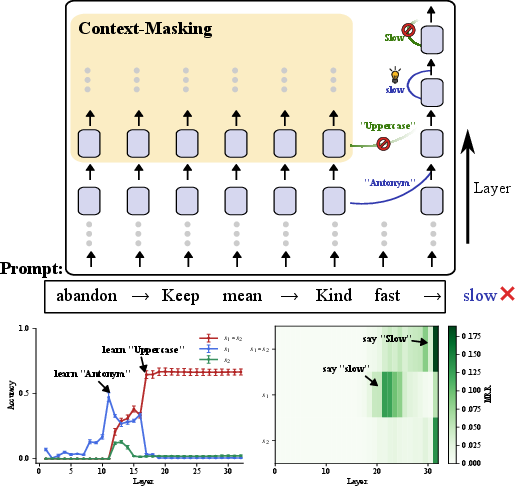
Figure 1: Evidence of an internal chain-of-thought. Selectively masking (bottom left) from specific layers can preserve the first subtask (antonym) while ablating the second (uppercase). Decoding hidden states (bottom right) on a clean run shows the intermediate answer (``slow'') peaks at middle layers.
Cross-Task Patching
This novel method inserts residual activations from a composite prompt into zero-shot subtask queries to detect reusable "subtask vectors." The results demonstrate that activations in Llama-3.1-8B yield transferable subtask vectors to a significant degree (66% on average).
To verify Claim 2, the authors decode every layer with LogitLens, projecting hidden states into token space and tracking the mean reciprocal rank of the first-step target (ys1 or ys2) versus the final answer (ys1∘s2). The decoding results show that the intermediate answer peaks in mid-layers and is then overtaken by the final answer.
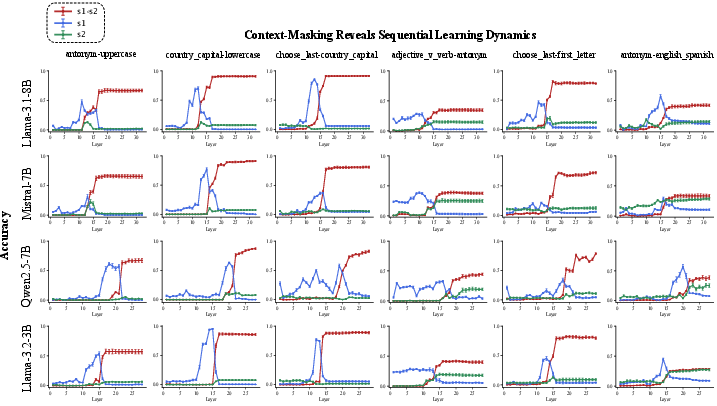
Figure 2: Masking results for six composite tasks across four models. The ``X-shape'' pattern reveals sequential learning dynamics.
Finally, the authors replicate layer-from context masking on TRACE, a complex instruction-following benchmark, demonstrating that the same sequential learning dynamics emerge in real-world settings.
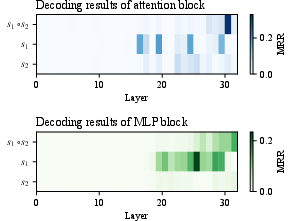
Figure 3: Heatmaps of attention and MLP block decoding results for the country_capital-lowercase task in Llama-3.1-8B.
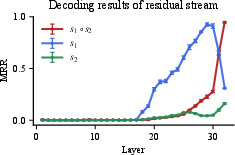
Figure 4: Decoding results of the residual stream for the country_capital-lowercase task in Llama-3.1-8B.
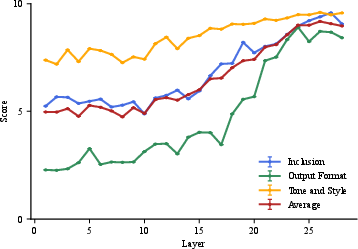
Figure 5: Layer-wise context-masking analysis on TRACE benchmark. Each curve shows model performance (scored 0â10) on a distinct constraint type, evaluated by DeepSeek-V3.
Implications and Future Directions
The findings enhance LLM transparency by revealing their capacity to internally plan and execute subtasks. This aligns with prior interpretability studies on multi-hop reasoning and look-ahead planning. The discovery of ICoT opens avenues for fine-grained, instruction-level behavior control. For instance, by identifying the layers responsible for processing specific instructions, interventions could be designed to steer their execution for safer LLM behavior.
The authors note that experiments are conducted on models ranging from 3B to 8B parameters, leaving open the question of whether observed phenomena generalize to larger frontier models. They also acknowledge that the "X-shape" pattern is facilitated by the design of benchmark tasks with clearly distinguishable subtask types. This separation likely leads to more temporally distant learning points for each subtask across layers.
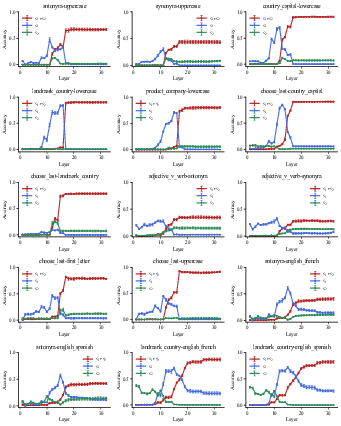
Figure 6: Layer-from context-masking results for all composite tasks in Llama-3.1-8B.
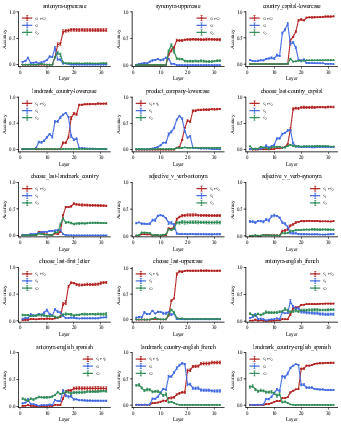
Figure 7: Layer-from context-masking results for all composite tasks in Mistral-7B.
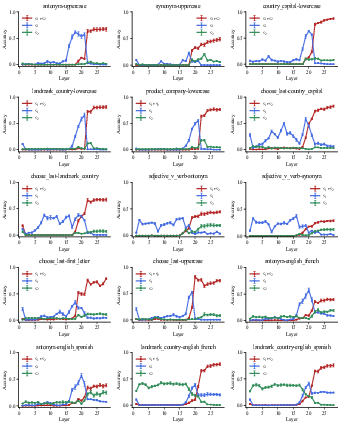
Figure 8: Layer-from context-masking results for all composite tasks in Qwen2.5-7B.
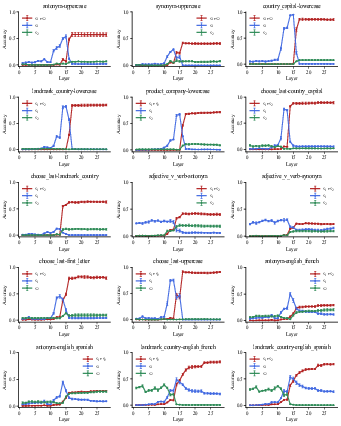
Figure 9: Layer-from context-masking results for all composite tasks in Llama-3.2-3B.
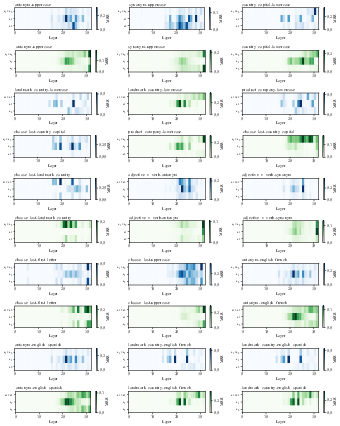
Figure 10: Heatmaps of attention and MLP block decoding results for all tasks in Llama-3.1-8B.
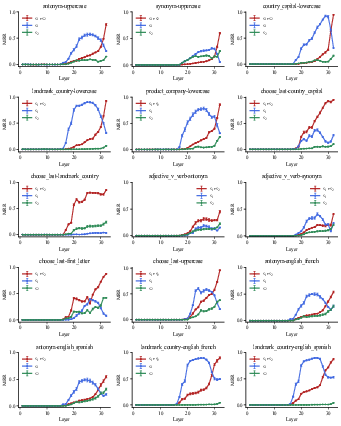
Figure 11: Decoding results of residual stream for all tasks in Llama-3.1-8B.
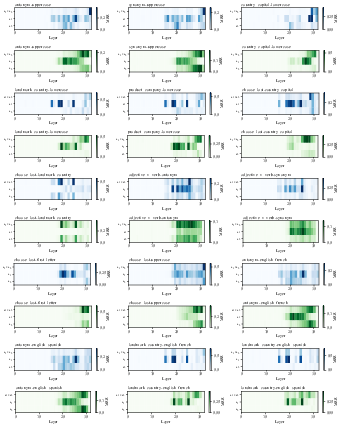
Figure 12: Heatmaps of attention and MLP block decoding results for all tasks in Mistral-7B.
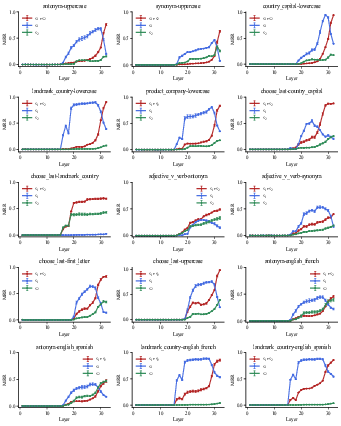
Figure 13: Decoding results of residual stream for all tasks in Mistral-7B.
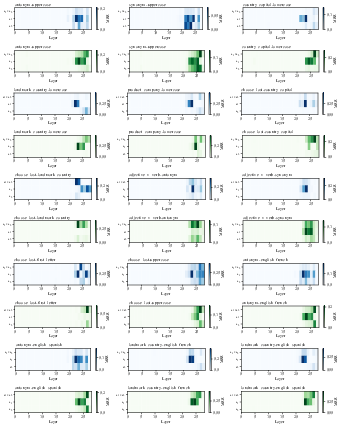
Figure 14: Heatmaps of attention and MLP block decoding results for all tasks in Qwen2.5-7B.
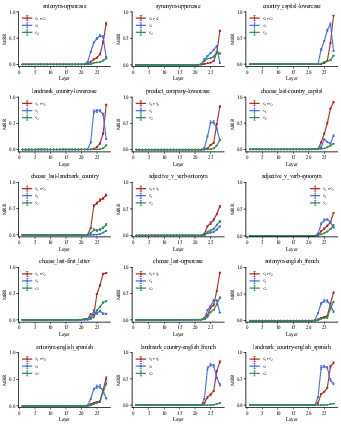
Figure 15: Decoding results of residual stream for all tasks in Qwen2.5-7B.
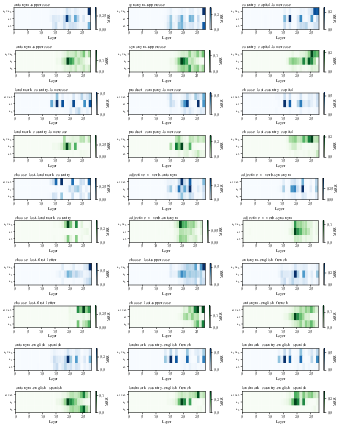
Figure 16: Heatmaps of attention and MLP block decoding results for all tasks in Llama-3.2-3B.
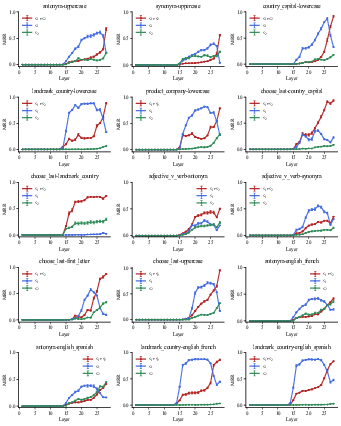
Figure 17: Decoding results of residual stream for all tasks in Llama-3.2-3B.
Conclusion
This study provides evidence for the presence of an internal chain-of-thought within LLMs. By employing context-masking, cross-task patching, and LogitLens decoding, the authors demonstrate that subtasks are learned at different network depths and executed sequentially across layers. These findings contribute to a deeper understanding of LLM transparency and open new possibilities for instruction-level behavior control.